Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:porown3grpl:nparpl:anova_friepl
The Friedman ANOVA
The Friedman repeated measures analysis of variance by ranks – the Friedman ANOVA - was described by Friedman (1937)1). This test is used when the measurements of an analysed variable are made several times ( ) each time in different conditions. It is also used when we have rankings coming from different sources (form different judges) and concerning a few () objects, but we want to assess the grade of the rankings agreement.
) each time in different conditions. It is also used when we have rankings coming from different sources (form different judges) and concerning a few () objects, but we want to assess the grade of the rankings agreement.
Iman Davenport (19802)) has shown that in many cases the Friedman statistic is overly conservative and has made some modification to it. This modification is the non-parametric equivalent of the ANOVA for dependent groups which makes it now recommended for use in place of the traditional Friedman statistic.
Additional analyses:
- It is possible to take missing data into account by using the Accept missing data option, calculating Durbin ANOVA or Skillings-Mack ANOVA;
- it is possible to test the trend in the arrangement of the studied groups by performing Page test for trend.
Basic assumptions:
- measurement on an ordinal scale or on an interval scale,
Hypotheses relate to the equality of the sum of ranks for successive measurements ( ) or are simplified to medians (
) or are simplified to medians ( )
)

where:
 medians for an analysed features, in the following measurements from the examined population.
medians for an analysed features, in the following measurements from the examined population.
Two test statistics are determined: the Friedman statistic and the Iman-Davenport modification of this statistic.
The Friedman statistic has the form:

where:
 – sample size,
– sample size,
 – ranks ascribed to the following measurements
– ranks ascribed to the following measurements  , separately for the analysed objects
, separately for the analysed objects  ,
,
 – correction for ties,
– correction for ties,
 – number of cases included in a tie.
– number of cases included in a tie.
The Iman-Davenport modification of the Friedman statistic has the form:

The formula for the test statistic  and
and  includes the correction for ties
includes the correction for ties  . This correction is used, when ties occur (if there are no ties, the correction is not calculated, because of
. This correction is used, when ties occur (if there are no ties, the correction is not calculated, because of  ).
).
The statistic has asymptotically (for large sample sizes) has the Chi-square distribution with  degrees of freedom.
degrees of freedom.
The statistic follows the Snedecor's F distribution with  i
i  degrees of freedem.
degrees of freedem.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

The POST-HOC tests
Introduction to the contrasts and the POST-HOC tests was performed in the unit, which relates to the one-way analysis of variance.
For simple comparisons (frequency in particular measurements is always the same).
The Dunn test (Dunn 19643)) is a corrected test due to multiple testing. The Bonferroni or Sidak correction is most commonly used here, although other, newer corrections are also available and are described in more detail in the Multiple Comparisons section.
Hypotheses:
Example - simple comparisons (comparison of 2 selected medians):

- [i] The value of critical difference is calculated by using the following formula:

where:
 - is the critical value (statistic) of the normal distribution for a given significance level corrected on the number of possible simple comparisons
- is the critical value (statistic) of the normal distribution for a given significance level corrected on the number of possible simple comparisons  .
.
- [ii] The test statistic is defined by:

where:
 – mean of the ranks of the
– mean of the ranks of the  -th measurement, for ,
-th measurement, for ,
The test statistic asymptotically (for large sample size) has normal distribution, and the p-value is corrected on the number of possible simple comparisons .
Non-parametric equivalent of Fisher LSD4), sed for simple comparisons (counts across measurements are always the same).
- [i] he value of critical difference is calculated by using the following formula:

where:
 – sum of squares for ranks,
– sum of squares for ranks,
 to critical value (statistic) Snedecor's F distribution for a given significance level and for degrees of freedom respectively: 1 and
to critical value (statistic) Snedecor's F distribution for a given significance level and for degrees of freedom respectively: 1 and  .
.
- [ii] The test statistic is defined by:

where:
 – the sum of ranks of th measurement, for ,
– the sum of ranks of th measurement, for ,
The test statistic hast-Student distribution with degrees of freedem.
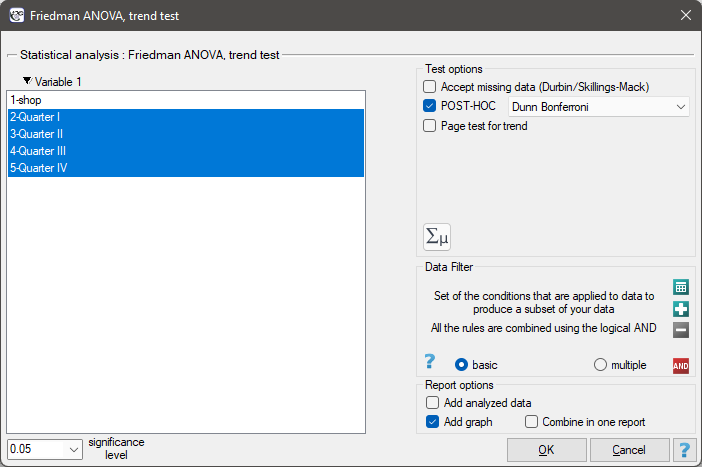
The settings window with the Friedman ANOVA can be opened in Statistics menu→NonParametric tests →Friedman ANOVA, trend test or in ''Wizard''
EXAMPLE (chocolate bar.pqs file)
Quarterly sale of some chocolate bar was measured in 14 randomly chosen supermarkets. The study was started in January and finished in December. During the second quarter, the billboard campaign was in full swing. Let's check if the campaign had an influence on the advertised chocolate bar sale.

