Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:porown3grpl:nparpl
Spis treści
Non-parametric tests
The Kruskal-Wallis ANOVA
The Kruskal-Wallis one-way analysis of variance by ranks (Kruskal 1952 1); Kruskal and Wallis 1952 2)) is an extension of the U-Mann-Whitney test on more than two populations. This test is used to verify the hypothesis that there is no shift in the compared distributions, i.e., most often the insignificant differences between medians of the analysed variable in ( ) populations (but you need to assume, that the variable distributions are similar - comparison of rank variances can be checked using Conover's rank test).
) populations (but you need to assume, that the variable distributions are similar - comparison of rank variances can be checked using Conover's rank test).
Additional analyses:
- it is possible to test for a trend in the arrangement of the groups under study by performing the Jonckheere-Terpstra test for trend.
Basic assumptions:
- measurement on an ordinal scale or on an interval scale,
Hypotheses:

where:
 distributions of the analysed variable of each population.
distributions of the analysed variable of each population.
The test statistic is defined by:

where:
 ,
,
 – samples sizes
– samples sizes  ,
,
 – ranks ascribed to the values of a variable for
– ranks ascribed to the values of a variable for  , ,
, ,
 – correction for ties,
– correction for ties,
 – number of cases included in a tie.
– number of cases included in a tie.
The formula for the test statistic  includes the correction for ties
includes the correction for ties  . This correction is used, when ties occur (if there are no ties, the correction is not calculated, because of
. This correction is used, when ties occur (if there are no ties, the correction is not calculated, because of  ).
).
The statistic asymptotically (for large sample sizes) has the Chi-square distribution with the number of degrees of freedom calculated using the formula:  .
.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

The POST-HOC tests
Introduction to the contrasts and the POST-HOC tests was performed in the unit, which relates to the one-way analysis of variance.
For simple comparisons, equal-size groups as well as unequal-size groups.
The Dunn test (Dunn 19643)) includes a correction for tied ranks (Zar 20104)) and is a test corrected for multiple testing. The Bonferroni or Sidak correction is most commonly used here, although other, newer corrections are also available, described in more detail in Multiple comparisons.
Example - simple comparisons (comparing 2 selected median / mean ranks with each other):

- [i] The value of critical difference is calculated by using the following formula:

where:
 - is the critical value (statistic) of the normal distribution for a given significance level corrected on the number of possible simple comparisons
- is the critical value (statistic) of the normal distribution for a given significance level corrected on the number of possible simple comparisons  .
.
- [ii] The test statistic is defined by:

where:
 – mean of the ranks of the
– mean of the ranks of the  -th group, for ,
-th group, for ,
The formula for the test statistic  includes a correction for tied ranks. This correction is applied when tied ranks are present (when there are no tied ranks this correction is not calculated because
includes a correction for tied ranks. This correction is applied when tied ranks are present (when there are no tied ranks this correction is not calculated because  ).
).
The test statistic asymptotically (for large sample sizes) has the normal distribution, and the p-value is corrected on the number of possible simple comparisons .
The non-parametric equivalent of Fisher LSD5), used for simple comparisons of both groups of equal and different sizes.
- [i] The value of critical difference is calculated by using the following formula:

where:

 is the critical value (statistic) Snedecor's F distribution for a given significance level and for degrees of freedom respectively: 1 i
is the critical value (statistic) Snedecor's F distribution for a given significance level and for degrees of freedom respectively: 1 i  .
.
- [ii] The test statistic is defined by:

where:
– The mean ranks of the -th group, for ,
This statistic follows a t-Student distribution with degrees of freedom.
The settings window with the Kruskal-Wallis ANOVA can be opened in Statistics menu→NonParametric tests →Kruskal-Wallis ANOVA or in ''Wizard''.
A group of 120 people was interviewed, for whom the occupation is their first job obtained after receiving appropriate education. The respondents rated their job satisfaction on a five-point scale, where:
1- unsatisfying job,
2- job giving little satisfaction,
3- job giving an average level of satisfaction,
4- job that gives a fairly high level of satisfaction,
5- job that is very satisfying.
We will test whether the level of reported job satisfaction does not change for each category of education.
Hypotheses:


