Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
przestrzenpl:gestoscpl
Spis treści
Analiza gęstości
By przeprowadzić analizę gęstości powinniśmy dysponować danymi mapy zawierającej obiekty typu: punkt, wielopunkt lub wielokąt. W przypadku analizy wielokątów obliczenia oparte są na centroidach, a przypadku wielopunktów na centrach obiektów.
Metoda kwadratów
Metoda kwadratów (ang. Quadrat Count Methods).
Graficznie metoda ta jest uogólnieniem histogramu, czy analizy jednowymiarowej, na przypadek dwuwymiarowy. Budując histogram dysponujemy jedną zmienną, którą dzielimy na przedziały równej długości i podajemy liczbę przypadków w każdym przedziale. Budując siatkę kwadratów dysponujemy dwiema zmiennymi, na podstawie których budujemy siatkę i podajemy liczbę przypadków w każdym kwadracie siatki (DPS - ang. Dot Per Square). Stosunek tej liczności do pola kwadratu stanowi o intensywność barwy na jaką kolorowany jest dany kwadrat siatki.
![\begin{tabular}{|l|l|l|l|}
\hline
\cellcolor[rgb]{0.8,0.8,0.8}&\textcolor[rgb]{1,1,1}{aaa}&\cellcolor[rgb]{0.4,0.4,0.4}\textcolor[rgb]{0.4,0.4,0.4}{aa}$\bullet$&\textcolor[rgb]{1,1,1}{aaa}\\
\cellcolor[rgb]{0.8,0.8,0.8}$\bullet$&&\cellcolor[rgb]{0.4,0.4,0.4}$\bullet$&\\ \hline
\textcolor[rgb]{1,1,1}{aaa}&\textcolor[rgb]{1,1,1}{aaa}&\textcolor[rgb]{1,1,1}{aaa}&\textcolor[rgb]{0.8,0.8,0.8}{aa}\cellcolor[rgb]{0.8,0.8,0.8}$\bullet$\\
\textcolor[rgb]{1,1,1}{aaa}&\textcolor[rgb]{1,1,1}{aaa}&\textcolor[rgb]{1,1,1}{aaa}&\cellcolor[rgb]{0.8,0.8,0.8}\\ \hline
\end{tabular}](/lib/exe/fetch.php?media=wiki:latex:/img43a14f7bd3863948a5edc027448c7e7b.png "LaTeX")
Na podstawie liczby przypadków w kwadratach siatki możemy badać ich rozkład przestrzenny. Jeśli w każdym kwadracie znajduje się taka sama liczba punktów, oznacza to idealnie równomierny rozkład. Gdy jest odwrotnie, gdy zróżnicowanie liczby punków w kwadratach jest bardzo duże, oznacza to że są kwadraty o znacznie większej liczbie punktów, czyli tworzą się klastery.
Jeśli przez  oznaczymy liczbę punktów badanego obszaru, a przez
oznaczymy liczbę punktów badanego obszaru, a przez  liczbę kwadratów na jaki badany obszar zostaje podzielony, wówczas można wyznaczyć średnią, wariancję i odchylenie standardowe liczby punktów na kwadrat:
liczbę kwadratów na jaki badany obszar zostaje podzielony, wówczas można wyznaczyć średnią, wariancję i odchylenie standardowe liczby punktów na kwadrat:
 gdzie
gdzie  - to liczba kwadratów z liczbą punktów równą
- to liczba kwadratów z liczbą punktów równą  .
.
Współczynnik 
Najważniejszą informacje niesie współczynnik będący ilorazem wariancji i średniej (ang. variance-mean ratio):
 Wartość
Wartość  wskazuje na zbyt małe zróżnicowanie liczby punktów w kwadratach co sugeruje efekt równomiernego rozproszenia,
wskazuje na zbyt małe zróżnicowanie liczby punktów w kwadratach co sugeruje efekt równomiernego rozproszenia,  oznacza zbyt duże zróżnicowanie liczby punktów w kwadratach a więc efekt klasteryzacji, a wartość bliska 1 wskazuje na przeciętne zróżnicowanie liczby punktów w kwadratach co oznacza losowość rozkładu punktów.
oznacza zbyt duże zróżnicowanie liczby punktów w kwadratach a więc efekt klasteryzacji, a wartość bliska 1 wskazuje na przeciętne zróżnicowanie liczby punktów w kwadratach co oznacza losowość rozkładu punktów.
