Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:korelpl:nparpl
Spis treści
Non-parametric tests
The monotonic correlation coefficients
The monotonic correlation may be described as monotonically increasing or monotonically decreasing. The relation between 2 features is presented by the monotonic increasing if the increasing of the one feature accompanies with the increasing of the other one. The relation between 2 features is presented by the monotonic decreasing if the increasing of the one feature accompanies with the decreasing of the other one.
The Spearman's rank-order correlation coefficient  is used to describe the strength of monotonic relations between 2 features:
is used to describe the strength of monotonic relations between 2 features:  and
and  . It may be calculated on an ordinal scale or an interval one. The value of the Spearman's rank correlation coefficient should be calculated using the following formula:
. It may be calculated on an ordinal scale or an interval one. The value of the Spearman's rank correlation coefficient should be calculated using the following formula:

 – difference of
– difference of  .
.
This formula is modified when there are ties:

where:
 ,
,  ,
, ,
,  ,
, – number of cases included in tie.
– number of cases included in tie.
This correction is used, when ties occur. If there are no ties, the correction is not calculated, because the correction is reduced to the formula describing the above equation.
Note
 – the Spearman's rank correlation coefficient in a population;
– the Spearman's rank correlation coefficient in a population;
– the Spearman's rank correlation coefficient in a sample.
The value of  , and it should be interpreted the following way:
, and it should be interpreted the following way:
 means a strong positive monotonic correlation (increasing) – when the independent variable increases, the dependent variable increases too;
means a strong positive monotonic correlation (increasing) – when the independent variable increases, the dependent variable increases too; means a strong negative monotonic correlation (decreasing) – when the independent variable increases, the dependent variable decreases;
means a strong negative monotonic correlation (decreasing) – when the independent variable increases, the dependent variable decreases;- if the Spearman's correlation coefficient is of the value equal or very close to zero, there is no monotonic dependence between the analysed features (but there might exist another relation - a non monotonic one, for example a sinusoidal relation).
The Kendall's tau correlation coefficient (Kendall (1938)1)) is used to describe the strength of monotonic relations between features . It may be calculated on an ordinal scale or interval one. The value of the Kendall's  correlation coefficient should be calculated using the following formula:
correlation coefficient should be calculated using the following formula:

where:
 – number of pairs of observations, for which the values of the ranks for the feature as well as feature are changed in the same direction (the number of agreed pairs),
– number of pairs of observations, for which the values of the ranks for the feature as well as feature are changed in the same direction (the number of agreed pairs), – number of pairs of observations, for which the values of the ranks for the feature are changed in the different direction than for the feature (the number of disagreed pairs),
– number of pairs of observations, for which the values of the ranks for the feature are changed in the different direction than for the feature (the number of disagreed pairs), ,
,  ,
,- – number of cases included in a tie.
The formula for the correlation coefficient includes the correction for ties. This correction is used, when ties occur (if there are no ties, the correction is not calculated, because of  i
i  ) .
) .
Note
 – the Kendall's correlation coefficient in a population;
– the Kendall's correlation coefficient in a population;
– the Kendall's correlation coefficient in a sample.
The value of  , and it should be interpreted the following way:
, and it should be interpreted the following way:
 means a strong agreement of the sequence of ranks (the increasing monotonic correlation) – when the independent variable increases, the dependent variable increases too;
means a strong agreement of the sequence of ranks (the increasing monotonic correlation) – when the independent variable increases, the dependent variable increases too; means a strong disagreement of the sequence of ranks (the decreasing monotonic correlation) – when the independent variable increases, the dependent variable decreases;
means a strong disagreement of the sequence of ranks (the decreasing monotonic correlation) – when the independent variable increases, the dependent variable decreases;- if the Kendall's correlation coefficient is of the value equal or very close to zero, there is no monotonic dependence between analysed features (but there might exist another relation - a non monotonic one, for example a sinusoidal relation).
Spearman's versus Kendall's coefficient
- for an interval scale with a normality of the distribution, the gives the results which are close to
 , but may be totally different from ,
, but may be totally different from , - the value is less or equal to value,
- the is an unbiased estimator of the population parameter , while the is a biased estimator of the population parameter .
EXAMPLE cont. (sex-height.pqs file)
The Spearman's rank-order correlation coefficient
The test of significance for the Spearman's rank-order correlation coefficient is used to verify the hypothesis determining the lack of monotonic correlation between analysed features of the population and it is based on the Spearman's rank-order correlation coefficient calculated for the sample. The closer to 0 the value of coefficient is, the weaker dependence joins the analysed features.
Basic assumptions:
- measurement on an ordinal scale or on an interval scale.
Hypotheses:

The test statistic is defined by:

where  .
.
The value of the test statistic can not be calculated when  lub
lub  or when
or when  .
.
The test statistic has the t-Student distribution with  degrees of freedom.
degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

The settings window with the Spearman's monotonic correlation can be opened in Statistics menu → NonParametric tests→monotonic correlation (r-Spearman) or in ''Wizard''.
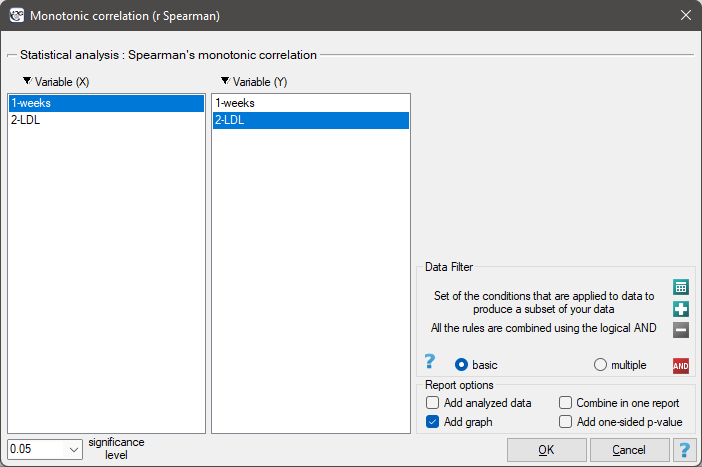
The effectiveness of a new therapy designed to lower cholesterol levels in the LDL fraction was studied. 88 people at different stages of the treatment were examined. We will test whether LDL cholesterol levels decrease and stabilize with the duration of the treatment (time in weeks).
Hypotheses:

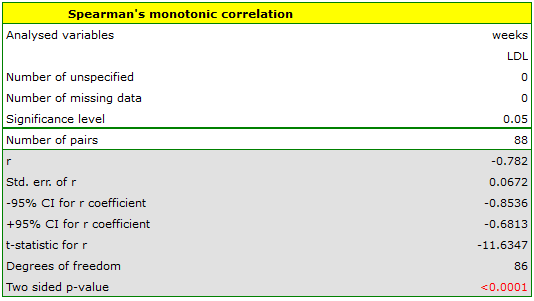
Comparing  <0.0001 with a significance level
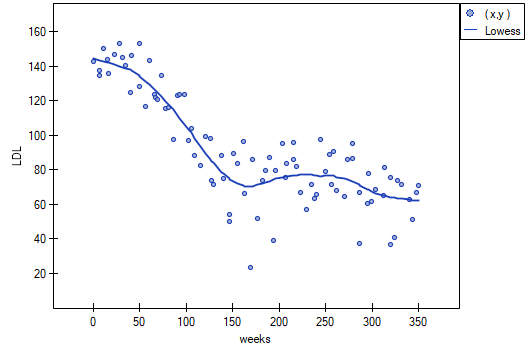
<0.0001 with a significance level  we find that there is a statistically significant monotonic relationship between treatment time and LDL levels. This relationship is initially decreasing and begins to stabilize after 150 weeks. The Spearman's monotonic correlation coefficient and therefore the strength of the monotonic relationship for this relationship is quite high at =-0.78. The graph was plotted by curve fitting through local LOWESS linear smoothing techniques.
we find that there is a statistically significant monotonic relationship between treatment time and LDL levels. This relationship is initially decreasing and begins to stabilize after 150 weeks. The Spearman's monotonic correlation coefficient and therefore the strength of the monotonic relationship for this relationship is quite high at =-0.78. The graph was plotted by curve fitting through local LOWESS linear smoothing techniques.
The Kendall's tau correlation coefficient
The test of significance for the Kendall's correlation coefficient is used to verify the hypothesis determining the lack of monotonic correlation between analysed features of population. It is based on the Kendall's tau correlation coefficient calculated for the sample. The closer to 0 the value of tau is, the weaker dependence joins the analysed features.
Basic assumptions:
- measurement on an ordinal scale or on an interval scale.
Hypotheses:

The test statistic is defined by:

The test statistic asymptotically (for a large sample size) has the normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The settings window with the Kendall's monotonic correlation can be opened in Statistics menu → NonParametric tests→monotonic correlation (tau-Kendall) or in ''Wizard''.
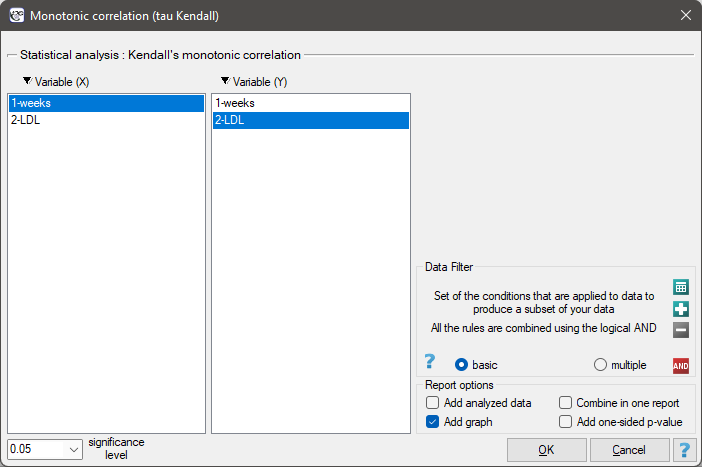
EXAMPLE cont. (LDL weeks.pqs file)
Hypotheses:
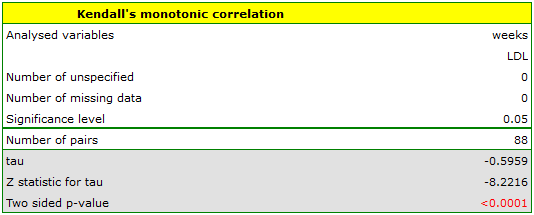
Comparing p<0.0001 with a significance level we find that there is a statistically significant monotonic relationship between treatment time and LDL levels. This relationship is initially decreasing and begins to stabilize after 150 weeks. The Kendall's monotonic correlation coefficient, and therefore the strength of the monotonic relationship for this relationship is quite high at =-0.60. The graph was plotted by curve fitting through local LOWESS linear smoothing techniques.
Contingency tables coefficients and their statistical significance
The contingency coefficients are calculated for the raw data or the data gathered in a contingency table.
The settings window with the measures of correlation can be opened in Statistics menu → NonParametric tests → Ch-square, Fisher, OR/RR option Measures of dependence… or in ''Wizard''.
The Yule's Q contingency coefficient
The Yule's  contingency coefficient (Yule, 19002)) is a measure of correlation, which can be calculated for
contingency coefficient (Yule, 19002)) is a measure of correlation, which can be calculated for  contingency tables.
contingency tables.

where:
 - observed frequencies in a contingency table.
- observed frequencies in a contingency table.
The coefficient value is included in a range of  . The closer to 0 the value of the is, the weaker dependence joins the analysed features, and the closer to
. The closer to 0 the value of the is, the weaker dependence joins the analysed features, and the closer to  1 or +1, the stronger dependence joins the analysed features. There is one disadvantage of this coefficient. It is not much resistant to small observed frequencies (if one of them is 0, the coefficient might wrongly indicate the total dependence of features).
1 or +1, the stronger dependence joins the analysed features. There is one disadvantage of this coefficient. It is not much resistant to small observed frequencies (if one of them is 0, the coefficient might wrongly indicate the total dependence of features).
The statistic significance of the Yule's coefficient is defined by the  test.
test.
Hypotheses:

The test statistic is defined by:

The test statistic asymptotically (for a large sample size) has the normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The Phi contingency coefficient is a measure of correlation, which can be calculated for contingency tables.

The  coefficient value is included in a range of
coefficient value is included in a range of  . The closer to 0 the value of is, the weaker dependence joins the analysed features, and the closer to 1, the stronger dependence joins the analysed features.
. The closer to 0 the value of is, the weaker dependence joins the analysed features, and the closer to 1, the stronger dependence joins the analysed features.
The contingency coefficient is considered as statistically significant, if the p-value calculated on the basis of the  test (designated for this table) is equal to or less than the significance level .
test (designated for this table) is equal to or less than the significance level .
The Cramer's V contingency coefficient
The Cramer's V contingency coefficient (Cramer, 19463)), is an extension of the coefficient on  contingency tables.
contingency tables.

where:
Chi-square – value of the test statistic,
 – total frequency in a contingency table,
– total frequency in a contingency table,
 – the smaller the value out of
– the smaller the value out of  and
and  .
.
The  coefficient value is included in a range of . The closer to 0 the value of is, the weaker dependence joins the analysed features, and the closer to 1, the stronger dependence joins the analysed features. The coefficient value depends also on the table size, so you should not use this coefficient to compare different sizes of contingency tables.
coefficient value is included in a range of . The closer to 0 the value of is, the weaker dependence joins the analysed features, and the closer to 1, the stronger dependence joins the analysed features. The coefficient value depends also on the table size, so you should not use this coefficient to compare different sizes of contingency tables.
The contingency coefficient is considered as statistically significant, if the p-value calculated on the basis of the test (designated for this table) is equal to or less than the significance level .
W-Cohen contingency coefficient
The  -Cohen contingency coefficient (Cohen (1988)4)), is a modification of the V-Cramer coefficient and is computable for tables.
-Cohen contingency coefficient (Cohen (1988)4)), is a modification of the V-Cramer coefficient and is computable for tables.