The obtained value of p=0.001 indicates a significant difference in the level of satisfaction between the compared categories of education. Dunn's POST-HOC analysis with Bonferroni's correction shows that significant differences are between those with primary and secondary education and those with primary and tertiary education. Slightly more differences can be confirmed by selecting the stronger POST-HOC Conover-Iman.
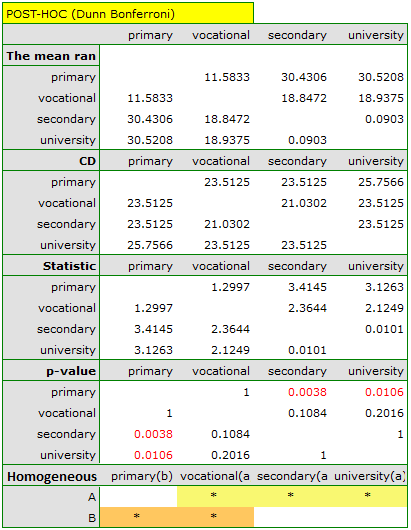
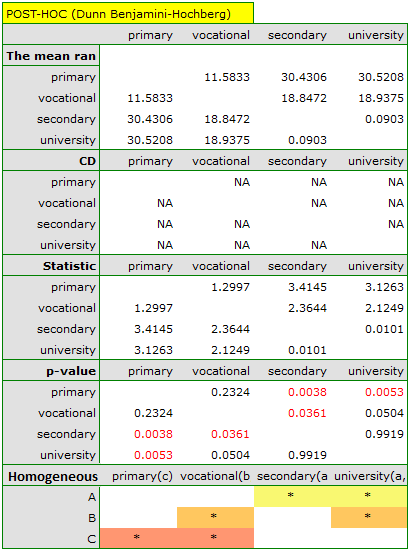
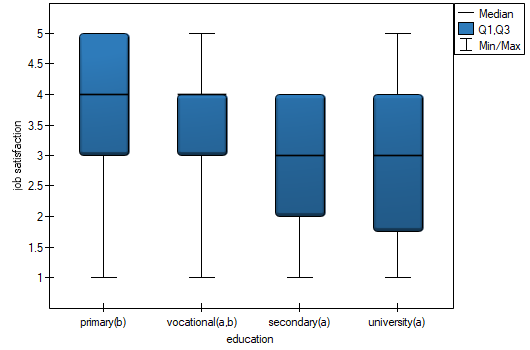
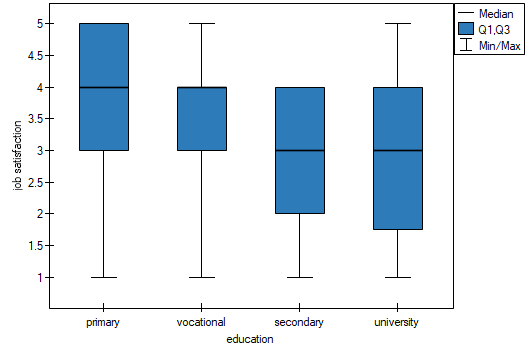
In the graph showing medians and quartiles we can see homogeneous groups determined by the POST-HOC test. If we choose to present Dunn's results with Bonferroni correction we can see two homogeneous groups that are not completely distinct, i.e. group (a) - people who rate job satisfaction lower and group (b)- people who rate job satisfaction higher. Vocational education belongs to both of these groups, which means that people with this education evaluate job satisfaction quite differently. The same description of homogeneous groups can be found in the results of the POST-HOC tests.
We can provide a detailed description of the data by selecting descriptive statistics in the analysis window 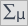 and indicating to add counts and percentages to the description.
and indicating to add counts and percentages to the description.
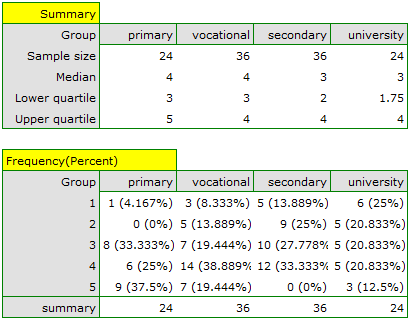
We can also show the distribution of responses in a column plot.
The Jonckheere-Terpstra test for trend
The Jonckheere-Terpstra test for ordered alternatives described independently by Jonckheere (1954) 6) an be calculated in the same situation as the Kruskal-Wallis ANOVA , as it is based on the same assumptions. The Jonckheere-Terpstra test, however, captures the alternative hypothesis differently - indicating in it the existence of a trend for successive populations.
Hypotheses are simplified to medians:

Note
The term: „with at least one strict inequality” written in the alternative hypothesis of this test means that at least the median of one population should be greater than the median of another population in the order specified.
The test statistic has the form:
![\begin{displaymath}
Z=\frac{L-\left[\frac{N^2-\sum_{j=1}^kn_j^2}{4}\right]}{SE}
\end{displaymath}](/lib/exe/fetch.php?media=wiki:latex:/img90c514ede7a37557872f285e3a796486.png "LaTeX")
where:
 – sum of
– sum of  values obtained for each pair of compared populations,
values obtained for each pair of compared populations,
– number of results higher than a preset value in the next occurring group,
 ,
,
 ,
,
 ,
,
 ,
,
 – number of groups of different tied ranks,
– number of groups of different tied ranks,
 – umber of cases included in the tied rank,
– umber of cases included in the tied rank,
,
– sample sizes for .
Note
To be able to perform a trend analysis, the expected order of the populations must be indicated by assigning consecutive natural numbers.
The formula for the test statistic includes the correction for ties. This correction is applied when tied ranks are present (when there are no tied ranks the test statistic formula reduces to the original Jonckheere-Terpstra formula without this correction).
The statistic has asymptotically (for large samples) normal distribution.
With the expected direction of the trend known, the alternative hypothesis is one-sided and the one-sided p-value is interpreted. The interpretation of the two-sided p-value means that the researcher does not know (does not assume) the direction of the possible trend.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The settings window with the Jonckheere-Terpstra test for trend can be opened in Statistics menu→NonParametric tests→Kruskal-Wallis ANOVA or in ''Wizard''.
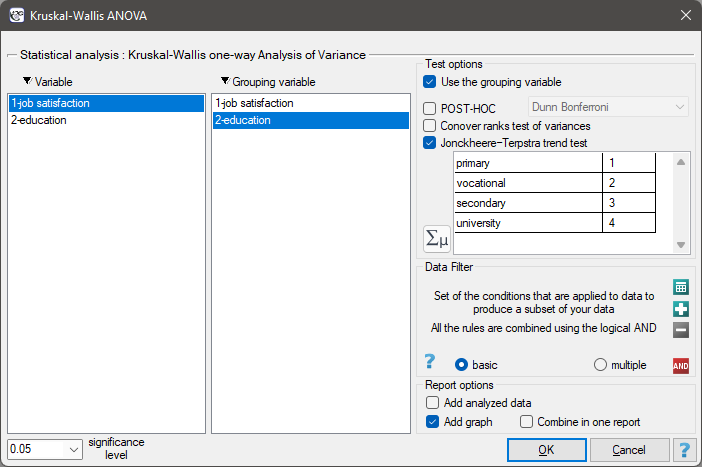
EXAMPLE cont. (jobSatisfaction.pqs file)
It is suspected that better educated people have high job demands, which may reduce the satisfaction level of the first job, which often does not meet such demands. Therefore, it is worthwhile to conduct a trend analysis.
Hypotheses:

To do this, we resume the analysis with the  button, select the
button, select the Jonckheere-Terpstra trend test option, and assign successive natural numbers to the education categories.
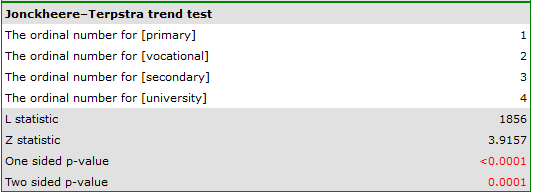
The obtained one-sided value p<0.0001 and is less than the set significance level  , which speaks in favor of a trend actually occurring consistent with the researcher's expectations.
, which speaks in favor of a trend actually occurring consistent with the researcher's expectations.
We can also confirm the existence of this trend by showing the percentage distribution of responses obtained.
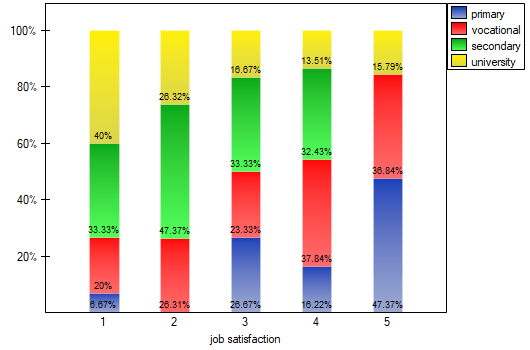
The Conover ranks test of variance
Conover squared ranks test is used, similarly to Fisher-Snedecor test (for  ), Levene test and Brown-Forsythe test (for
), Levene test and Brown-Forsythe test (for  ) to verify the hypothesis of similar variation of the tested variable in several populations. It is the non-parametric counterpart of the tests indicated above, by that it does not assume normality of the data distribution and is based on the ranks7).However, this test examines variation and therefore distances to the mean, so the basic condition for its use is:
) to verify the hypothesis of similar variation of the tested variable in several populations. It is the non-parametric counterpart of the tests indicated above, by that it does not assume normality of the data distribution and is based on the ranks7).However, this test examines variation and therefore distances to the mean, so the basic condition for its use is:
- measurement on an interval scale,
Hypotheses:

The test statistic has the form:

where:
 ,
,
– individual group sizes,
 –sum of ranks squares in -th group,
–sum of ranks squares in -th group,
 – mean of all ranks squares,
– mean of all ranks squares,
 ,
,
 – ranks for values representing the distance of the measurement from the mean of a given group.
– ranks for values representing the distance of the measurement from the mean of a given group.
This statistic has a Chi-squaredistribution with  degrees of freedom.
degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The settings window with the Conover ranks test of variance can be opened in Statistics menu→NonParametric tests→Kruskal-Wallis ANOVA, option Conover ranks test of variance or textsf{Statistics} menu→NonParametric tests→Mann-Whitney, option Conover ranks test of variance.
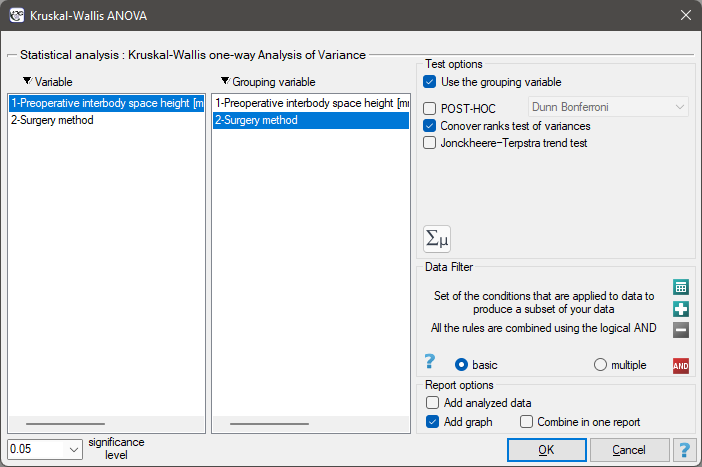
EXAMPLE(surgeryMethod.pqs file)
Patients have been prepared for spinal surgery. The patients will be operated on by one of three methods. Preliminary allocation of each patient to each type of surgery has been made. At a later stage we intend to compare the condition of the patients after the surgeries, therefore we want the groups of patients to be comparable. They should be similar in terms of the height of the interbody space (WPMT) before surgery. The similarity should concern not only the average values but also the differentiation of the groups.
The distribution of the data was checked
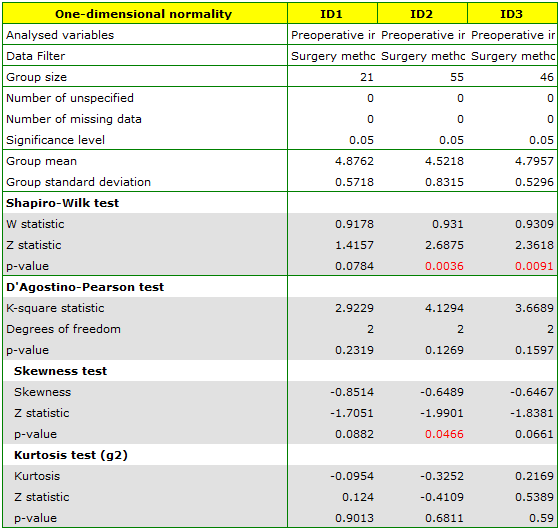
It is found that for the two methods, the WPMT operation exhibits deviations from normality, largely caused by skewness of the data. Further comparative analysis will be conducted using the Kruskal-Wallis test to compare whether the level of WPMT differs between the methods, and the Conover test to indicate whether the spread of WPMT scores is similar in each method.
Hypotheses for Conover's variance test:

Hypotheses for Kruskal-Wallis test:


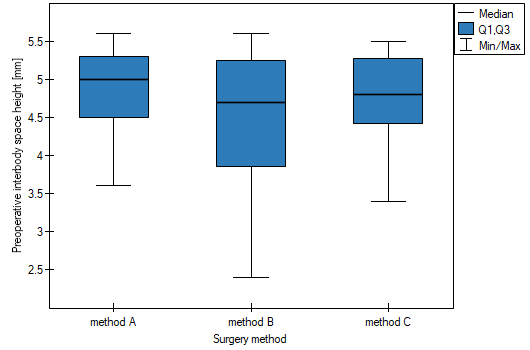
First, the value of Conover's test of variance is interpreted, which indicates statistically significant differences in the ranges of the groups compared (p=0.0022). From the graph, we can conclude that the differences are mainly in group 3. Since differences in WPMT were detected, the interpretation of the result of the Kruskal-Wallis test comparing the level of WPMT for these methods should be cautious, since this test is sensitive to heterogeneity of variance. Although the Kruskal-Wallis test showed no significant differences (p=0.2057), it is recommended that patients with low WPMT (who were mainly assigned to surgery with method B) be more evenly distributed, i.e. to see if they could be offered surgery with method A or C. After reassignment of patients, the analysis should be repeated.
The Friedman ANOVA
The Friedman repeated measures analysis of variance by ranks – the Friedman ANOVA - was described by Friedman (1937)8). This test is used when the measurements of an analysed variable are made several times () each time in different conditions. It is also used when we have rankings coming from different sources (form different judges) and concerning a few () objects, but we want to assess the grade of the rankings agreement.
Iman Davenport (19809)) has shown that in many cases the Friedman statistic is overly conservative and has made some modification to it. This modification is the non-parametric equivalent of the ANOVA for dependent groups which makes it now recommended for use in place of the traditional Friedman statistic.
Additional analyses:
- It is possible to take missing data into account by using the Accept missing data option, calculating Durbin ANOVA or Skillings-Mack ANOVA;
- it is possible to test the trend in the arrangement of the studied groups by performing Page test for trend.
Basic assumptions:
- measurement on an ordinal scale or on an interval scale,
Hypotheses relate to the equality of the sum of ranks for successive measurements ( ) or are simplified to medians (
) or are simplified to medians ( )
)

