Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
przestrzenpl:lokalpl
Spis treści
Statystyki lokalne i wyszukiwanie klasterów
W analizie lokalnej staramy się zdefiniować klastery poprzez ich lokalizację rozmiar i intensywność. Klaster rozumiany jest tu jako ograniczone skupisko obiektów o pewnej intensywności zlokalizowane w przestrzeni i/lub czasie, dla którego przypadkowe pojawienie się jest bardzo mało prawdopodobne. Jeśli więc zidentyfikujemy skupisko, które nie jest dziełem przypadku - a zatem istotny statystycznie klaster, wówczas możemy dociekać przyczyn jego powstania.
Statystyka lokalna I Morana
Lokalna wersja statystyki Morana jest najbardziej popularną analizą określaną jako LISA (Local Indicators of Spatial Association) (Luc Anselin 19951)). W odróżnieniu od globalnej statystyki Morana wyznacza ona lokalną autokorelację przestrzenną, a zatem określa podobieństwo jednostki przestrzennej wobec sąsiadów i bada istotność statystyczną tej zależności.
Lokalny współczynnik autokorelacji Morana
Lokalna postać współczynnika  Morana dla obserwacji
Morana dla obserwacji  określona jest wzorem:
określona jest wzorem:

gdzie:
 – liczba obiektów przestrzennych (liczba punktów lub wielokątów),
– liczba obiektów przestrzennych (liczba punktów lub wielokątów),
 ,
,  – to wartości zmiennej dla porównywanych obiektów,
– to wartości zmiennej dla porównywanych obiektów,
 – to średnia wartość zmiennej dla wszystkich obiektów,
– to średnia wartość zmiennej dla wszystkich obiektów,
 – elementy przestrzennej macierzy wag (zalecana jest macierz standaryzowana rzędami do jedynki),
– elementy przestrzennej macierzy wag (zalecana jest macierz standaryzowana rzędami do jedynki),
 – wariancja
– wariancja
Interpretacja lokalnego współczynnika Morana jest analogiczna do jego globalnego odpowiednika jednak w znacznym stopniu zależy od wybranej macierzy wag. Najczęściej wagi niezerowe są przypisywane tylko do obiektów sąsiadujących, w rezultacie współczynnik lokalny określa podobieństwo jedynie obiektów znajdujących się w strefie sąsiedztwa. Standaryzacja rzędami do jedynki ułatwia natomiast porównywanie wartości współczynników uzyskanych dla różnych obiektów, gdyż wartość oczekiwana dla każdego współczynnika jest wówczas taka sama.
Wysokie wartości współczynnika wskazują na występowanie klasterów podobnych wartości, niskie - na występowanie tzw. hot spots, a wartości bliskie wartości oczekiwanej  na losowy rozkład badanej zmiennej w przestrzeni.
na losowy rozkład badanej zmiennej w przestrzeni.
Wartość oczekiwana określona jest wzorem:

Istotność współczynnika autokorelacji Morana
Testując istotność statystyczną związku między sąsiadującymi obiektami bada się hipotezy:

Statystyka testowa ma postać:

gdzie:
 – wariancja w rozkładzie losowym,
– wariancja w rozkładzie losowym,
 ,
,
 – suma kwadratu wag dla wiersza ,
– suma kwadratu wag dla wiersza ,
 - suma możliwych iloczynów wag dla wiersza po wykluczeniu iloczynów o tych samych indeksach.
- suma możliwych iloczynów wag dla wiersza po wykluczeniu iloczynów o tych samych indeksach.
Statystyka  ma asymptotycznie (dla dużych liczności) rozkład normalny.
ma asymptotycznie (dla dużych liczności) rozkład normalny.
Wartość  , wyznaczoną na podstawie statystyki testowej, porównujemy z poziomem istotności
, wyznaczoną na podstawie statystyki testowej, porównujemy z poziomem istotności  :
:

Ze względu na problem braku niezależności współczynników wyliczanych dla sąsiednich obiektów sugeruje się stosowanie skorygowanego poziomu istotności . Proponowane poprawki to: poprawka Bonferroniego:  lub Sidaka:
lub Sidaka:  , gdzie
, gdzie  jest średnią liczbą sąsiadów.
jest średnią liczbą sąsiadów.
Warstwy mapy
Kombinacja informacji z wykresu punktowego Morana (podział obiektów na High-High, Low-Low, Low-High, High-Low) i z istotności statystyki lokalnej Morana przedstawia na mapie tzw. reżimy przestrzenne:
- Istotne statystycznie obiekty High-High (obiekty o wysokich wartościach otoczone przez obiekty o wysokich wartościach) zaznaczone są na mapie kolorem czerwonym;
- Istotne statystycznie obiekty Low-Low (obiekty o niskich wartościach otoczone przez obiekty o niskich wartościach) zaznaczone są na mapie kolorem niebieskim;
- Istotne statystycznie obiekty Low-High (obiekty o niskich wartościach otoczone przez obiekty o wysokich wartościach) zaznaczone są na mapie kolorem jasno-niebieskim;
- Istotne statystycznie obiekty High-Low (obiekty o wysokich wartościach otoczone przez obiekty o niskich wartościach) zaznaczone są na mapie kolorem jasno-czerwonym.
Okno z ustawieniami opcji lokalnej analizy Morana wywołujemy poprzez menu Analiza przestrzenna → Statystyki przestrzenne → Statystyka lokalna I Morana.
Przykład c.d. (katalog: leukemia, plik: leukemia)
Analizie poddamy dane dotyczące białaczki.
- Mapa
leukemiazawiera informacje o lokalizacji 281 wielokątów (regionów spisowych) w północnej części stanu New York. - Dane do mapy
leukemia:- Kolumna
CASES– liczba przypadków białaczki w latach 1978-1982 przypisana do poszczególnych obiektów (regionów spisowych). Wartość ta powinna być liczbą całkowitą, tu jednak, zgodnie z opisem Wallera (1994) część przypadków, która nie mogła zostać obiektywnie przypisana do konkretnego regionu, została podzielona proporcjonalnie. Stąd liczności przypadków przypisanych do 281 obiektów nie są liczbami całkowitymi. - Kolumna
POP– liczność populacji w poszczególnych obiektach. - Kolumna
prev– współczynnik częstości występowania białaczki na 100000 osób, dla każdego obiektu w jednym roku: prev=(CASES/POP)*100000/5
Analiza globalna nie dała jednoznacznego rozstrzygnięcia co do występowania autokorelacji przestrzennej. Sprawdzimy więc, czy uda się znaleźć regiony, gdzie częstość występowania białaczki jest nieprzeciętnie wyższa.
By zlokalizować skupiska białaczki oraz regiony kontrastujące z otoczeniem pod względem częstości występowania tej choroby, wyliczymy lokalny współczynnik Morana. Do analizy wykorzystamy zmienną prev oraz proponowaną przez program macierz sąsiedztwa według wspólnej granicy – Queen, standaryzowaną rzędami (by wykorzystać inną macierz należy ją najpierw wygenerować- patrz rozdział: Macierz wag przestrzennych). Wybieramy również jedną z poprawek poziomu istotności.

