Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:aopisowapl:tabliczpl:analizytbpl
Analyses for contingency tables
Analyses for the contingency tables can be computed from data collected in the contingency tables or directly i.e., from raw data. Whereby it is possible to transform the data from the contingency table to the raw form or vice versa.
EXAMPLE (sex-education.pqs file)
Consider a sample consisting of 34 individuals ( ). We examine 2 traits of these individuals (
). We examine 2 traits of these individuals ( =sex,
=sex,  =education). Gender appears in 2 categories (
=education). Gender appears in 2 categories ( =female,
=female,  =male) education in 3 categories, (
=male) education in 3 categories, ( =primary + vocational
=primary + vocational  =medium,
=medium,  =higher).
=higher).
In the case of raw data, when you open the test options window, e.g., the  for the
for the  tables, the
tables, the raw data option will automatically be selected..
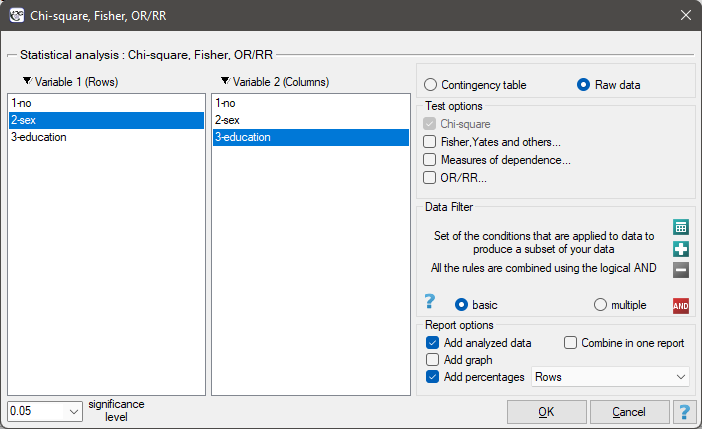
For data collected in a contingency table, it is a good idea to select this data (numerical values without headers) before opening the test window. Then, when you open the test window, the contingency table option will automatically be selected and the data from the selection will be displayed.
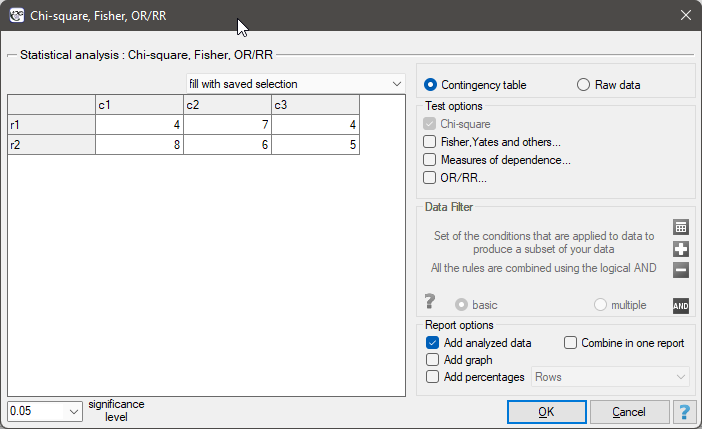
In the test window, we can always change the automatically detected setting regarding the form of data organization, as well as enter data into the contingency table from the window.
This is a basic condition for using many statistical tests based on contingency tables, e.g., the chi-square test. This condition implies a large expectred frequencies. According to Cochran's 1952 interpretation1), none of the expected frequencies can be  and no more than 20% can be
and no more than 20% can be  . Information about whether this condition is met (or not) by the data collected in the table can be returned to the report.
. Information about whether this condition is met (or not) by the data collected in the table can be returned to the report.
Basic tests for contingency tables:
Coefficients for contingency tables:
You can also include a basic summary of the tables in the results report:
 that is, data in the form of a contingency table. Such a table shows the distribution of observations for several traits (several variables). Table for 2 traits (
that is, data in the form of a contingency table. Such a table shows the distribution of observations for several traits (several variables). Table for 2 traits ( and the second
and the second  categories are shown below).
categories are shown below).

Frequencies observed  (
( ) represent the frequency of each category for both traits.
) represent the frequency of each category for both traits.
In order for such a table to be returned by the program, the option include analysed data should be selected in the test window. For the data from the example, the contingency table of observed frequencies is as follows:
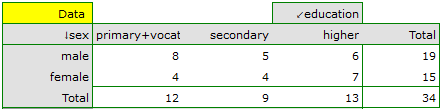
 can be created
can be created 
 ,
,  ,
, 
 ,
,  ,
, 
 ,
,  ,
,  .
.
For the data in the example The contingency table of expected frequencies is as follows:

- Contingency table of percentages calculated from the sum of columns. For the data in the example this table is as follows:

- Tcontingency table of percentages calculated from the sum of the rows. For the data in the example this table is as follows:

- A contingency table of percentages calculated from the sum of the total rows and columns. For the data in the example this table is as follows:

1)
Cochran W.G. (1952), The chi-square goodness-of-fit test. Annals of Mathematical Statistics, 23, 315-345
en/statpqpl/aopisowapl/tabliczpl/analizytbpl.txt · ostatnio zmienione: 2022/02/11 18:00 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