Hypotheses:


Comparing the p-value of the Friedman test (as well as the p-value of the Iman-Davenport correction of the Friedman test) with a significance level  , we find that sales of the bar are not the same in each quarter. The POST-HOC Dunn analysis performed with the Bonferroni correction indicates differences in sales volumes pertaining to quarters I and III and I and IV, and an analogous analysis performed with the stronger Conover-Iman test indicates differences between all quarters except quarters III and IV.
, we find that sales of the bar are not the same in each quarter. The POST-HOC Dunn analysis performed with the Bonferroni correction indicates differences in sales volumes pertaining to quarters I and III and I and IV, and an analogous analysis performed with the stronger Conover-Iman test indicates differences between all quarters except quarters III and IV.
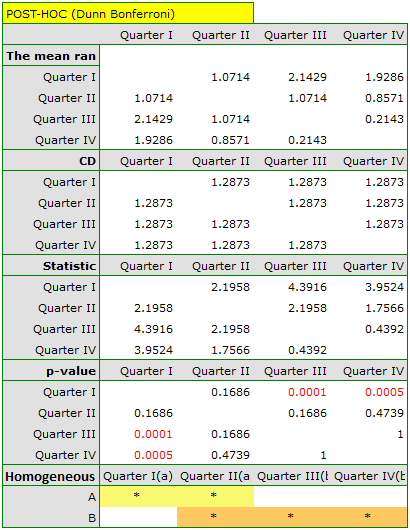
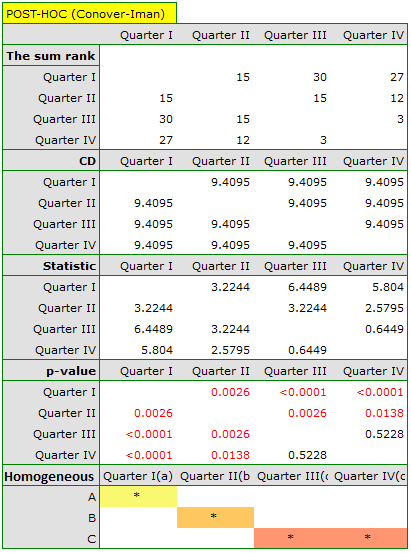
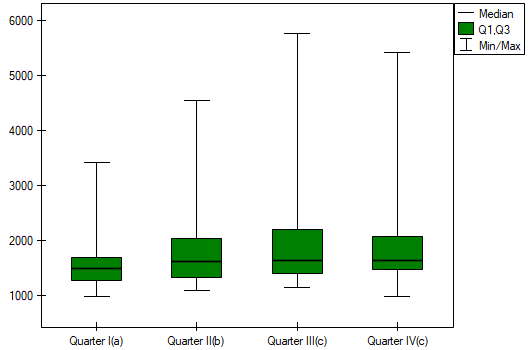
In the graph, we presented homogeneous groups determined by the Conover-Iman test.
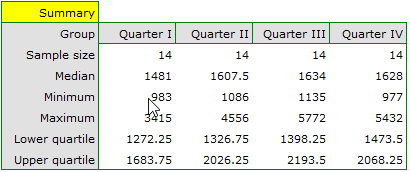
We can provide a detailed description of the data by selecting Descriptive statistics in the analysis window  .
.
If the data were described by an ordinal scale with few categories, it would be useful to present it also in numbers and percentages. In our example, this would not be a good method of description.
1)
Friedman M. (1937), The use of ranks to avoid the assumption of normality implicit in the analysis of variance. Journal of the American Statistical Association, 32,675-701
2)
Iman R. L., Davenport J. M. (1980), Approximations of the critical region of the friedman statistic, Communications in Statistics 9, 571–595
3)
Dunn O. J. (1964), Multiple comparisons using rank sums. Technometrics, 6: 241–252
4)
Conover W. J. (1999), Practical nonparametric statistics (3rd ed). John Wiley and Sons, New York
en/statpqpl/porown3grpl/nparpl/anova_friepl.txt · ostatnio zmienione: 2022/02/13 16:42 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