Uzyskany raport przedstawia wartości lokalnych współczynników, wartości statystyki testowej oraz odpowiadające im wartości prawdopodobieństwa testowego. Znajdziemy tu również informacje o ilości rejonów wyznaczających reżimy przestrzenne (High-High, Low-Low, Low-High, High-Low).
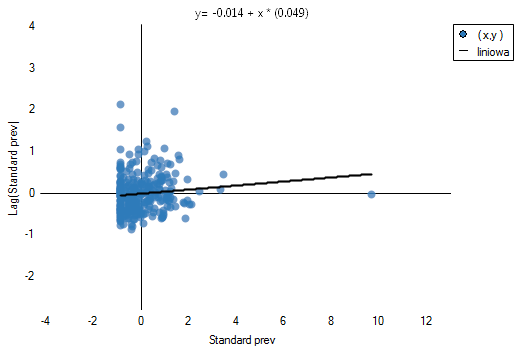
Do analizy przypisany jest także wynik, który możemy wyrysować na mapie (przycisk  ) - są to reżimy przestrzenne opisane w raporcie poprzez kolumnę kolor.
) - są to reżimy przestrzenne opisane w raporcie poprzez kolumnę kolor.
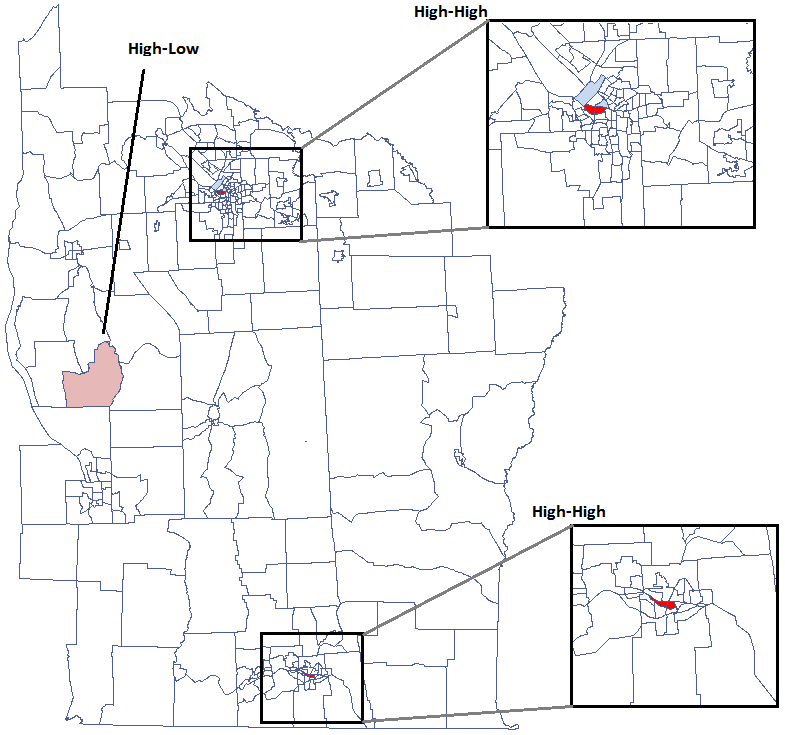
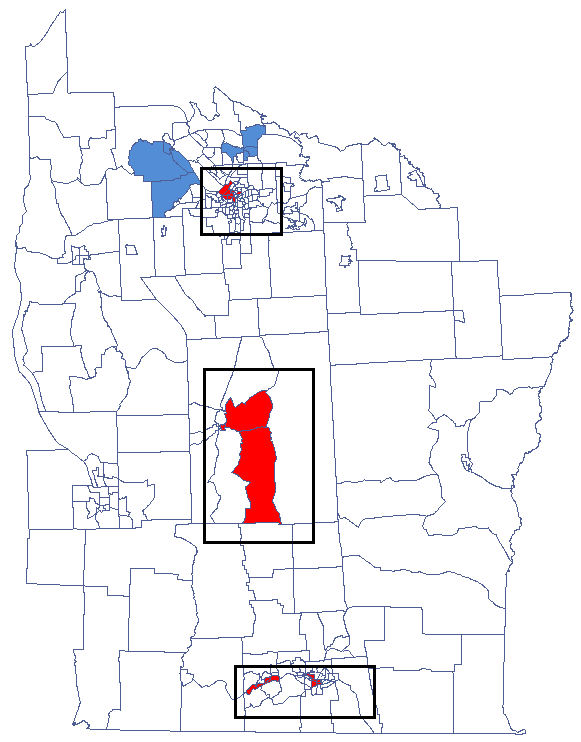
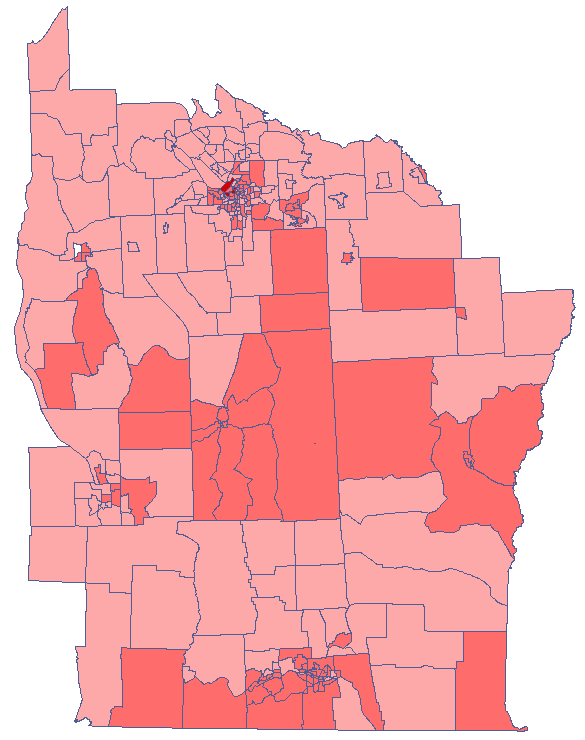
Udało się zlokalizować niewielkie ale istotne skupiska gdzie częstość występowania białaczki jest wyższa. Kolorem czerwonym oznaczone są 2 skupiska (4 regiony spisowe) leżące w mniejszych i bardziej zaludnionych regionach - są to centra klasterów wysokich wartości białaczki. Kolorem jasno-czerwonym oznaczony jest 1 region spisowy o wysokich wartościach współczynnika określającego częstość zachorowania na białaczkę. Region ten jest regionem kontrastującym wobec sąsiednich regionów spisowych, które charakteryzują się stosunkowo niskim współczynnikiem.
Uzyskane wyniki możemy dodatkowo zobrazować kolorując mapę wartościami lokalnego współczynnika Morana  lub też wartościami statystyki testowej bądź wartościami . Wystarczy jedynie wcześniej przekopiować odpowiednie kolumny z raportu do arkusza danych. W tym przykładzie do kolorowania wykorzystamy wartości statystyki testowej
