Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:porown3grpl:parpl:anovaposthpl
The contrasts and the POST-HOC tests
An analysis of the variance enables you to get information only if there are any significant differences among populations. It does not inform you which populations are different from each other. To gain some more detailed knowledge about the differences in particular parts of our complex structure, you should use contrasts (if you do the earlier planned and usually only particular comparisons), or the procedures of multiple comparisons POST-HOC tests (when having done the analysis of variance, we look for differences, usually between all the pairs).
The number of all the possible simple comparisons is calculated using the following formula:

Hypotheses:
The first example - simple comparisons (comparison of 2 selected means):

The second example - complex comparisons (comparison of combination of selected means):
![\begin{array}{cc}
\mathcal{H}_0: & \mu_1=\frac{\mu_2+\mu_3}{2},\\[0.1cm]
\mathcal{H}_1: & \mu_1\neq\frac{\mu_2+\mu_3}{2}.
\end{array}](/lib/exe/fetch.php?media=wiki:latex:/imgf0472a7ad15f9b99bbf5ce50cb721339.png "LaTeX")
If you want to define the selected hypothesis you should ascribe the contrast value  ,
,  to each mean. The values are selected, so that their sums of compared sides are the opposite numbers, and their values of means which are not analysed count to 0.
to each mean. The values are selected, so that their sums of compared sides are the opposite numbers, and their values of means which are not analysed count to 0.
- The first example:
 ,
,  ,
,  .
. - The second example:
 , ,
, ,  ,
,  ,…,
,…,  .
.
How to choose the proper hypothesis:

- [ii] The p-value, designated on the basis of the proper POST-HOC test, is compared with the significance level
 :
:

For simple and complex comparisons, equal-size groups as well as unequal-size groups, when the variances are equal.
- [i] The value of critical difference is calculated by using the following formula:

where:
 - is the critical value (statistic) of the F Snedecor distribution for a given significance level and degrees of freedom, adequately: 1 and
- is the critical value (statistic) of the F Snedecor distribution for a given significance level and degrees of freedom, adequately: 1 and  .
.
- [ii] The test statistic is defined by:

The test statistic has the t-student distribution with degrees of freedom.
For simple comparisons, equal-size groups as well as unequal-size groups, when the variances are equal.
- [i] The value of a critical difference is calculated by using the following formula:

where:
 - is the critical value(statistic) of the F Snedecor distribution for a given significance level and
- is the critical value(statistic) of the F Snedecor distribution for a given significance level and  and degrees of freedom.
and degrees of freedom.
- [ii] The test statistic is defined by:

The test statistic has the F Snedecor distribution with and degrees of freedom.
For simple comparisons, equal-size groups as well as unequal-size groups, when the variances are equal.
- [i] The value of a critical difference is calculated by using the following formula:

where:
 - is the critical value (statistic) of the studentized range distribution for a given significance level and and
- is the critical value (statistic) of the studentized range distribution for a given significance level and and  degrees of freedom.
degrees of freedom.
- [ii] The test statistic is defined by:

The test statistic has the studentized range distribution with and degrees of freedom.
Info.
The algorithm for calculating the p-value and the statistic of the studentized range distribution in PQStat is based on the Lund works (1983)1). Other applications or web pages may calculate a little bit different values than PQStat, because they may be based on less precised or more restrictive algorithms (Copenhaver and Holland (1988), Gleason (1999)).
The test examining the existence of a trend can be calculated in the same situation as ANOVA for independent variables, because it is based on the same assumptions, but it captures the alternative hypothesis differently - indicating in it the existence of a trend in the mean values for successive populations. The analysis of the trend in the arrangement of means is based on contrasts Fisher LSD. By building appropriate contrasts, you can study any type of trend such as linear, quadratic, cubic, etc. Below is a table of sample contrast values for selected trends.