where:
 medians for an analysed features, in the following measurements from the examined population.
medians for an analysed features, in the following measurements from the examined population.
Two test statistics are determined: the Friedman statistic and the Iman-Davenport modification of this statistic.
The Friedman statistic has the form:

where:
 – sample size,
– sample size,
– ranks ascribed to the following measurements , separately for the analysed objects  ,
,
 – correction for ties,
– correction for ties,
– number of cases included in a tie.
The Iman-Davenport modification of the Friedman statistic has the form:

The formula for the test statistic  and
and  includes the correction for ties . This correction is used, when ties occur (if there are no ties, the correction is not calculated, because of ).
includes the correction for ties . This correction is used, when ties occur (if there are no ties, the correction is not calculated, because of ).
The statistic has asymptotically (for large sample sizes) has the Chi-square distribution with  degrees of freedom.
degrees of freedom.
The statistic follows the Snedecor's F distribution with  i
i  degrees of freedem.
degrees of freedem.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The POST-HOC tests
Introduction to the contrasts and the POST-HOC tests was performed in the unit, which relates to the one-way analysis of variance.
For simple comparisons (frequency in particular measurements is always the same).
The Dunn test (Dunn 196410)) is a corrected test due to multiple testing. The Bonferroni or Sidak correction is most commonly used here, although other, newer corrections are also available and are described in more detail in the Multiple Comparisons section.
Hypotheses:
Example - simple comparisons (comparison of 2 selected medians):
- [i] The value of critical difference is calculated by using the following formula:

where:
- is the critical value (statistic) of the normal distribution for a given significance level corrected on the number of possible simple comparisons .
- [ii] The test statistic is defined by:

where:
– mean of the ranks of the -th measurement, for ,
The test statistic asymptotically (for large sample size) has normal distribution, and the p-value is corrected on the number of possible simple comparisons .
Non-parametric equivalent of Fisher LSD11), sed for simple comparisons (counts across measurements are always the same).
- [i] he value of critical difference is calculated by using the following formula:

where:
 – sum of squares for ranks,
– sum of squares for ranks,
 to critical value (statistic) Snedecor's F distribution for a given significance level and for degrees of freedom respectively: 1 and
to critical value (statistic) Snedecor's F distribution for a given significance level and for degrees of freedom respectively: 1 and  .
.
- [ii] The test statistic is defined by:

where:
 – the sum of ranks of th measurement, for ,
– the sum of ranks of th measurement, for ,
The test statistic hast-Student distribution with degrees of freedem.
The settings window with the Friedman ANOVA can be opened in Statistics menu→NonParametric tests →Friedman ANOVA, trend test or in ''Wizard''
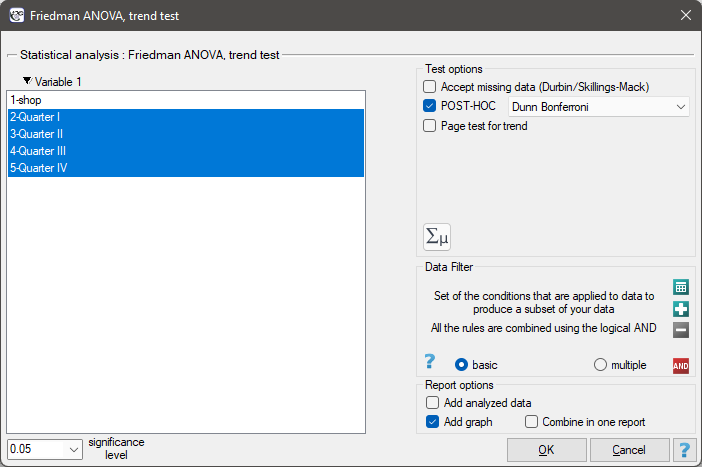
EXAMPLE (chocolate bar.pqs file)
Quarterly sale of some chocolate bar was measured in 14 randomly chosen supermarkets. The study was started in January and finished in December. During the second quarter, the billboard campaign was in full swing. Let's check if the campaign had an influence on the advertised chocolate bar sale.

Hypotheses:


Comparing the p-value of the Friedman test (as well as the p-value of the Iman-Davenport correction of the Friedman test) with a significance level , we find that sales of the bar are not the same in each quarter. The POST-HOC Dunn analysis performed with the Bonferroni correction indicates differences in sales volumes pertaining to quarters I and III and I and IV, and an analogous analysis performed with the stronger Conover-Iman test indicates differences between all quarters except quarters III and IV.
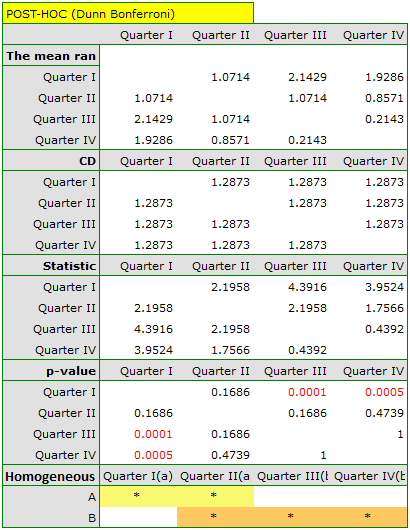
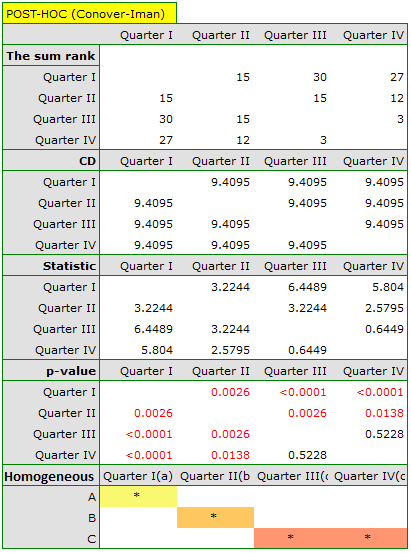
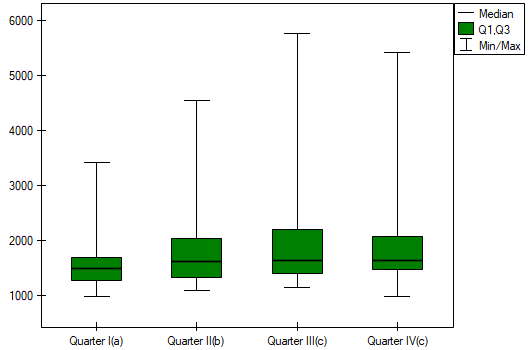
In the graph, we presented homogeneous groups determined by the Conover-Iman test.
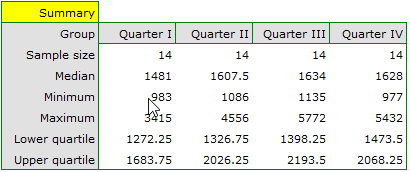
We can provide a detailed description of the data by selecting Descriptive statistics in the analysis window .
If the data were described by an ordinal scale with few categories, it would be useful to present it also in numbers and percentages. In our example, this would not be a good method of description.
The Page test for trend
The Page test for ordered alternative described in 1963 by Page E. B. 12) can be computed in the same situation as Friedman's ANOVA, since it is based on the same assumptions. However, Page's test captures the alternative hypothesis differently - indicating that there is a trend in subsequent measurements.
Hypotheses involve equality of the sum of ranks for successive measurements or are simplified to medians:
Note
The term: „with at least one strict inequality” written in the alternative hypothesis of this test means that at least one median should be greater than the median of another group of measurements in the order specified.
The test statistic has the form:
![\begin{displaymath}
Z=\frac{L-\left[\frac{nk(k+1)^2}{4}\right]}{\sqrt{\frac{n(k^3-k)^2}{144(k-1)}}}
\end{displaymath}](/lib/exe/fetch.php?media=wiki:latex:/imgd8f373e9725654f26c78c01931a87148.png "LaTeX")
where:
 ,
,
– the sum of ranks of th measurement,
 –the weight for -th measurement informing about the natural order of this measurement among other measurements (weights are consecutive natural numbers).
–the weight for -th measurement informing about the natural order of this measurement among other measurements (weights are consecutive natural numbers).
Note
In order to perform a trend analysis, the expected ordering of measurements must be indicated by assigning consecutive natural numbers to successive measurement groups. These numbers are treated as weights in the analysis  ,
,  , …,
, …,  .
.
The formula for the test statistic does not include a correction for ties, making it somewhat more conservative when tied ranks are present. However, using a correction for tied ranks for this test is not recommended.
The statistic has asymptotically (for large sample) normal distribution.
With the expected direction of the trend known, the alternative hypothesis is one-sided and the one-sided p-value is interpreted. Interpreting a two-sided p-value means that the researcher does not know (does not assume) the direction of the possible trend.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The settings window with the Page test for trend can be opened in Statistics menu→NonParametric tests →Friedman ANOVA, trend test or in ''Wizard''
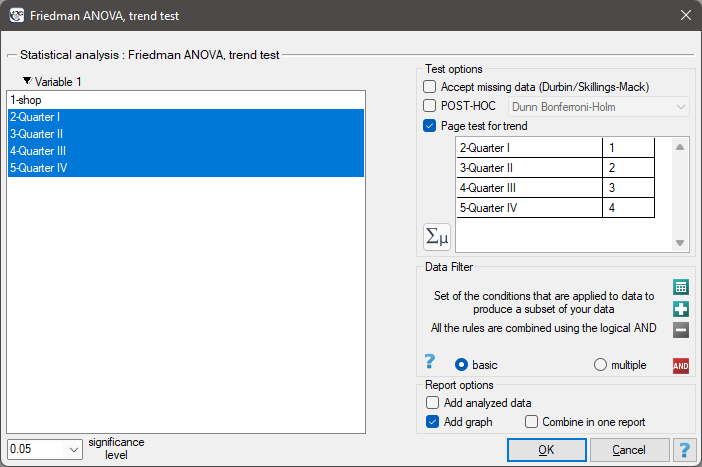
EXAMPLE cont. (chocolate bar.pqs file)
The expected result of the intensive advertising campaign conducted by the company is a steady increase in sales of the offered bar.
Hypotheses:

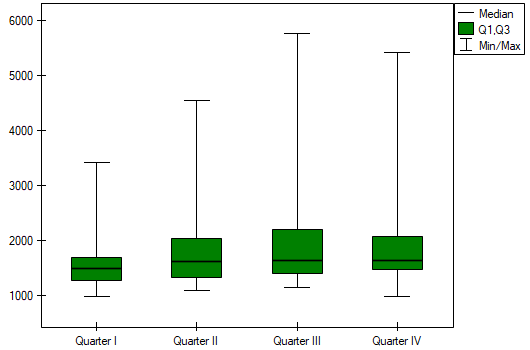
Comparing a one-sided p<0.0001 with a significance level , we find that the campaign produced the expected trend of increased product sales.
The Durbin's ANOVA (missing data)
Durbin's analysis of variance of repeated measurements for ranks was proposed by Durbin (1951)13). This test is used when measurements of the variable under study are made several times – a similar situation in which Friedman'sANOVA is used. The original Durbin test and the Friedman test give the same result when we have a complete data set. However, Durbin's test has an advantage – it can also be calculated for an incomplete data set. At the same time, data deficiencies cannot be located arbitrarily, but the data must form a so-called balanced and incomplete block:
- the number of measurements for each object is
 (
( ),
), - each measurement is made on
 objects (
objects ( ),
), - the number of objects for which the same pair of measurements was taken simultaneously is constant and equal to
 .
.
where:
– total number of considered measurements,
 – total number of examined objects.
– total number of examined objects.
Basic assumptions:
- measurement on an ordinal scale or on an interval scale,
Hypotheses involve equality of the sum of ranks for successive measurements () or are simplified to medians ():
Two test statistics of the following form are determined:
![\begin{displaymath}
T_1=\frac{(t-1)\left[\sum_{j=1}^tR_j^2-tC\right]}{A-C},
\end{displaymath}](/lib/exe/fetch.php?media=wiki:latex:/img6263bdbeddade6aabd733985ed7a7916.png "LaTeX")