lub też wartościami statystyki testowej bądź wartościami . Wystarczy jedynie wcześniej przekopiować odpowiednie kolumny z raportu do arkusza danych. W tym przykładzie do kolorowania wykorzystamy wartości statystyki testowej  . Po wklejeniu jej do pustej kolumny arkusza danych, w menadżerze map kolorujemy mapę bazową zgodnie z wartościami tej kolumny wybierając odchylenie standardowe o współczynniku 3 jako sposób gradacji kolorów. Dodatnie i wysokie wartości statystyki wskazują na występowanie klasterów podobnych wartości, ujemne i niskie - na występowanie tzw. hot spots. Wartości bliskie 0 wskazują natomiast na losowy rozkład badanej wartości w przestrzeni.
. Po wklejeniu jej do pustej kolumny arkusza danych, w menadżerze map kolorujemy mapę bazową zgodnie z wartościami tej kolumny wybierając odchylenie standardowe o współczynniku 3 jako sposób gradacji kolorów. Dodatnie i wysokie wartości statystyki wskazują na występowanie klasterów podobnych wartości, ujemne i niskie - na występowanie tzw. hot spots. Wartości bliskie 0 wskazują natomiast na losowy rozkład badanej wartości w przestrzeni.
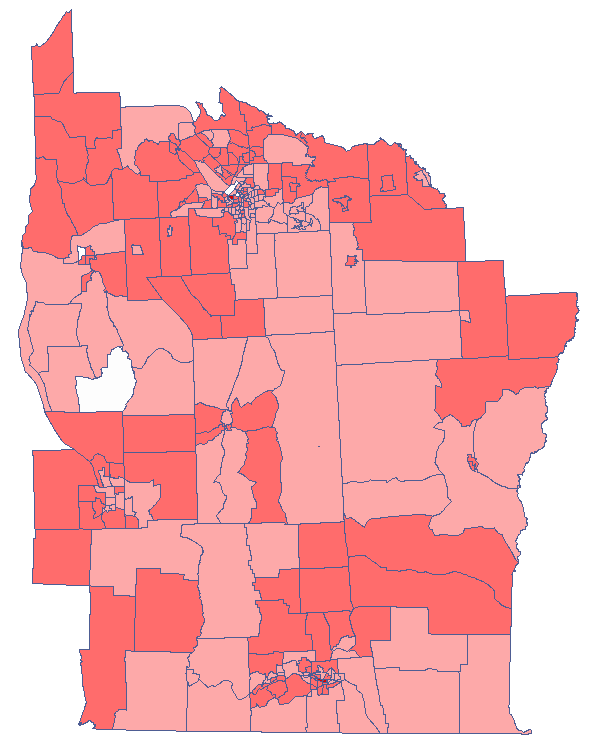
Analizując wygładzoną zmienną prev wzmacniamy efekt klasteryzacji. Uzyskujemy podobny rezultat, ale tym razem lokalizujemy 3 skupiska (19 regionów spisowych) będące centrami klasterów.

