Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:diagnpl
Spis treści
Diagnostics tests
Evaluation of diagnostic test
Suppose that using a diagnostic test we calculate the occurrence of a particular feature (most often disease) and know the gold-standard, so we know that the feature really occurs among the examined people. On the basis of these information, we can build a  contingency table:
contingency table:

where:
TP – true positive
FP – false positive
FN – false negative
TN – true negative
For such a table we can calculate the following measurements.
Sensitivity and specificity of diagnostic test
Every diagnostic test, in some cases, can obtain results different than actual results, for example a diagnostic test, basing on the obtained parameters, classifies a patient to the group of people suffering from a particular disease, or to the group of healthy people. In reality, the number of people approved for the above groups by the test may differ from the number of people genuinely ill and genuinely healthy.
There are two evaluation measurements of the test accuracy. They are:

Confidence interval is built on the basis of the Clopper-Pearson method for a single proportion.

Confidence interval is built on the basis of the Clopper-Pearson method for a single proportion.
Positive predictive values, negative predictive values and prevalence rate
 ) – the probability, that a person having a positive test result suffered from a disease. If the examined person obtains a positive test result, the PPV informs them how they can be sure, that they suffer from a particular disease.
) – the probability, that a person having a positive test result suffered from a disease. If the examined person obtains a positive test result, the PPV informs them how they can be sure, that they suffer from a particular disease.

Confidence interval is built on the basis of the Clopper-Pearson method for a single proportion.
 ) – the probability that a person having a negative test result did not suffer from any disease. If the examined person obtains a negative test result, the NPV informs them how they can be sure that they do not suffer from a particular disease.
) – the probability that a person having a negative test result did not suffer from any disease. If the examined person obtains a negative test result, the NPV informs them how they can be sure that they do not suffer from a particular disease.

Confidence interval is built on the basis of the Clopper-Pearson method for a single proportion.
Positive and negative predictive values depend on the prevalence rate.
Prevalence – probability of disease in the population for which the diagnostic test was conducted.

Confidence interval is built on the basis of the Clopper-Pearson method for a single proportion.
- Likelihood ratio of positive test and likelihood ratio of negative test
- Likelihood ratio of positive test (
 ) – this measurement enables the comparison of some test results matching to the gold-standard. It does not depend on the prevalence of the disease. It is the ratio of two odds: the odds that a person from the group of ill people will obtain a positive test result, and the same effect will be observed among healthy people.
) – this measurement enables the comparison of some test results matching to the gold-standard. It does not depend on the prevalence of the disease. It is the ratio of two odds: the odds that a person from the group of ill people will obtain a positive test result, and the same effect will be observed among healthy people.

Confidence interval for is built on the basis of the standard error:


Confidence interval for  is built on the basis of the standard error:
is built on the basis of the standard error:

- Accuracy (
 ) – the probability of a correct diagnose using a diagnostic test. If the examined person obtains a positive or a negative test result, the informs how they can be sure about the definitive diagnosis.
) – the probability of a correct diagnose using a diagnostic test. If the examined person obtains a positive or a negative test result, the informs how they can be sure about the definitive diagnosis.

Confidence interval is built on the basis of the Clopper-Pearson method for a single proportion.

Confidence interval for  is built on the basis of the standard error:
is built on the basis of the standard error:

The settings window with the diagnostic tests can be opened in Advanced stistics menu →Diagnostic tests → Diagnostic tests
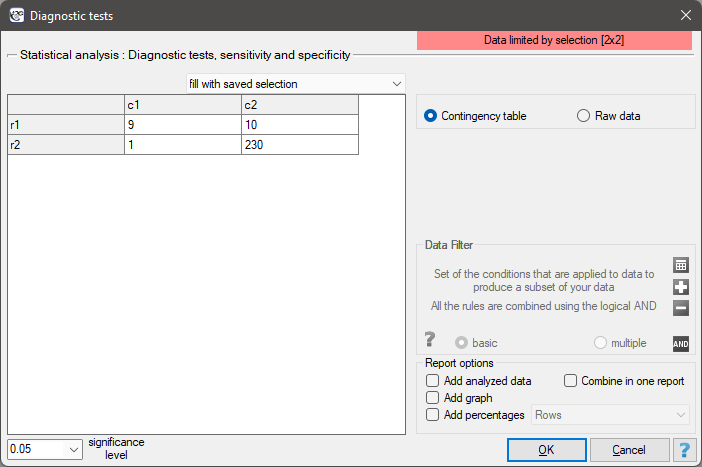
EXAMPLE (mammography.pqs file)
Mammography is one of the most popular screening tests which enables the detection of breast cancer. The following study has been carried out on the group of 250 people, so-called „asymptomatic” women at the age from 40 to 50. Mammography can detect an outbreak of cancer smaller than 5 mm and enables to note the change which is not a nodule yet but a change in the structure of tissues.