where:
– sum of ranks for successive measurements  ,
,
– ranks assigned to successive measurements, separately for each of the studied objects  ,
,
 – sum of squared ranks,
– sum of squared ranks,
 – correction coefficient.
– correction coefficient.
The formula for and statistics includes a correction for tied ranks.
For complete data, the statistic is the same as the Friedman test. It has asymptotically (for large sample sizes) Chi-square distribution with  degrees of freedom.
degrees of freedom.
The statistic is the equivalent of Friedman's Iman-Davenport ANOVA adjustment, so it follows Snedecor's F distribution with  i
i  degrees of freedom. It is now considered to be more precise than the statistic and is recommended for use with the statistic14).
degrees of freedom. It is now considered to be more precise than the statistic and is recommended for use with the statistic14).
The p-value, designated on the basis of the test statistic, is compared with the significance level :
Testy POST-HOC
Introduction to the contrasts and the POST-HOC tests was performed in the unit, which relates to the one-way analysis of variance.
Used for simple comparisons (the counts in each measurement are always the same).
Hypotheses:
Example - simple comparisons (comparing 2 selected medians / rank sums between each other):
- [ii] The value of critical difference is calculated by using the following formula:

where:
 – is the [wartosc_krytyczna|critical value (statistic) of the t-Student distribution for a given significance level and
– is the [wartosc_krytyczna|critical value (statistic) of the t-Student distribution for a given significance level and  degrees of freedom.
degrees of freedom.
- [ii] The test statistic has the form:

The test statistic has t-Student distribution with degrees of freedom.
The settings window with the Durbin's ANOVA can be opened in Statistics menu→NonParametric tests →Friedman ANOVA, trend test or in ''Wizard''
Note
For records with missing data to be taken into account, you must check the Accept missing data option. Empty cells and cells with non-numeric values are treated as missing data. Only records with more than one numeric value will be analyzed.
An experiment was conducted among 20 patients in a psychiatric hospital (Ogilvie 1965)15). This experiment involved drawing straight lines according to a presented pattern. The pattern represented 5 lines drawn at different angles ( ) relative to the indicated center. The patients' task was to reproduce the lines while having their hand covered. The time at which the patient drew the line was recorded as the result of the experiment. Ideally, each patient would draw a line from all angles, but elapsed time and fatigue would have a significant impact on performance. In addition, it is difficult to keep the patient interested and willing to cooperate for an extended period of time. Therefore, the project was planned and conducted in balanced and incomplete blocks. Each of the 20 patients traced a line at two angles (there were five possible angles). Thus, each angle was drawn eight times. The time at which each patient drew a line at a given angle was recorded in the table.
) relative to the indicated center. The patients' task was to reproduce the lines while having their hand covered. The time at which the patient drew the line was recorded as the result of the experiment. Ideally, each patient would draw a line from all angles, but elapsed time and fatigue would have a significant impact on performance. In addition, it is difficult to keep the patient interested and willing to cooperate for an extended period of time. Therefore, the project was planned and conducted in balanced and incomplete blocks. Each of the 20 patients traced a line at two angles (there were five possible angles). Thus, each angle was drawn eight times. The time at which each patient drew a line at a given angle was recorded in the table.

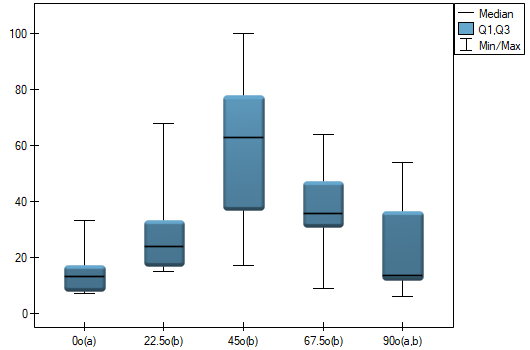
We want to see if the time taken to draw each line is completely random, or if there are lines that took more or less time to draw.
Hypotheses:

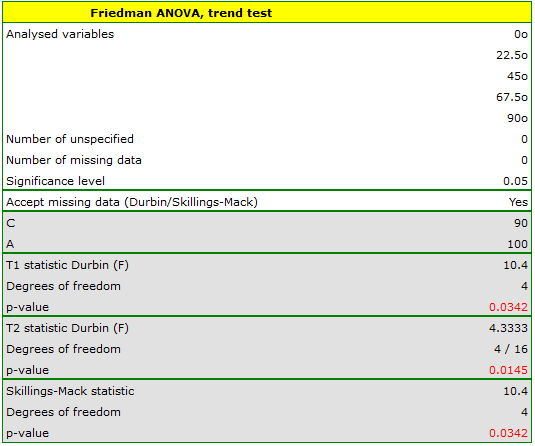
Comparing the p=0.0145 for the statistic (or the p=0.0342 for the statistic) with the significance level, we find that the lines are not drawn at the same time. The POST-HOC analysis performed indicates that there is a difference in the time taken to draw the line at angle  . It is drawn faster than the lines at the angle of
. It is drawn faster than the lines at the angle of  ,
,  and
and  .
.
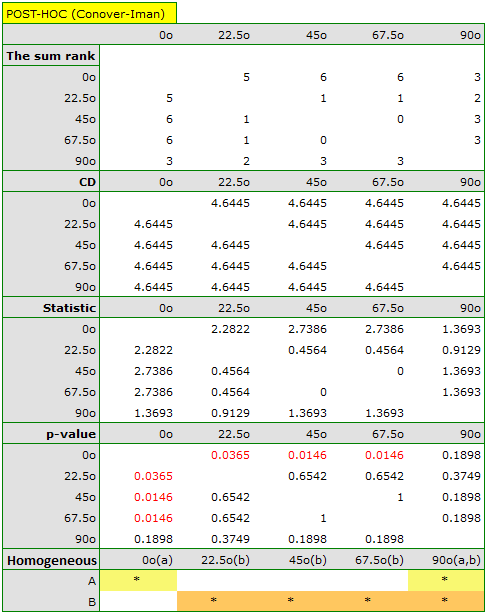
The graph shows homogeneous groups indicated by the post-hoc test.
The Skillings-Mack ANOVA (missing data)
The analysis of variance of repeated measures for Skillings-Mack ranks was proposed by Skillings and Mack in 1981 16). t is a test that can be used when there are missing data, but the missing data need not occur in any particular setting. However, each site must have at least two observations. If there are no tied ranks and no gaps are present it is the same as the Friedman's ANOVA, and if data gaps are present in a balanced arrangement it corresponds to the results of Durbin's ANOVA.
Basic assumptions: Basic assumptions:
- measurement on an ordinal scale or on an interval scale,
Hypotheses relate to the equality of the sum of ranks for successive measurements () or are simplified to medians ( )
)