W literaturze często rozważany jest wskaźnik wielkości klasterów (ang. Index of Cluster Size - ICS):
 Oczekiwana wartość
Oczekiwana wartość  przy założeniu losowości punktów wynosi 0. Wartość dodatnia wskazuje na efekt klasteryzacji, a ujemna na regularny rozkład punktów.
przy założeniu losowości punktów wynosi 0. Wartość dodatnia wskazuje na efekt klasteryzacji, a ujemna na regularny rozkład punktów.
Istotności współczynnika
Test sprawdzający istotność współczynnika służy do weryfikacji hipotezy o tym, że obserwowane liczności punktów w kwadratach są takie same jak oczekiwane liczności, które pojawiłyby się dla losowego rozkładu punktów.
Hipotezy:

Statystyka testowa ma postać:
 Statystyka ta ma asymptotycznie rozkład chi-kwadrat z
Statystyka ta ma asymptotycznie rozkład chi-kwadrat z  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość  porównujemy z poziomem istotności
porównujemy z poziomem istotności  :
:

Uwaga!
Uzyskany wynik analizy w znacznym stopniu zależy od gęstości siatki a więc od liczby/wielkości kwadratów na jakie dzielony jest analizowany obszar. W oknie opcji testu można ustawić siatkę, jaka będzie użyta do podziału badanego obszaru na kwadraty, podając liczbę kwadratów w pionie i w poziomie.
Okno z ustawieniami opcji metody kwadratów wywołujemy poprzez menu Analiza przestrzenna→Statystyki przestrzenne→Metoda kwadratów
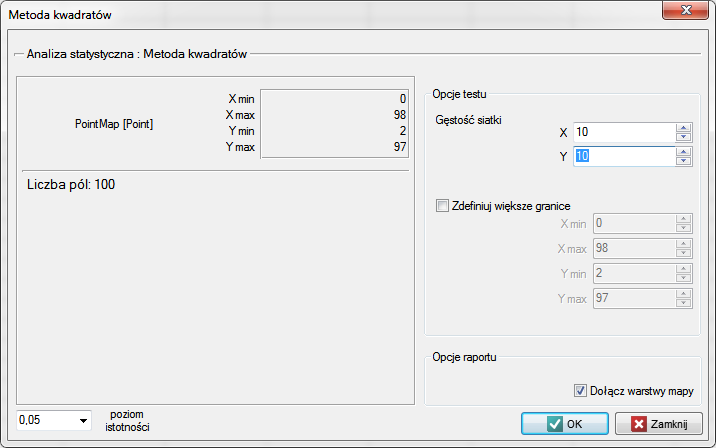
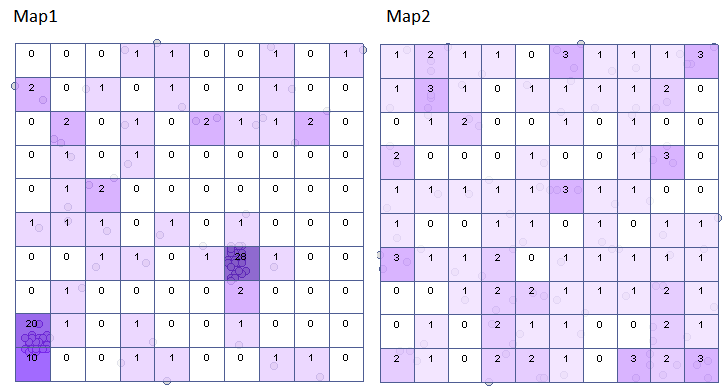
Na podstawie arkusza danych wygeneruj dwie mapy punktów i wykonaj analizę gęstości tych punktów. Odpowiedz na pytanie: Czy punkty są rozłożone losowo w każdej z tych map?