We will calculate the values enabling the assessment of the performed diagnostic test.
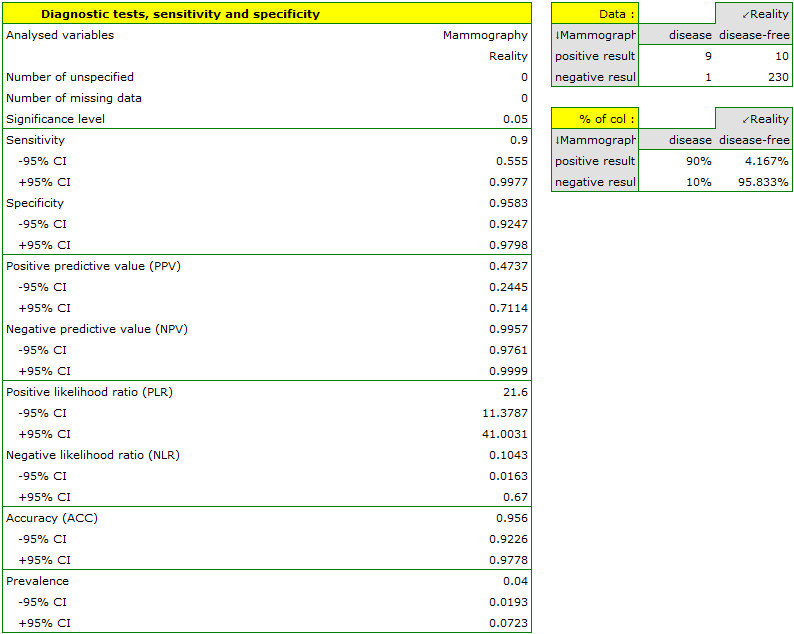
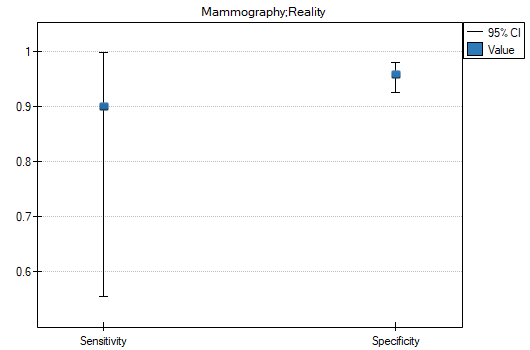
- 90% of women suffering from breast cancer have been correctly defined, so they have obtained the positive result of mammography;
- 95.83% of healthy women (not suffering from breast cancer) have been correctly defined, so they have obtained the negative result of mammography;
- 4 out of 100 examined women suffer from breast cancer;
- A woman who have obtained a positive mammography result can be 47.37% sure that she suffers from breast cancer;
- A women who have obtained a negative test result can be 99.57% sure that she does not suffer from breast cancer;
- The probability that the positive mammography result will be obtained by a woman genuinely suffering from cancer is 21.60 times greater than the probability that the positive mammography result will be obtained by a healthy woman (not suffering from breast cancer);
- The probability that the negative mammography result will be obtained by a woman genuinely suffering from breast cancer is 10.43% of the probability that the negative mammography result will be obtained by a healthy woman (not suffering from breast cancer);
- A woman undergoing mammography (regardless of age) can be 96.50% sure of the definitive diagnosis,
- The chance of a positive test result in a woman who actually has breast cancer is 207 times greater than the chance of such a result in a healthy woman.
The ROC Curve
The diagnostic test is used for differentiating objects with a given feature (marked as (+), e.g. ill people) from objects without the feature (marked as (–), e.g. healthy people). For the diagnostic test to be considered valuable, it should yield a relatively small number of wrong classifications. If the test is based on a dichotomous variable then the proper tool for the evaluation of the quality of the test is the analysis of a contingency table of true positive (TP), true negative (TN), false positive (FP), and false negative (FN) values. Most frequently, though, diagnostic tests are based on continuous variables or ordered categorical variables. In such a situation the proper means of evaluating the capability of the test for differentiating (+) and (–) are ROC (Receiver Operating Characteristic) curves.
It is frequently observed that the greater the value of the diagnostic variable, the greater the odds of occurrence of the studied phenomenon, or the other way round: the smaller the value of the diagnostic variable, the smaller the odds of occurrence of the studied phenomenon. Then, with the use of ROC curves, the choice of the optimum cut-off is made, i.e. the choice of a certain value of the diagnostic variable which best separates the studied statistical population into two groups: (+) in which the given phenomenon occurs and (–) in which the given phenomenon does not occur.
When, on the basis of the studies of the same objects, two or more ROC curves are constructed, one can compare the curves with regard to the quality of classification.
Let us assume that we have at our disposal a sample of  elements, in which each object has one of the
elements, in which each object has one of the  values of the diagnostic variable. Each of the received values of the diagnostic variable
values of the diagnostic variable. Each of the received values of the diagnostic variable  becomes the cut-off
becomes the cut-off  .
.
If the diagnostic variable is:
- stimulant (the growth of its value makes the odds of occurrence of the studied phenomenon greater), then values greater than or equal to the cut-off (
 ) are classified in group (+);
) are classified in group (+); - destimulant (the growth of its value makes the odds of occurrence of the studied phenomenon smaller), then values smaller than or equal to the cut-off () are classified in group (+);
For each of the cut-offs we define true positive (TP), true negative (TN), false positive (FP), and false negative (FN) values.