The test statistic has the form:

where:

 ,
,
 – number of observations for
– number of observations for  -th object,
-th object,
– ranks assigned to successive measurements ( ), separately for each study object (
), separately for each study object ( ), with ranks for missing data equal to the average rank for the object,
), with ranks for missing data equal to the average rank for the object,
 – matrix determining the covariances for
– matrix determining the covariances for  at the truth of
at the truth of  17).
17).
When each pair of measurements occurs simultaneously for at least one observation, this statistic has asymptotically (for large sample sizes) the Chi-square distribution with degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The settings window with the Skillings-Mack ANOVA can be opened in Statistics menu→NonParametric tests →Friedman ANOVA, trend test or in ''Wizard''
Note
For records with missing data to be taken into account, you must check the Accept missing data option. Empty cells and cells with non-numeric values are treated as missing data. Only records containing more than one numeric value will be analyzed.
A certain university teacher, wanting to improve the way he conducted his classes, decided to verify his teaching skills. In several randomly selected student groups, during the last class, he asked them to fill in a short anonymous questionnaire. The survey consisted of six questions about how the six specified parts of the material were illustrated. The students could rate it on a 5-point scale, where 1 - the way of presenting the material was completely incomprehensible, 5 - a very clear and interesting way of illustrating the material. The data obtained in this way turned out to be incomplete due to the fact that students did not answer questions about the part of the material they were absent on. In the 30-person group completing the survey, only 15 students provided complete responses. Performing an analysis that does not account for data gaps (in this case, a Friedman analysis) will have limited power by cutting the group size so drastically and will not lead to the detection of significant differences. Data gaps were not planned for and are not present in the balanced block, so this task cannot be performed using Durbin's analysis along with his POST-HOC test.
Hypotheses:

The results of the ANOVA Skillings-Mack analysis are presented in the following report:
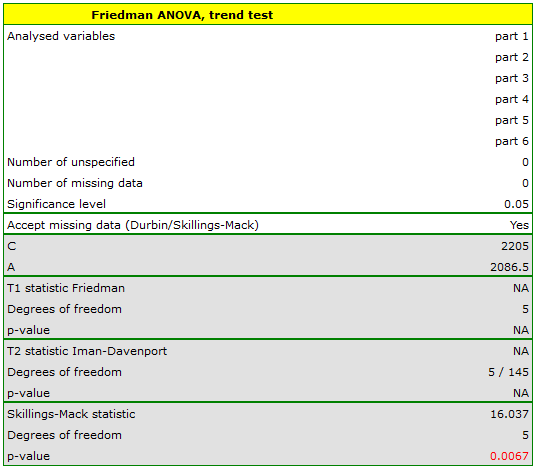
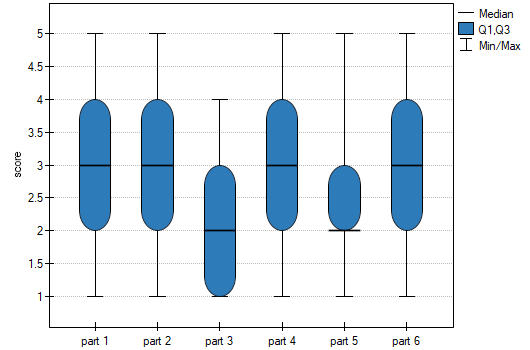
The  value obtained should be treated with caution due to possible tied ranks. However, for this study, the p=0.0067 is well below the accepted significance level of , indicating that significant differences exist. The differences in responses can be observed in the graph; however, there is no POST-HOC analysis available for this test.
value obtained should be treated with caution due to possible tied ranks. However, for this study, the p=0.0067 is well below the accepted significance level of , indicating that significant differences exist. The differences in responses can be observed in the graph; however, there is no POST-HOC analysis available for this test.
The Chi-square test for multidimensional contingency tables
Basic assumptions:
- measurement on a nominal scale - any order is not taken into account,
Hypotheses:

where:
 and
and 
 observed frequencies in a contingency table and the corresponding expected frequencies.
observed frequencies in a contingency table and the corresponding expected frequencies.
The test statistic is defined by:

This statistic asymptotically (for large expected frequencies) has the Chi-square distribution with a number of degrees of freedom calculated using the formula:  - for 3-dimensional tables.
- for 3-dimensional tables.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The settings window with the Chi-square (multidimensional) test can be opened in Statistics menu → NonParametric tests (unordered categories)→Chi-square (multidimensional) or in ''Wizard''.
Note
This test can be calculated only on the basis of raw data.
The Q-Cochran ANOVA
The Q-Cochran analysis of variance, based on the Q-Cochran test, is described by Cochran (1950)19). This test is an extended McNemar test for dependent groups. It is used in hypothesis verification about symmetry between several measurements  for the
for the  feature. The analysed feature can have only 2 values - for the analysis, there are ascribed to them the numbers: 1 and 0.
feature. The analysed feature can have only 2 values - for the analysis, there are ascribed to them the numbers: 1 and 0.
Basic assumptions:
- measurement on a nominal scale (dichotomous variables – it means the variables of two categories),
Hypotheses:

where:
„incompatible” observed frequencies – the observed frequencies calculated when the value of the analysed feature is different in several measurements.
The test statistic is defined by:

where:
 ,
,
 ,
,
 ,
,
 – the value of -th measurement for -th object (so 0 or 1).
– the value of -th measurement for -th object (so 0 or 1).
This statistic asymptotically (for large sample size) has the Chi-square distribution with a number of degrees of freedom calculated using the formula:  .
.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The POST-HOC tests
Introduction to the contrasts and the POST-HOC tests was performed in the unit, which relates to the one-way analysis of variance.
For simple comparisons (frequency in particular measurements is always the same).
Hypotheses:
Example - simple comparisons (for the difference in proportion in a one chosen pair of measurements):