Mapy punktów tworzymy przy pomocy formuł: menu Dane→Formuły…
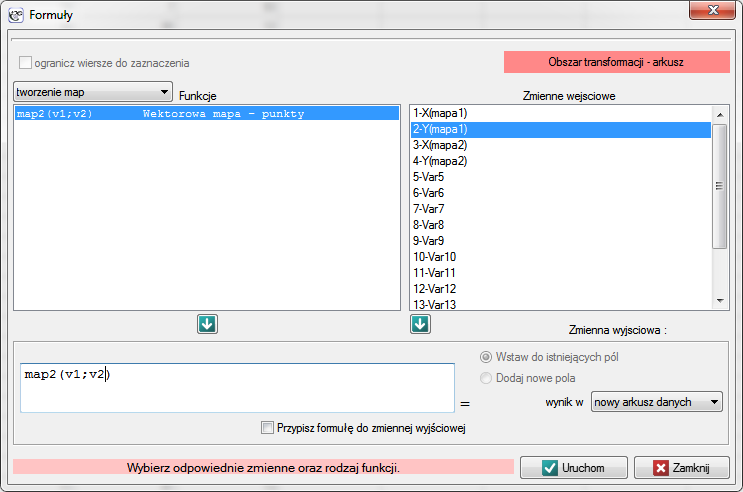
W rezultacie uzyskamy dwa nowe arkusze zawierające mapy. Dla każdego z tych arkuszy przeprowadzamy analizę kwadratów.
Hipotezy:

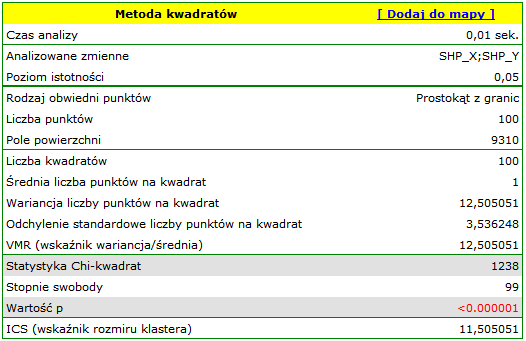
Wyniki dla mapy 1 wskazują na znaczne zróżnicowanie liczby punktów w kwadratach, czyli na efekt klasteryzacji (wartość  ). Efekt ten utrzymuje się dla różnych gęstości siatki. Dla siatki gęstości 10:10 współczynnik
). Efekt ten utrzymuje się dla różnych gęstości siatki. Dla siatki gęstości 10:10 współczynnik  wynosi aż 12.5, cały raport został zamieszczony poniżej:
wynosi aż 12.5, cały raport został zamieszczony poniżej:
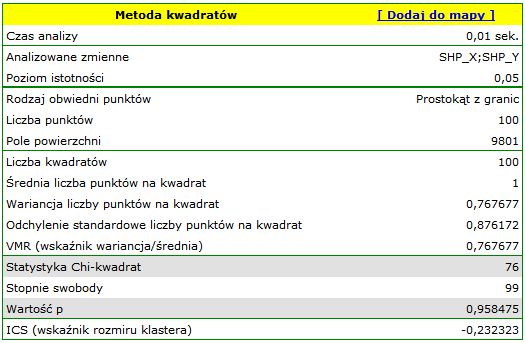
Dla mapy 2 sytuacja jest zupełnie inna. Dla siatki gęstości 10:10 mamy brak istotności statystycznej (wartość  ) oraz wartość współczynnika
) oraz wartość współczynnika  wskazują na losowość rozkładu punktów.
wskazują na losowość rozkładu punktów.
Wykorzystując przycisk  umieszczony w raporcie przenosimy się do Menadżera map by z wyświetlonej listy warstw wybrać wykonaną siatkę analizy kwadratów i uzyskać graficzną interpretację wyników.
umieszczony w raporcie przenosimy się do Menadżera map by z wyświetlonej listy warstw wybrać wykonaną siatkę analizy kwadratów i uzyskać graficzną interpretację wyników.
Jądrowy estymator gęstości
Dwuwymiarowy estymator jądrowy
Dwuwymiarowy estymator jądrowy (podobnie jak estymator jednowymiarowy) pozwala na przybliżenie rozkładu danych, wyrażonego metodą kwadratów, poprzez wygładzenie.
