Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
pl:statpqpl:porown3grpl:parpl:anova_one_waycorrpl
ANOVA dla grup niezależnych z korektą F* i F''
 Poprawki
Poprawki  (Brown-Forsythe, 19741)) oraz
(Brown-Forsythe, 19741)) oraz  (Welch, 19512)) dotyczą ANOVA dla grup niezależnych i są wyliczane wówczas, gdy nie jest spełnione założenie równości wariancji.
(Welch, 19512)) dotyczą ANOVA dla grup niezależnych i są wyliczane wówczas, gdy nie jest spełnione założenie równości wariancji.
Statystyka testowa ma postać:


gdzie:

 odchylenie standardowe grupy
odchylenie standardowe grupy  ,
,
 waga grupy ,
waga grupy ,
 średnia ważona,
średnia ważona,
 .
.
Statystyka ta podlega rozkładowi F Snedecora z  i skorygowanymi
i skorygowanymi  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość  porównujemy z poziomem istotności
porównujemy z poziomem istotności  :
:

Testy POST-HOC
Wprowadzenie do kontrastów i testów POST-HOC przeprowadzone zostało w rozdziale dotyczącym jednoczynnikowej analizy wariancji.
Dla porównań prostych i złożonych zarówno równolicznych jak i różnolicznych grup, gdy wariancje różnią się istotnie (Tamhane A. C., 19773)).
 Wartość najmniejszej istotnej różnicy wyliczana jest z wzoru:
Wartość najmniejszej istotnej różnicy wyliczana jest z wzoru:

gdzie:
 - to|wartość krytyczna (statystyka) rozkładu F Snedecora dla zmodyfikowanego poziomu istotności
- to|wartość krytyczna (statystyka) rozkładu F Snedecora dla zmodyfikowanego poziomu istotności  oraz dla stopni swobody 1 i
oraz dla stopni swobody 1 i  odpowiednio,
odpowiednio,
 ,
,

 Statystyka testowa ma postać:
Statystyka testowa ma postać:

Statystyka ta podlega rozkładowi t-Studenta z  stopniami swobody, a wartość p jest korygowana o liczbę możliwych porównań prostych.
stopniami swobody, a wartość p jest korygowana o liczbę możliwych porównań prostych.
Test BF (Brown-Forsythe)
Dla porównań prostych zarówno równolicznych jak i różnolicznych grup, gdy wariancje różnią się istotnie (Brown M. B. i Forsythe A. B. (1974)4)).
- Wartość najmniejszej istotnej różnicy wyliczana jest z wzoru:

gdzie:
 - to wartość krytyczna (statystyka) rozkładu F Snedecora dla zadanego poziomu istotności oraz i stopni swobody.
- to wartość krytyczna (statystyka) rozkładu F Snedecora dla zadanego poziomu istotności oraz i stopni swobody.
- Statystyka testowa ma postać:

Statystyka ta podlega rozkładowi F Snedecora z i stopniami swobody.
Test GH (Games-Howell).
Dla porównań prostych zarówno równolicznych jak i różnolicznych grup, gdy wariancje różnią się istotnie (Games P. A. i Howell J. F. 19765)).
- Wartość najmniejszej istotnej różnicy wyliczana jest z wzoru:

gdzie:
 - to wartość krytyczna (statystyka) rozkładu studentyzowanego rozstępu dla zadanego poziomu istotności oraz
- to wartość krytyczna (statystyka) rozkładu studentyzowanego rozstępu dla zadanego poziomu istotności oraz  i stopni swobody.
i stopni swobody.
- Statystyka testowa ma postać:

Statystyka ta podlega rozkładowi studentyzowanego rozstępu z i stopniami swobody.
Test dla trendu.
Test badający istnienie trendu może być wyliczany w takiej samej sytuacji jak ANOVA dla grup niezależnych z korektą i , gdyż bazuje na tych samych założeniach, inaczej jednak ujmuje hipotezę alternatywną - wskazując w niej na istnienie trendu wartości średnich dla kolejnych populacji. Analiza trendu w ułożeniu średnich oparta jest na kontrastach (T2 Tamhane). Budując odpowiednie kontrasty można badać dowolny rodzaj trendu np. liniowy, kwadratowy, sześcienny, itd. Tabela przykładowych wartości kontrastów dla wybranych trendów znajduje się w opisie testu dla trendu dla ANOVA bez korekty dla różnych wariancji.
Trend liniowy
Trend liniowy, tak jak pozostałe trendy, możemy analizować wpisując odpowiednie wartości kontrastów. Jeśli jednak znany jest kierunek trendu liniowego, wystarczy skorzystać z opcji Trend liniowy i wskazać oczekiwaną kolejność populacji przypisując im kolejne liczby naturalne.
Analiza przeprowadzana jest w oparciu o kontrast liniowy, czyli wskazanym według naturalnego uporządkowania grupom przypisane są odpowiednie wartości kontrastu i wyliczona zostaje statystyka T2 Tamhane.
Przy znanym oczekiwanym kierunku trendu, hipoteza alternatywna jest jednostronna i interpretacji podlega jednostronna wartość . Interpretacja dwustronnej wartości oznacza, że badacz nie zna (nie zakłada) kierunku ewentualnego trendu. Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Okno z ustawieniami opcji jednoczynnikowej ANOVA dla grup niezależnych z korektą F* i F„ wywołujemy poprzez menu Statystyka→Testy parametryczne→ANOVA dla grup niezależnych lub poprzez Kreator.
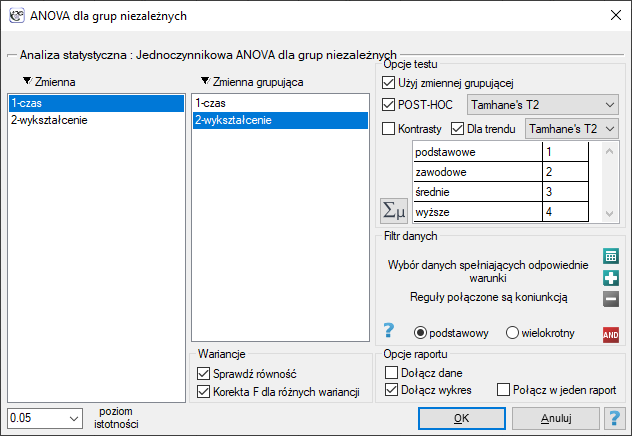
Przykład (plik bezrobocie.pqs)
Jest wiele czynników regulujących czas poszukiwania pracy w dobie kryzysu gospodarczego. Jednym z najważniejszych może być poziom wykształcenia. Przykładowe dane dotyczące wykształcenia oraz czasu (w miesiącach) pozostawania bezrobotnym zebrano w pliku. Chcemy sprawdzić czy istnieją różnice w średnim czasie poszukiwania pracy dla poszczególnych kategorii wykształcenia.
Hipotezy:

Ze względu na różnice dotyczące wariancji pomiędzy poszczególnymi populacjami (dla testu Levene wartość  , a dla testu Brown-Forsythe wartość
, a dla testu Brown-Forsythe wartość  ):
):