where:
Chi-square – value of the test statistic,
– total frequency in a contingency table,
– the smaller the value out of and .
The coefficient value is included in a range of  , where
, where  (for tables where at least one variable contains only two categories, the value of the coefficient is in the range ). The closer to 0 the value of is, the weaker dependence joins the analysed features, and the closer to
(for tables where at least one variable contains only two categories, the value of the coefficient is in the range ). The closer to 0 the value of is, the weaker dependence joins the analysed features, and the closer to  , the stronger dependence joins the analysed features. The coefficient value depends also on the table size, so you should not use this coefficient to compare different sizes of contingency tables.
, the stronger dependence joins the analysed features. The coefficient value depends also on the table size, so you should not use this coefficient to compare different sizes of contingency tables.
The contingency coefficient is considered as statistically significant, if the p-value calculated on the basis of the test (designated for this table) is equal to or less than the significance level .
The Pearson's C contingency coefficient
The Pearson's  contingency coefficient is a measure of correlation, which can be calculated for contingency tables.
contingency coefficient is a measure of correlation, which can be calculated for contingency tables.

The coefficient value is included in a range of  . The closer to 0 the value of is, the weaker dependence joins the analysed features, and the farther from 0, the stronger dependence joins the analysed features. The coefficient value depends also on the table size (the bigger table, the closer to 1 value can be), that is why it should be calculated the top limit, which the coefficient may gain – for the particular table size:
. The closer to 0 the value of is, the weaker dependence joins the analysed features, and the farther from 0, the stronger dependence joins the analysed features. The coefficient value depends also on the table size (the bigger table, the closer to 1 value can be), that is why it should be calculated the top limit, which the coefficient may gain – for the particular table size:

where:
– the smaller value out of and .
An uncomfortable consequence of dependence of value on a table size is the lack of possibility of comparison the coefficient value calculated for the various sizes of contingency tables. A little bit better measure is a contingency coefficient adjusted for the table size ( ):
):

The contingency coefficient is considered as statistically significant, if the p-value calculated on the basis of the test (designated for this table) is equal to or less than significance level .
EXAMPLE (sex-exam.pqs file)
There is a sample of 170 persons ( ), who have 2 features analysed (=sex, =passing the exam). Each of these features occurs in 2 categories (
), who have 2 features analysed (=sex, =passing the exam). Each of these features occurs in 2 categories ( =f,
=f,  =m,
=m,  =yes,
=yes,  =no). Basing on the sample, we would like to get to know, if there is any dependence between sex and passing the exam in an analysed population. The data distribution is presented in a contingency table:}
=no). Basing on the sample, we would like to get to know, if there is any dependence between sex and passing the exam in an analysed population. The data distribution is presented in a contingency table:}

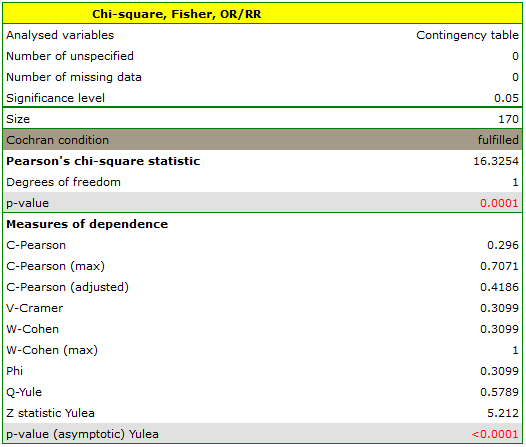
The test statistic value is  and the value calculated for it: p<0.0001. The result indicates that there is a statistically significant dependence between sex and passing the exam in the analysed population.
and the value calculated for it: p<0.0001. The result indicates that there is a statistically significant dependence between sex and passing the exam in the analysed population.
Coefficient values, which are based on the test, so the strength of the correlation between analysed features are:
-Pearson = 0.42.
-Cramer = = -Cohen = 0.31
The -Yule = 0.58, and the value of the test (similarly to test) indicates the statistically significant dependence between the analysed features.
1)
Kendall M.G. (1938), A new measure of rank correlation. Biometrika, 30, 81-93
2)
Yule G. (1900), On the association of the attributes in statistics: With illustrations from the material ofthe childhood society, and c. Philosophical Transactions of the Royal Society, Series A, 194,257-3 19
3)
Cramkr H. (1946), Mathematical models of statistics. Princeton, NJ: Princeton University Press
4)
Cohen J. (1988), Statistical Power Analysis for the Behavioral Sciences, Lawrence Erlbaum Associates, Hillsdale, New Jersey
en/statpqpl/korelpl/nparpl.txt · ostatnio zmienione: 2022/02/13 18:28 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