- [i] The value of critical difference is calculated by using the following formula:

where:
- is the critical value (statistic) of the normal distribution for a given significance level corrected on the number of possible simple comparisons .
</WRAP
- [ii] The test statistic is defined by:

where:
 – the proportion -th measurement ,
– the proportion -th measurement ,
The test statistic asymptotically (for large sample size) has the normal distribution, and the p-value is corrected on the number of possible simple comparisons .
The settings window with the Cochran Q ANOVA can be opened in Statistics menu→ NonParametric tests→Cochran Q ANOVA or in ''Wizard''.
Note
This test can be calculated only on the basis of raw data.
We want to compare the difficulty of 3 test questions. To do this, we select a sample of 20 people from the analysed population. Every person from the sample answers 3 test questions. Next, we check the correctness of answers (an answer can be correct or wrong). In the table, there are following scores:

Hypotheses:

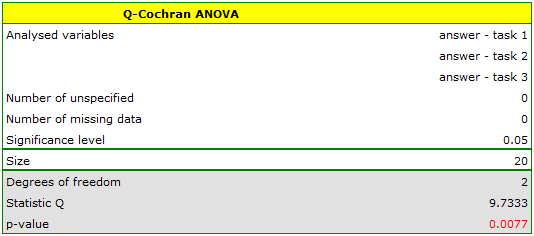
Comparing the p value p=0.0077 with the significance level we conclude that individual test questions have different difficulty levels. We resume the analysis to perform POST-HOC test by clicking , and in the test option window, we select POST-HOC Dunn.
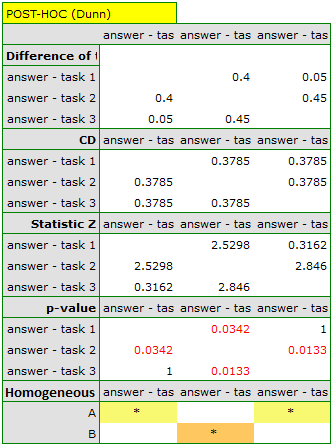
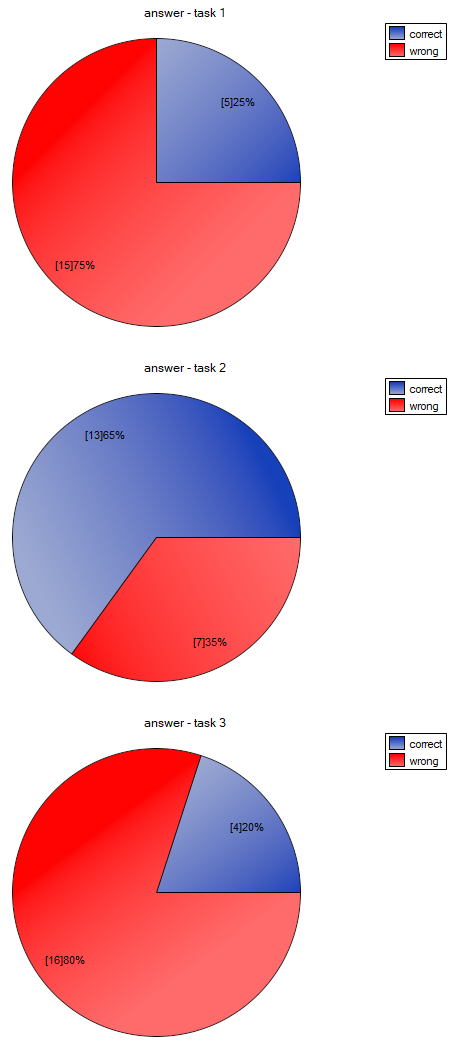
The carried out POST-HOC analysis indicates that there are differences between the 2-nd and 1-st question and between questions 2-nd and 3-th. The difference is because the second question is easier than the first and the third ones (the number of correct answers the first question is higher).
1)
Kruskal W.H., Wallis W.A. (1952), Use of ranks in one-criterion variance analysis. Journal of the American Statistical Association, 47, 583-621
4)
Zar J. H., (2010), Biostatistical Analysis (Fifth Editon). Pearson Educational
5)
, 7)
, 11)
, 13)
Conover W. J. (1999), Practical nonparametric statistics (3rd ed). John Wiley and Sons, New York
6)
Jonckheere A. R. (1954), A distribution-free k-sample test against ordered alternatives. Biometrika, 41: 133–145) and Terpstra (1952)((Terpstra T. J. (1952), The asymptotic normality and consistency of Kendall's test against trend, when ties are present in one ranking. Indagationes Mathematicae, 14: 327–333
8)
Friedman M. (1937), The use of ranks to avoid the assumption of normality implicit in the analysis of variance. Journal of the American Statistical Association, 32,675-701
9)
Iman R. L., Davenport J. M. (1980), Approximations of the critical region of the friedman statistic, Communications in Statistics 9, 571–595
12)
Page E. B. (1963), Ordered hypotheses for multiple treatments: A significance test for linear ranks. Journal of the American Statistical Association 58 (301): 216–30
14)
Durbin J. (1951), Incomplete blocks in ranking experiments. British Journal of Statistical Psychology, 4: 85–90
15)
Ogilvie J. C. (1965), Paired comparison models with tests for interaction. Biometrics 21(3): 651-64
16)
, 17)
Skillings J.H., Mack G.A. (1981) On the use of a Friedman-type statistic in balanced and unbalanced block designs. Technometrics, 23:171–177
18)
Cochran W.G. (1952), The chi-square goodness-of-fit test. Annals of Mathematical Statistics, 23, 315-345
19)
Cochran W.G. (1950), The comparison ofpercentages in matched samples. Biometrika, 37, 256-266
en/statpqpl/porown3grpl/nparpl.txt · ostatnio zmienione: 2022/02/12 16:24 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