analizę przeprowadzamy przy włączonej korekcie różnych wariancji. Uzyskany wynik skorygowanej statystyki  jest przedstawiony poniżej.
jest przedstawiony poniżej.
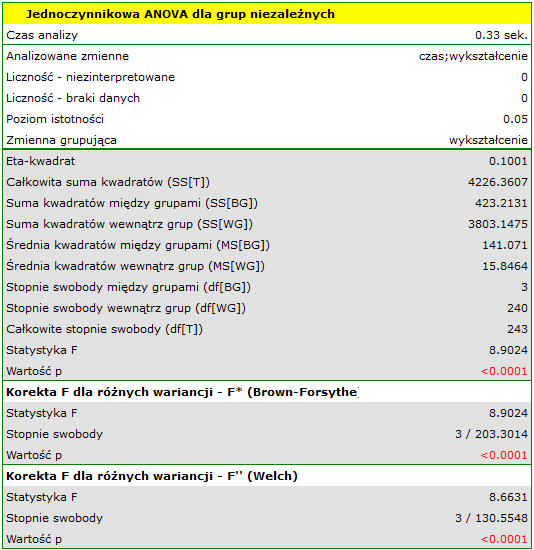
Porównując wartość  (dla testu ) oraz wartość (dla testu ) z poziomem istotności
(dla testu ) oraz wartość (dla testu ) z poziomem istotności  stwierdzamy, że średni czas poszukiwania pracy różni się w zależności od posiadanego wykształcenia. Wykonując jeden z testów POST-HOC, dedykowany porównaniu grup o różnych wariancjach, dowiadujemy się których kategorii wykształcenia dotyczą stwierdzone różnice:
stwierdzamy, że średni czas poszukiwania pracy różni się w zależności od posiadanego wykształcenia. Wykonując jeden z testów POST-HOC, dedykowany porównaniu grup o różnych wariancjach, dowiadujemy się których kategorii wykształcenia dotyczą stwierdzone różnice:
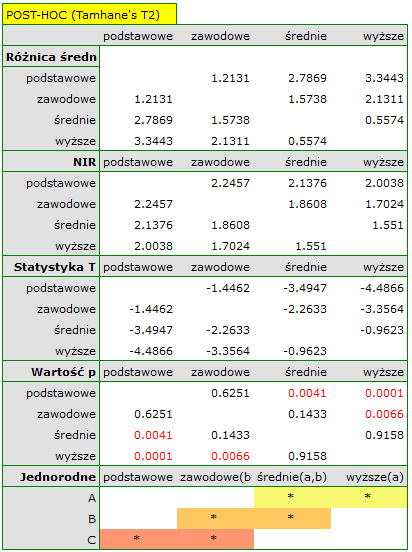
Najmniejsza istotna różnica (NIR) wyznaczona dla każdej pary porównań nie jest taka sama (mimo, że liczności grup są sobie równe), ponieważ nie są równe wariancje. Odnosząc wartość NIR do uzyskanych różnic wartości średnich uzyskamy ten sam rezultat co porównując wartość z poziomem istotności . Różnice dotyczą wykształcenia podstawowego i wyższego, wykształcenia podstawowego i średniego oraz wykształcenia zawodowego i wyższego. Powstałe grupy jednorodne zazębiają się. Generalnie jednak, spoglądając na wykres, możemy oczekiwać, że czym bardziej wykształcona osoba, tym mniej czasu zajmuje jej poszukiwanie pracy.
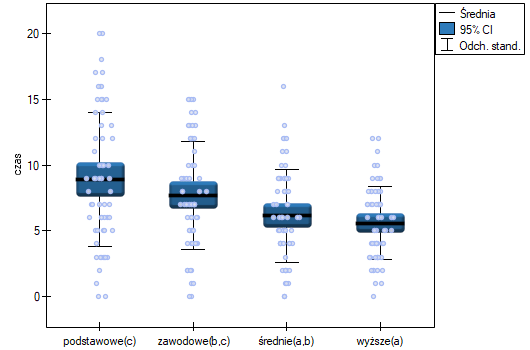
By móc sprawdzić tak postawioną hipotezę, należy podjąć analizę dla trendu. W tym celu {wznawiamy analizę} przyciskiem  i w oknie opcji testu wybieramy: metodę
i w oknie opcji testu wybieramy: metodę Tamhane's T2, opcję Kontrasy (i ustawiamy odpowiedni kontrast) lub opcję Dla trendu (i wskazujemy kolejność kategorii wykształcenia podając kolejne liczby naturalne).
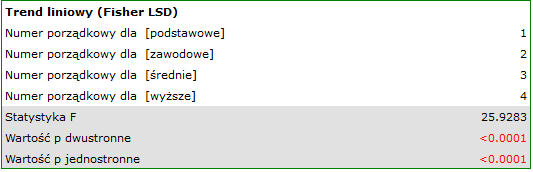
W zależności od tego czy kierunek zależności pomiędzy wykształceniem a czasem poszukiwania pracy jest nam znany, wykorzystujemy jednostronną lub dwustronną wartość . Obie te wartości są mniejsze niż zadany poziom istotności. Przewidywany przez nas trend został potwierdzony, czyli na poziomie istotności możemy powiedzieć, że ów trend istnieje rzeczywiście w populacji z której pochodzi próba.
1)
Brown M. B., Forsythe A. B. (1974), The small sample behavior of some statistics which test the equality of several means. Technometrics, 16, 385-389
2)
Welch B. L. (1951), On the comparison of several mean values: an alternative approach. Biometrika 38: 330–336
3)
Tamhane A. C. (1977), Multiple comparisons in model I One-Way ANOVA with unequal variances. Communications in Statistics, A6 (1), 15-32
4)
Brown M. B., Forsythe A. B. (1974), The ANOVA and multiple comparisons for data with heterogeneous variances. Biometrics, 30, 719-724
5)
Games P. A., Howell J. F. (1976), Pairwise multiple comparison procedures with unequal n's and/or variances: A Monte Carlo study. Journal of Educational Statistics, 1, 113-125
pl/statpqpl/porown3grpl/parpl/anova_one_waycorrpl.txt · ostatnio zmienione: 2022/02/13 11:22 (edycja zewnętrzna)
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