Linear trend
A linear trend, like other trends, can be analyzed by entering the appropriate contrast values. However, if the direction of the linear trend is known, simply use the For trend option and indicate the expected order of the populations by assigning them consecutive natural numbers.
The analysis is performed on the basis of linear contrast, i.e. the groups indicated according to the natural order are assigned appropriate contrast values and the statistics are calculated Fisher LSD .
With the expected direction of the trend known, the alternative hypothesis is one-sided and the one-sided  -value is interpreted. The interpretation of the two-sided -value means that the researcher does not know (does not assume) the direction of the possible trend.
-value is interpreted. The interpretation of the two-sided -value means that the researcher does not know (does not assume) the direction of the possible trend.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
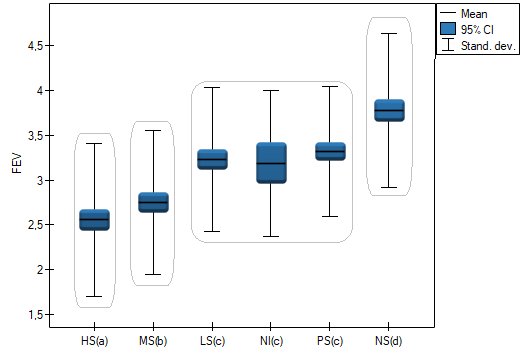
For each post-hoc test, homogeneous groups are constructed. Each homogeneous group represents a set of groups that are not statistically significantly different from each other. For example, suppose we divided subjects into six groups regarding smoking status: Nonsmokers (NS), Passive smokers (PS), Noninhaling smokers (NI), Light smokers (LS), Moderate smokers (MS), Heavy smokers (HS) and we examine the expiratory parameters for them. In our ANOVA we obtained statistically significant differences in exhalation parameters between the tested groups. In order to indicate which groups differ significantly and which do not, we perform post-hoc tests. As a result, in addition to the table with the results of each pair of comparisons and statistical significance in the form of :
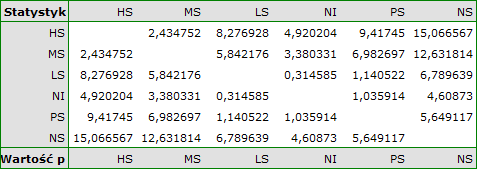
we obtain a division into homogeneous groups:
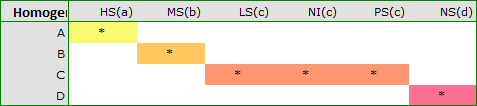
In this case we obtained 4 homogeneous groups, i.e. A, B, C and D, which indicates the possibility of conducting the study on the basis of a smaller division, i.e. instead of the six groups we studied originally, further analyses can be conducted on the basis of the four homogeneous groups determined here. The order of groups was determined on the basis of weighted averages calculated for particular homogeneous groups in such a way, that letter A was assigned to the group with the lowest weighted average, and further letters of the alphabet to groups with increasingly higher averages.
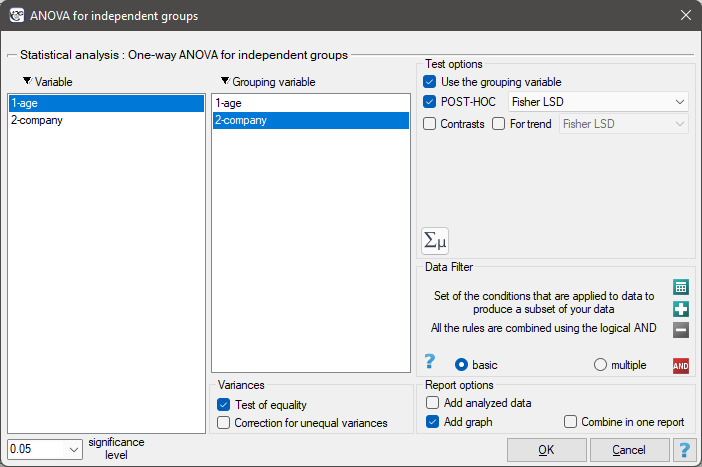
The settings window with the One-way ANOVA for independent groups can be opened in Statistics menu→Parametric tests→ANOVA for independent groups or in ''Wizard''.
1)
Lund R.E., Lund J.R. (1983), Algorithm AS 190, Probabilities and Upper Quantiles for the Studentized Range. Applied Statistics; 34
en/statpqpl/porown3grpl/parpl/anovaposthpl.txt · ostatnio zmienione: 2022/02/12 17:01 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