Dwuwymiarowy jądrowy estymator gęstości przybliża gęstość rozkładu danych tworząc wygładzoną płaszczyznę gęstości w sposób nieparametryczny. Dzięki niemu uzyskuje się lepszą estymację gęstości niż daje tradycyjna metoda kwadratów, której kwadraty tworzą funkcję schodkową. Tak jak w przypadku jednowymiarowym estymator ten definiowany jest w oparciu o odpowiednio wygładzone zsumowane funkcje jądra (patrz opis w Podręczniku Użytkownika PQStat). Do wyboru mamy kilka sposobów wygładzania oraz kilka funkcji jądra opisanych dla estymatora jednowymiarowego (Gaussa, jednostajna, trójkątna, Epanechnikova, quartic/biweight). O ile funkcja jądra nie ma dużego wpływu na uzyskane wygładzenie płaszczyzny, o tyle współczynnik wygładzania tak.
Dla każdego punktu  z zakresu określonego przez dane wyznacza się gęstość czyli estymator jądrowy. Powstaje on poprzez zsumowanie iloczynu wartości funkcji jąder w tym punkcie:
z zakresu określonego przez dane wyznacza się gęstość czyli estymator jądrowy. Powstaje on poprzez zsumowanie iloczynu wartości funkcji jąder w tym punkcie:

Jeśli poszczególnym przypadkom nadamy wagi  , wówczas możemy zbudować ważony jądrowy estymator gęstości definiowany wzorem:
, wówczas możemy zbudować ważony jądrowy estymator gęstości definiowany wzorem:

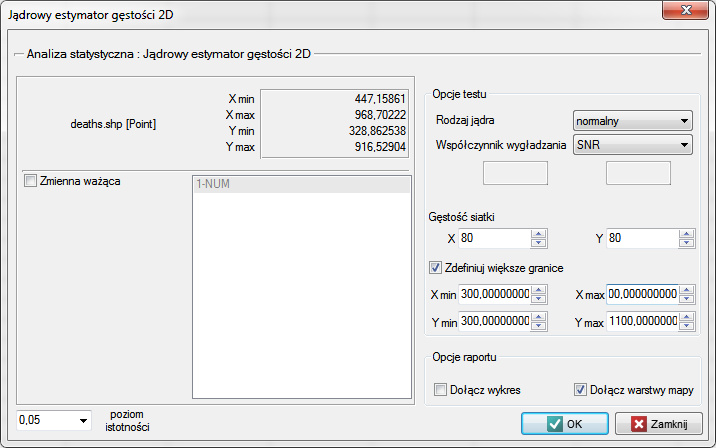
Okno z ustawieniami opcji jądrowego estymatora gęstości 2D wywołujemy poprzez menu Analiza przestrzenna→Statystyki przestrzenne→Jądrowy estymator gęstości 2D
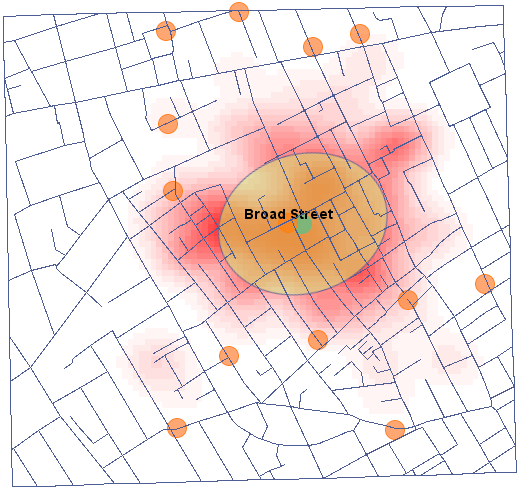
Przykład c.d. (plik snow.pqs)
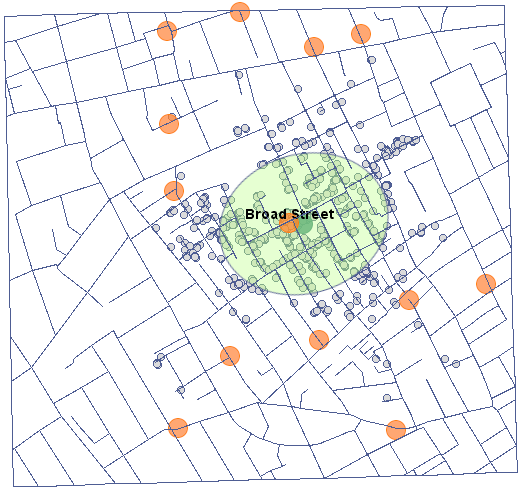
Obecnie zasadniczym problemem w przedstawianiu danych punktowych dotyczących lokalizacji osób jest konieczność ich ochrony. Ochrona danych osobowych zabrania takiego publikowania wyników badań, by na ich podstawie można było rozpoznać daną osobę, nie można więc m.in. publikować mapy w postaci punktów z zaznaczonym miejscem zamieszkania. Dobrym rozwiązaniem w takim przypadku jest estymator gęstości punktów.