On the basis of those values each cut-off can be further described by means of sensitivity and specificity, positive predictive values(PPV), negative predictive values (NPV), positive result likelihood ratio (LR+), negative result likelihood ratio (LR-), and accuracy (Acc).
Note
The PQStat program computes the prevalence coefficient on the basis of the sample. The computed prevalence coefficient will reflect the occurrence of the studied phenomenon (illness) in the population in the case of screening of a large sample representing the population. If only people with suspected illness are directed to medical examinations, then the computed prevalence coefficient for them can be much higher than the prevalence coefficient for the population.
Because both the positive and negative predictive value depend on the prevalence coefficient, when the coefficient for the population is known a priori, we can use it to compute, for each cut-off , corrected predictive values according to Bayes's formulas:


where:
 - the prevalence coefficient put in by the user, the so-called pre-test probability of disease
- the prevalence coefficient put in by the user, the so-called pre-test probability of disease

The ROC curve is created on the basis of the calculated values of sensitivity and specificity. On the abscissa axis the  =1-specificity is placed, and on the ordinate axis
=1-specificity is placed, and on the ordinate axis  =sensitivity. The points obtained in that manner are linked. The constructed curve, especially the area under the curve, presents the classification quality of the analyzed diagnostic variable. When the ROC curve coincides with the diagonal
=sensitivity. The points obtained in that manner are linked. The constructed curve, especially the area under the curve, presents the classification quality of the analyzed diagnostic variable. When the ROC curve coincides with the diagonal  , then the decision made on the basis of the diagnostic variable is as good as the random distribution of studied objects into group (+) and group (–).
, then the decision made on the basis of the diagnostic variable is as good as the random distribution of studied objects into group (+) and group (–).
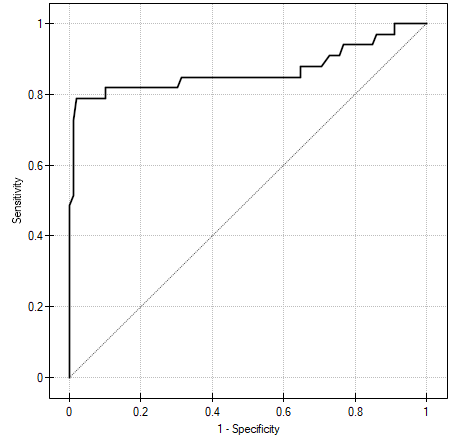
AUC (area under curve) – the size of the area under the ROC curve falls within  . The greater the field the more exact the classification of the objects in group (+) and group (–) on the basis of the analyzed diagnostic variable. Therefore, that diagnostic variable can be even more useful as a classifier. The area
. The greater the field the more exact the classification of the objects in group (+) and group (–) on the basis of the analyzed diagnostic variable. Therefore, that diagnostic variable can be even more useful as a classifier. The area  , error
, error  and confidence interval for AUC are calculated on the basis of:
and confidence interval for AUC are calculated on the basis of:
- nonparametric Hanley-McNeil method (Hanley J.A. i McNeil M.D. 19823)),
- Hanley-McNeil method which presumes double negative exponential distribution (Hanley J.A. i McNeil M.D. 19824)) - computed only when groups (+) and (–) are equinumerous.
For the classification to be better than random distribution of objects into to classes, the area under the ROC curve should be significantly larger than the area under the line , i.e. than 0.5.
Hypotheses:

The test statistics has the form presented below:

where:
 ,
,
 – size of the sample (+) in which the given phenomenon occurs,
– size of the sample (+) in which the given phenomenon occurs,
 – size of the sample (–), in which the given phenomenon does not occur.
– size of the sample (–), in which the given phenomenon does not occur.
The  statistic asymptotically (for large sample sizes) has the normal distribution.
statistic asymptotically (for large sample sizes) has the normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

In addition, when we assume that the diagnostic parameter forms a high field (AUC), we can select the optimal cut-off point.
EXAMPLE (acteriemia.pqs file)
Selection of optimum cut-off
The point which is looked for is a certain value of the diagnostic variable, which provides the optimum separation of the studied population into to groups: (+) in which the given phenomenon occurs and (–) in which the given phenomenon does not occur. The selection of the optimum cut-off is not easy because it requires specialist knowledge about the topic of the study. For example, different cut-offs will be required in, on the one hand, a test used for screening of a large group of people, e.g. for a mammography study, and, on the other hand, in invasive studies conducted for the purpose of confirming an earlier suspicion, e.g. in histopathology. With the help of an advanced mathematical apparatus we can find a cut-off which will be the most useful from the perspective of mathematics.
PQStat allows you to select the optimal cut-off point by:
- Tangent method (cost index) – calculated based on sensitivity, specificity, cost of erroneous decisions and prevalence.
Errors which can be made when classifying the studied objects as belonging to group (+) and group (–) are false positive results ( ) and false negative results (
) and false negative results ( ). If committing those errors is equally costly (ethical, financial, and other costs), then in the field
). If committing those errors is equally costly (ethical, financial, and other costs), then in the field Cost FP and in the field Cost FN we enter the same positive value – usually 1. However, if we come to the conclusion that one type of error is encumbered with a greater cost than the other one, then we will assign appropriately greater weight to it.
The optimum cut-off value is calculated on the basis of sensitivity, specificity, and with the help of value  – slope of the tangent line to the ROC curve. The slope angle is defined in relation to two values: the costs of wrong decisions and the prevalence coefficient. Normally the costs of wrong decisions have the value 1 and the prevalence coefficient is estimated from the sample. Knowing, a priori, the prevalence coefficient () and the costs of wrong decisions, the user can influence the value and, consequently, the search for an optimum cut-off. As a result, the optimum cut-off is determined to be such a value of the diagnostic variable for which the formula:
– slope of the tangent line to the ROC curve. The slope angle is defined in relation to two values: the costs of wrong decisions and the prevalence coefficient. Normally the costs of wrong decisions have the value 1 and the prevalence coefficient is estimated from the sample. Knowing, a priori, the prevalence coefficient () and the costs of wrong decisions, the user can influence the value and, consequently, the search for an optimum cut-off. As a result, the optimum cut-off is determined to be such a value of the diagnostic variable for which the formula:

reaches the minimum (Zweig M.H. 19935)).
The optimum cut-off point of the diagnostic variable, selected as described above, will finally be marked on the ROC curve.
- Costs graph – presents the calculated values of an wrong diagnosis together with their costs. The values are computed according to the formula:

The point marked on the graph is the minimum of the function presented above.
- Youden's Index – Conceptually, it is the maximum distance between the line that is the diagonal of a square of side 1 and the point of the ROC curve 6). This index is calculated from the formula:

The optimal cut-off point of the diagnostic variable thus selected will eventually be marked on the ROC curve plot.
- Distance from the top left corner – Conceptually, it is the minimum distance between the upper left corner of a square of side 1 (i.e., the place where sensitivity and specificity can be highest) and the point of the ROC curve. This index is calculated from the formula:

The optimal cut-off point of the diagnostic variable thus selected will eventually be marked on the ROC curve plot.
- Costs graph – presents the calculated values of an wrong diagnosis together with their costs. The values are computed according to the formula:
The point marked on the graph is the minimum of the function presented above.
- Sensitivity and specificity intersection graph – allows the localization of the point in which the value of sensitivity and specificity is simultaneously the greatest.
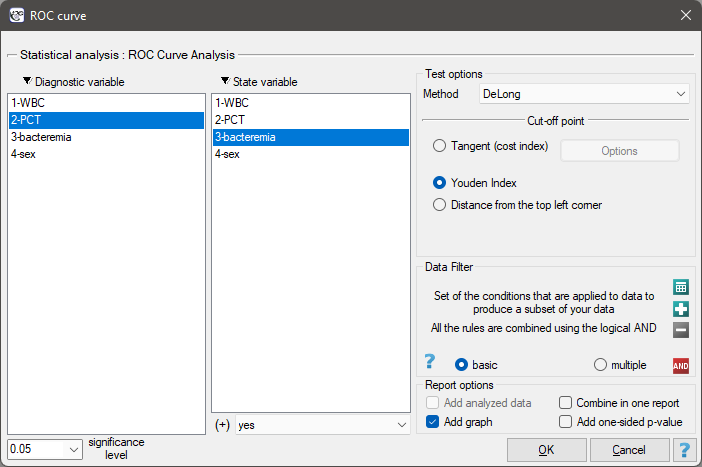
The window with settings for ROC analysis is accessed via the menu Advanced statistics → Diagnostic tests→ROC curve.
EXAMPLE (file bacteriemia.pqs)
Persistent high fever in an infant or a small child without clearly diagnosed reasons is a premise for testing for bacteremia. The most useful and reliable parameters for screening and monitoring bacterial infections are the following indicators:
- WBC – the number of white blood cells
- PCT – procalcitonin.
It is assumed that in a healthy infant or a small child WBC should not exceed 15 thousand/ and PCT should be lower than 0.5 ng/ml.
and PCT should be lower than 0.5 ng/ml.
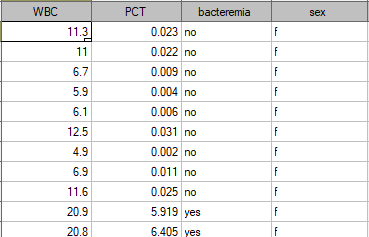
The sample values of those indicators for 136 children of up to 3 years old with persistent fever  is presented in the table fragment below:
is presented in the table fragment below:
One method of analyzing the PCT indicator is transforming it into a dichotomous variable by selecting a cut-off (e.g. =0.5 ng/ml) above which the study is considered to be „positive”. The level of adequacy of such a division will be indicated by the value of sensitivity and specificity. We want to use a more complex approach, that is, calculate the sensitivity and specificity not only for one value but for each PCT value obtained in the sample - which means constructing a ROC curve. On the basis of the information obtained in that manner we want to check if the PTC indicator is indeed useful for diagnosing bacteremia. If so, then we want to check what is the optimal cut-off above which we can consider the study to be „positive” – detecting bacteremia.
In order to check if PTC is really useful for diagnosing bacteremia we will calculate the size of the area under the ROC curve and verify the hypothesis that:

As bacteremia is accompanied by an increased PCT level, in the test options window we will consider the indicator to be a stimulant. In the state variable we have to define which value in the bacteremia column determines its presence, then we select „yes”. Apart from the result of the statistical test, in the report we can find an exact description of every possible cut-off.
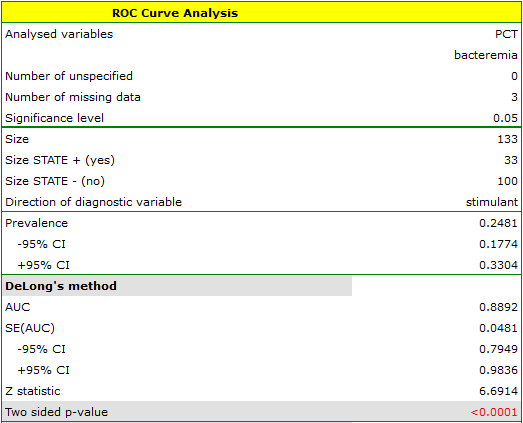
The calculated size of the area under the ROC curve is AUC=0.889. Therefore, on the basis of the adopted level  , based on the obtained value p<0.0001 we assume that diagnosing bacteremia with the use of the PCT indicator is indeed more useful than a random distribution of patients into 2 groups: suffering from bacteremia and not suffering from it. Therefore, we return to the analysis (button
, based on the obtained value p<0.0001 we assume that diagnosing bacteremia with the use of the PCT indicator is indeed more useful than a random distribution of patients into 2 groups: suffering from bacteremia and not suffering from it. Therefore, we return to the analysis (button  ) to define the optimal cut-off.
) to define the optimal cut-off.
The algorithm of searching for the optimal cut-off takes into account the costs of wrong decisions and the prevalence coefficient.
FN cost - wrong diagnosisis the cost of assuming that the patient does not suffer from bacteremia although in reality he or she is suffering from it (costs of a falsely negative decision)FP cost - wrong diagnosis, is the cost of assuming that the patient suffers from bacteremia although in reality he or she is not suffering from it (costs of a falsely positive decision)
As the FN costs are much more serious than the FP costs, we enter a greater value in field one than in field two. We decided the value would be 5.
The PCT value is to be used in screening so we do not give the prevalence coefficient for the population (a priori prevalence coefficient) which is very low but we use the estimated coefficient from the sample. We do so in order not to move the cut-off of the PCT value too high and not to increase the number of falsely negative results.
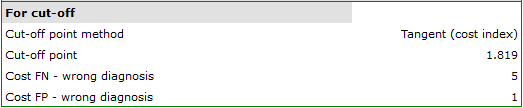
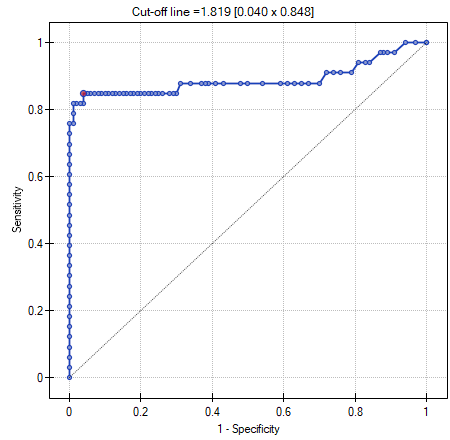
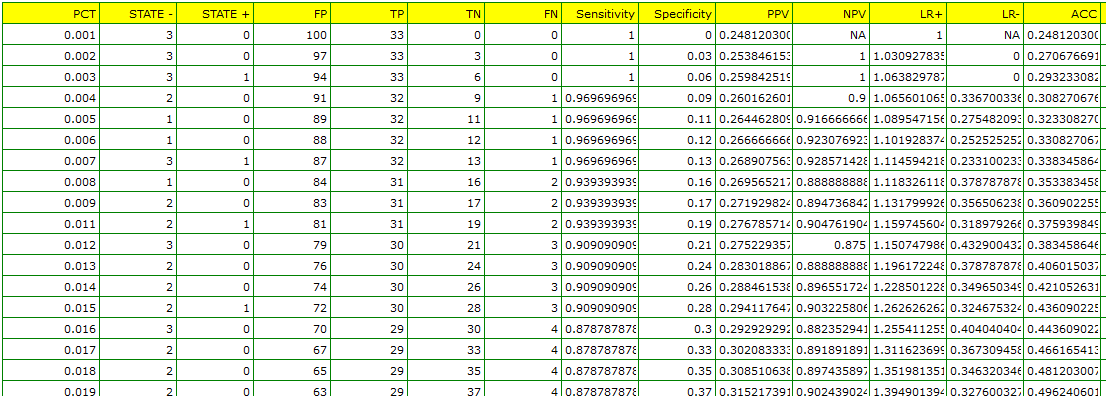
The optimal PCT cut-off determined in this way is 1.819. For this point sensitivity=0.85 and specificity=0.96.
Another method of selecting the cut-off is the anlysis of the costs graph and of the sensitivity intersection graph:
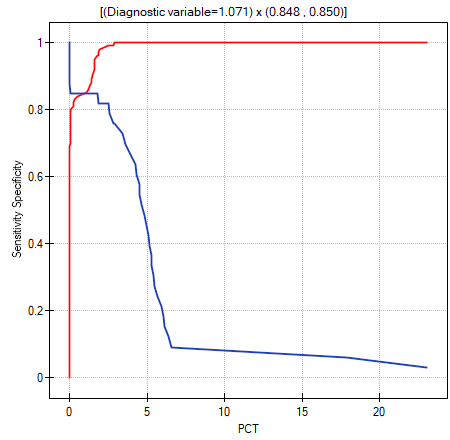
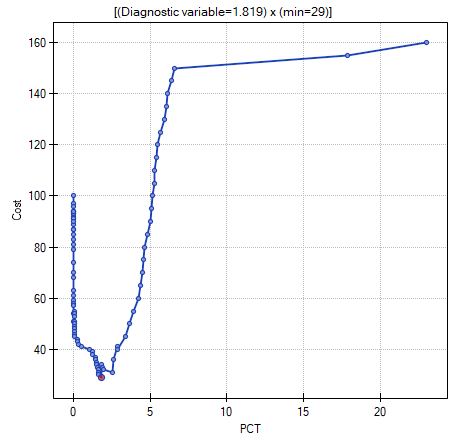
The analysis of the costs graph shows that the minimum of the costs of wrong decisions lies at PCT=1.819. The value of sensitivity and specificity is similar at PCT=1.071.
ROC curves comparison
Very often the aim of studies is the comparison of the size of the area under the ROC curve ( ) with the area under another ROC curve (
) with the area under another ROC curve ( ). The ROC curve with a greater area usually allows a more precise classification of objects.
Methods for comparing the areas depend on the model of the study.
). The ROC curve with a greater area usually allows a more precise classification of objects.
Methods for comparing the areas depend on the model of the study.
- Dependent model – the compared ROC curves are constructed on the basis of measurements made on the same objects.
Hypotheses:

The test statistics has the form presented below:

where:
, and the standard error of the difference in areas  are calculated on the basis of the nonparametric method proposed by DeLong (DeLong E.R. et al., 19887), Hanley J.A., and Hajian-Tilaki K.O. 19978))
are calculated on the basis of the nonparametric method proposed by DeLong (DeLong E.R. et al., 19887), Hanley J.A., and Hajian-Tilaki K.O. 19978))
Statistics has (for large sizes) asymptotic normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The window with settings for comparing dependent ROC curves is accessed via the menu Advanced statistics → Diagnostic tests → Dependent ROC Curves – comparison.
- Independent model – the compared ROC curves are constructed on the basis of measurements made on different objects.
Hypotheses:
Test statistics (Hanley J.A. and McNeil M.D. 19839)) has the form:

where:
, and standard errors of areas  ,
,  are calculated on the basis of:
are calculated on the basis of:
- nonparametric method DeLong (DeLong E.R. et al. 1988(DeLong E.R., DeLong D.M., Clarke-Pearson D.L., (1988), Comparing the areas under two or more correlated receiver operating curves: A nonparametric approach. Biometrics 44:837-845)), Hanley J.A., and Hajian-Tilaki K.O. 199710)) - recommended,
- nonparametric Hanley-McNeil method (Hanley J.A. and McNeil M.D. 198211)),
- method which presumes double negative exponential distribution (Hanley J.A. and McNeil M.D. 1982\cite{hanley_mcn}) - computed only when groups (+) and (–) are equinumerous.
Statistics has (for large sizes) asymptotic normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The window with settings for comparing independent ROC curves is accessed via the menu Advanced statistics→Diagnostic tests→Independent ROC Curves – comparison
EXAMPLE cont. (bacteriemia.pqs file)
We will make 2 comparisons:
- 1) We will construct 2 ROC curves to compare the diagnostic value of parameters WBC and PCT;
- 2) We will construct 2 ROC curves to compare the diagnostic value of PCT parameter for boys and girls.
- ad1)
Both parameters, WBC and PCT, are stimulants (in bacteremia their values are high). In the course of the comparison of the diagnostic value of those parameters we verify the following hypotheses:

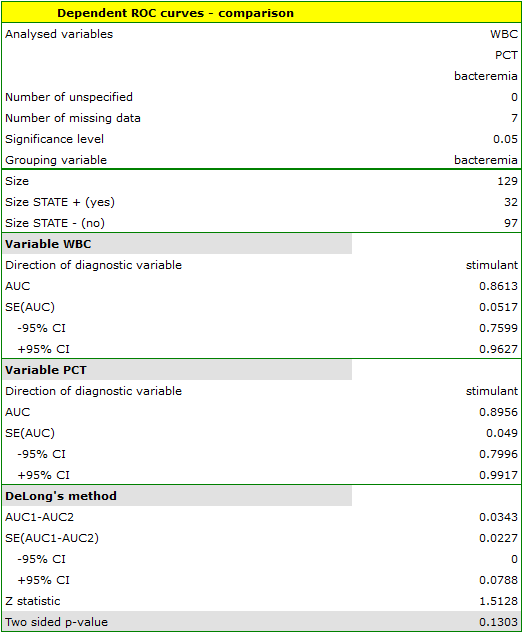
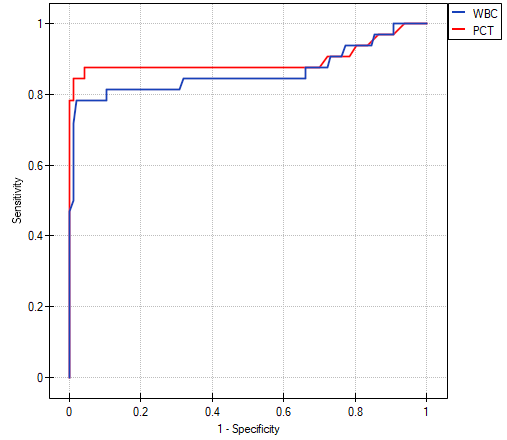
The calculated ares are  ,
,  . On the basis of the adopted level , based on the obtained value
. On the basis of the adopted level , based on the obtained value  =0.13032 we conclude that we cannot determine which of the parameters: WBC or PCT is better for diagnosing bacteremia.
=0.13032 we conclude that we cannot determine which of the parameters: WBC or PCT is better for diagnosing bacteremia.
- ad2) PCT parameter is a stimulant (its value is high in bacteremia). In the course of the comparison of its diagnostic value for girls and boys we verify the following hypotheses:

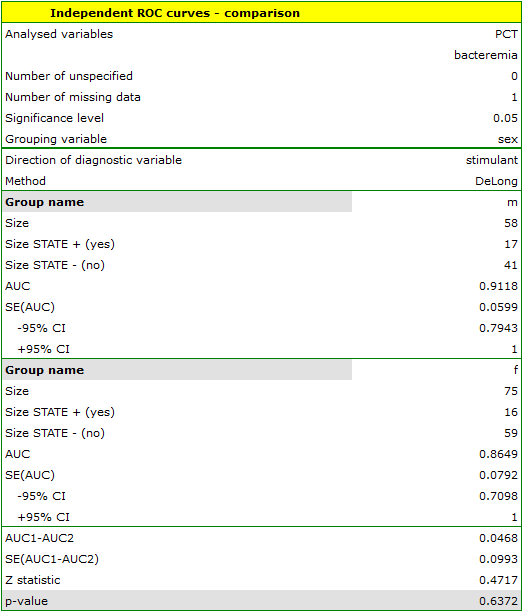
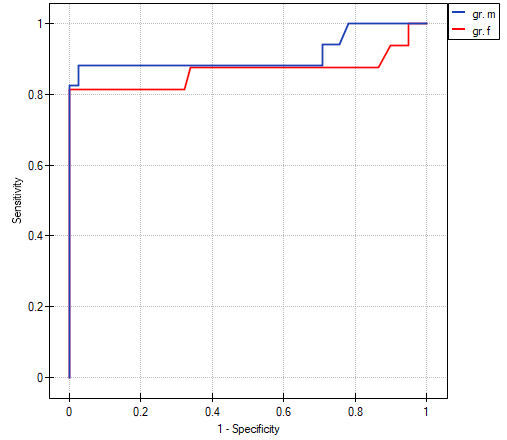
The calculated areas are  ,
,  . Therefore, on the basis of the adopted level , based on the obtained value =0.6372 we conclude that we cannot select the sex for which PCT parameter is better for diagnosing bacteremia.
. Therefore, on the basis of the adopted level , based on the obtained value =0.6372 we conclude that we cannot select the sex for which PCT parameter is better for diagnosing bacteremia.
1)
, 7)
DeLong E.R., DeLong D.M., Clarke-Pearson D.L., (1988), Comparing the areas under two or more correlated receiver operating curves: A nonparametric approach. Biometrics 44:837-845
2)
, 8)
, 10)
Hanley J.A. i Hajian-Tilaki K.O. (1997), Sampling variability of nonparametric estimates of the areas under receiver operating characteristic curves: an update. Academic radiology 4(1):49-58
3)
, 4)
, 11)
Hanley J.A. i McNeil M.D. (1982), The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 143(1):29-36
5)
Zweig M.H., Campbell G. (1993), Receiver-operating characteristic (ROC) plots: a fundamental evaluation tool in clinical medicine. Clinical Chemistry 39:561-577
6)
Youden W.J. (1950), Index for rating diagnostic tests. Cancer. 3: 32–35
9)
Hanley J.A. i McNeil M.D. (1983), A method of comparing the areas under receiver operating characteristic curves derived from the same cases. Radiology 148: 839-843
en/statpqpl/diagnpl.txt · ostatnio zmienione: 2022/02/13 21:54 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