Przedstawimy dane punktowe obrazujące epidemię cholery w Londynie w roku 1854 przy pomocy takiego estymatora. W tym celu posłużymy się mapą punktów (śmierci z powodu cholery) z nałożonymi już warstwami ilustrującymi zarówno ulice jak i pompy wodne oraz wynik analizy lekarza Johna Snow.
W oknie analizy dla mapy punktów pozostaniemy przy jądrze rozkładu Gauss'a (normalnego) i współczynniku wygładzania SNR. Gęstość siatki ustawimy na 80:80. Granice zwiększymy tak, by brzegi nie odznaczały się ostrą krawędzią wpisując 300 jako wartość minimalną współrzędnej X i Y oraz 1100 jako wartość maksymalną.
Korzystając z przycisku umieszczonego w raporcie udajemy się do Menadżera map, gdzie możemy dodać warstwę przedstawiającą ten estymator (ostatnia pozycja z listy warstw).
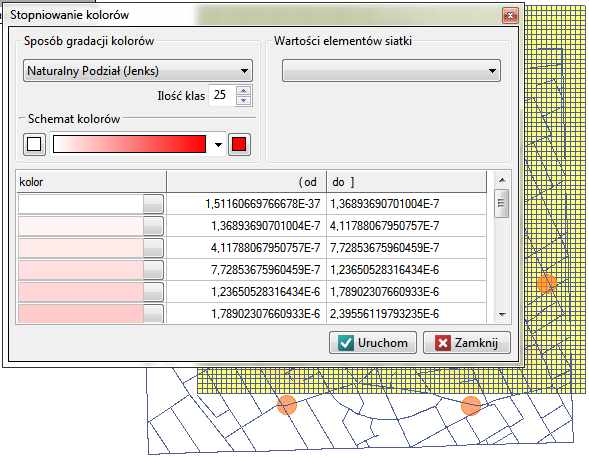
Po nałożeniu warstwy jądrowego estymatora gęstości należy go edytować  by usunąć linie siatki i zmienić kolor żółty na naturalny kolor tła (w tym przypadku biały). Tak uzyskaną warstwę przenosimy w górę
by usunąć linie siatki i zmienić kolor żółty na naturalny kolor tła (w tym przypadku biały). Tak uzyskaną warstwę przenosimy w górę  , tak by została wyrysowana na początku. Warstwę punktów (Mapa bazowa) wyłączamy.
, tak by została wyrysowana na początku. Warstwę punktów (Mapa bazowa) wyłączamy.
Przykład c.d. (plik kwadraty.pqs)
Przy pomocy estymatora jądrowego przedstawimy gęstość punktów dla mapy 1 - uzyskanej we wcześniejszej części zadania.
W oknie analizy ustawiamy gęstość siatki na 50:50 i typ jądra jako rozkład normalny oraz dołączamy wykres. Wykonujemy analizę trzy razy zmieniając przy tym współczynnik wygładzania Użytkownika: h (10:10), następnie h (10:20) i h (20:20). Uzyskane wyniki zaprezentowane na mapie (poprzez Menadżer map) i na wykresie 3D przedstawiono poniżej:
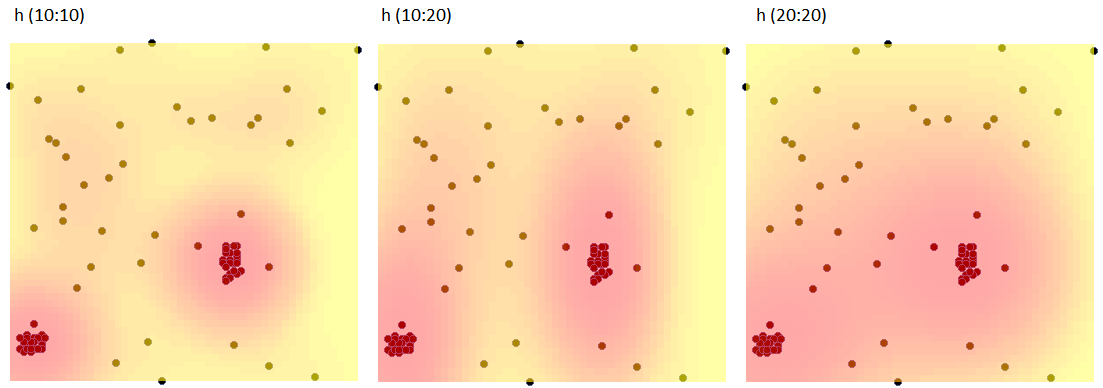
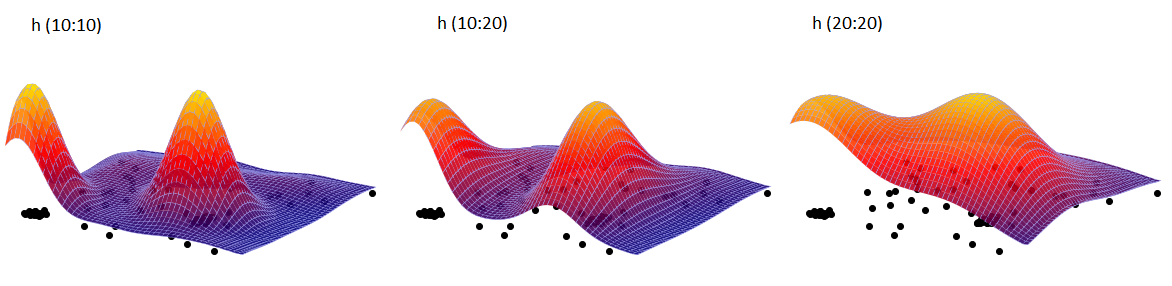
Trójwymiarowy estymator jądrowy
Trójwymiarowy estymator jądrowy (podobnie jak estymator jednowymiarowy i estymator dwuwymiarowy) pozwala na przybliżenie rozkładu danych poprzez ich wygładzenie.
Trójwymiarowy jądrowy estymator gęstości przybliża gęstość rozkładu danych tworząc wygładzoną płaszczyznę gęstości w sposób nieparametryczny. Graficznie możemy go przedstawić wyrysowując dwa pierwsze wymiary w warstwach stworzonych przez wymiar trzeci. Tak jak w przypadku jednowymiarowym (patrz opis w Podręczniku Użytkownika PQStat) i dwuwymiarowym estymator ten definiowany jest w oparciu o odpowiednio wygładzone zsumowane funkcje jądra. Do wyboru mamy kilka sposobów wygładzania oraz kilka funkcji jądra opisanych dla estymatora jednowymiarowego (Gaussa, jednostajna, trójkątna, Epanechnikova, quartic/biweight). O ile funkcja jądra nie ma dużego wpływu na uzyskane wygładzenie płaszczyzny, o tyle współczynnik wygładzania tak.
Dla każdego punktu z zakresu określonego przez dane wyznacza się gęstość czyli estymator jądrowy. Powstaje on poprzez zsumowanie iloczynu wartości funkcji jąder w tym punkcie:

Jeśli poszczególnym przypadkom nadamy wagi , wówczas możemy zbudować ważony jądrowy estymator gęstości definiowany wzorem:

Okno z ustawieniami opcji jądrowego estymatora gęstości 3D wywołujemy poprzez menu Analiza przestrzenna→Statystyki przestrzenne→Jądrowy estymator gęstości 3D
Uwaga!
Wyświetlanie kolejnych warstw estymatora, wyznaczonych przez trzeci wymiar, możliwe jest w poprzez edycję warstwy w oknie menadżera map i wybranie odpowiedniego indeksu warstwy.
przestrzenpl/gestoscpl.txt · ostatnio zmienione: 2015/01/03 00:51 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