Statystyka lokalna Getisa i Orda
Statystyka lokalna  Getisa i Orda (Getis i Ord 1992 Ordi Getis 1995) umożliwia wykrywanie lokalnej koncentracji wartości wysokich i niskich w sąsiadujących obiektach oraz bada istotność statystyczną tej zależności. Getis i Ord zdefiniował również bliźniaczą do statystykę
Getisa i Orda (Getis i Ord 1992 Ordi Getis 1995) umożliwia wykrywanie lokalnej koncentracji wartości wysokich i niskich w sąsiadujących obiektach oraz bada istotność statystyczną tej zależności. Getis i Ord zdefiniował również bliźniaczą do statystykę  , która różni się od jedynie tym, że obiekt dla którego wykonuje się badanie również bierze udział w analizie. W macierzy wag jest więc zdefiniowane dla niego sąsiedztwo z samym sobą tzw. potencjał (wartości na przekątnej są większe od 0).
, która różni się od jedynie tym, że obiekt dla którego wykonuje się badanie również bierze udział w analizie. W macierzy wag jest więc zdefiniowane dla niego sąsiedztwo z samym sobą tzw. potencjał (wartości na przekątnej są większe od 0).
Lokalny współczynnik autokorelacji Getisa i Orda
Lokalna postać współczynnika  Getisa i Orda dla obserwacji określona jest wzorem:
Getisa i Orda dla obserwacji określona jest wzorem:

Współczynnik zdefiniowany jest tym samym wzorem, lecz obliczenia przeprowadzane są również dla obiektu badanego czyli obiektu, dla którego indeksy oraz  są sobie równe.
są sobie równe.
Ponieważ współczynnik bazuje na ilorazie dwóch sum wartości obiektów (), dla poprawnej interpretacji współczynnika ważne jest by analizowane zjawisko opisane było za pomocą liczb dodatnich. Interpretacja lokalnego współczynnika Getisa i Orda, podobnie jak lokalnego współczynnika Morana, w znacznym stopniu zależy od wybranej macierzy wag (zaleca się standaryzację macierzy rzędami do jedynki). Wysokie wartości współczynnika lub świadczą o skoncentrowaniu obiektów o wysokich wartościach analizowanego zjawiska, natomiast wartości niskie świadczą o skupisku obiektów o niskich wartościach. Gdy wartości są bliskie wartości oczekiwanej, wówczas rozkład badanej wartości w przestrzeni jest losowy.
Wartość oczekiwana określona jest wzorem:


Istotność współczynnika Getisa i Orda
Testując istotność statystyczną związku między sąsiadującymi obiektami bada się hipotezy:

Statystyka testowa ma postać:


gdzie:
 i
i  - średnia zmiennej
- średnia zmiennej  ,
,
 i
i  - wariancja zmiennej .
- wariancja zmiennej .
Statystyka ma asymptotycznie (dla dużych liczności) rozkład normalny.
Wartość , wyznaczoną na podstawie statystyki testowej, porównujemy z poziomem istotności :
Ze względu na problem braku niezależności współczynników wyliczanych dla sąsiednich obiektów sugeruje się stosowanie skorygowanego poziomu istotności . Proponowane poprawki to: poprawka Bonferroniego: lub Sidaka: , gdzie jest średnią liczbą sąsiadów.
Warstwy mapy
Kombinacja informacji z wielkości statystyki testowej oraz jej istotności przedstawia na mapie tzw. reżimy przestrzenne:
- Istotne statystycznie obiekty o wysokich wartościach statystyki oznaczone są jako High-High (obiekty o wysokich wartościach otoczone przez obiekty o wysokich wartościach) i zaznaczone na mapie kolorem czerwonym;
- Istotne statystycznie obiekty o niskich wartościach statystyki oznaczone są jako Low-Low (obiekty o niskich wartościach otoczone przez obiekty o niskich wartościach) i zaznaczone na mapie kolorem niebieskim.
Okno z ustawieniami opcji lokalnej analizy Getisa i Orda wywołujemy poprzez menu Analiza przestrzenna → Statystyki przestrzenne → Statystyka lokalna <latex>$G_i$</latex> Getisa i Orda.
Przykład c.d. (katalog: leukemia, plik: leukemia)
Analizie poddamy dane dotyczące białaczki.
- Mapa
leukemiazawiera informacje o lokalizacji 281 wielokątów (regionów spisowych (ang.census tracts)) w północnej części stanu New York. - Dane do mapy
leukemia:- Kolumna
CASES– liczba przypadków białaczki w latach 1978-1982 przypisana do poszczególnych obiektów (regionów spisowych). Wartość ta powinna być liczbą całkowitą, tu jednak, zgodnie z opisem Wallera (1994) część przypadków, która nie mogła zostać obiektywnie przypisana do konkretnego regionu, została podzielona proporcjonalnie. Stąd liczności przypadków przypisanych do 281 obiektów nie są liczbami całkowitymi. - Kolumna
POP– liczność populacji w poszczególnych obiektach. - Kolumna
prev– współczynnik częstości występowania białaczki na 100000 osób, dla każdego obiektu w jednym roku: prev=(CASES/POP)*100000/5
Analiza globalna nie dała jednoznacznego rozstrzygnięcia co do występowania autokorelacji przestrzennej. Sprawdzimy więc, czy uda się znaleźć regiony, gdzie częstość występowania białaczki jest nieprzeciętnie wyższa.
By zlokalizować skupiska białaczki wyliczymy współczynnik oraz  . Do analizy wykorzystamy zmienną
. Do analizy wykorzystamy zmienną prev oraz proponowaną przez program macierz sąsiedztwa według wspólnej granicy – Queen, standaryzowaną rzędami (by wykorzystać inną macierz należy ją najpierw wygenerować - patrz rozdział: Macierz wag przestrzennych). Wybieramy również jedną z poprawek poziomu istotności.


Uzyskany raport przedstawia wartości lokalnych współczynników, wartości statystyki testowej oraz odpowiadające im wartości prawdopodobieństwa testowego. Znajdziemy tu również informacje o ilości rejonów wyznaczających reżimy przestrzenne (High-High, Low-Low).
Do analizy przypisany jest także wynik, który możemy wyrysować na mapie (przycisk ) - są to reżimy przestrzenne opisane w raporcie poprzez kolumnę kolor.
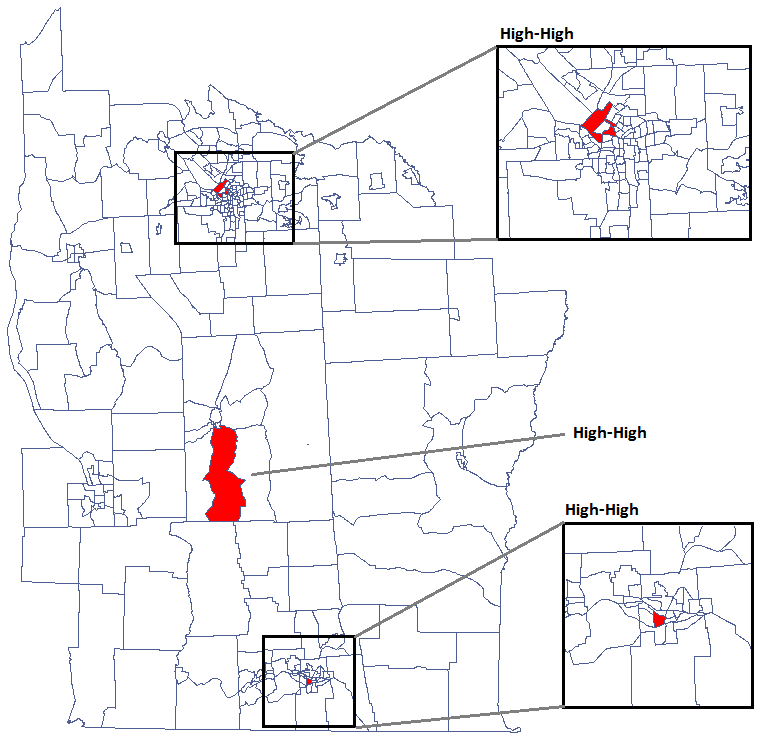
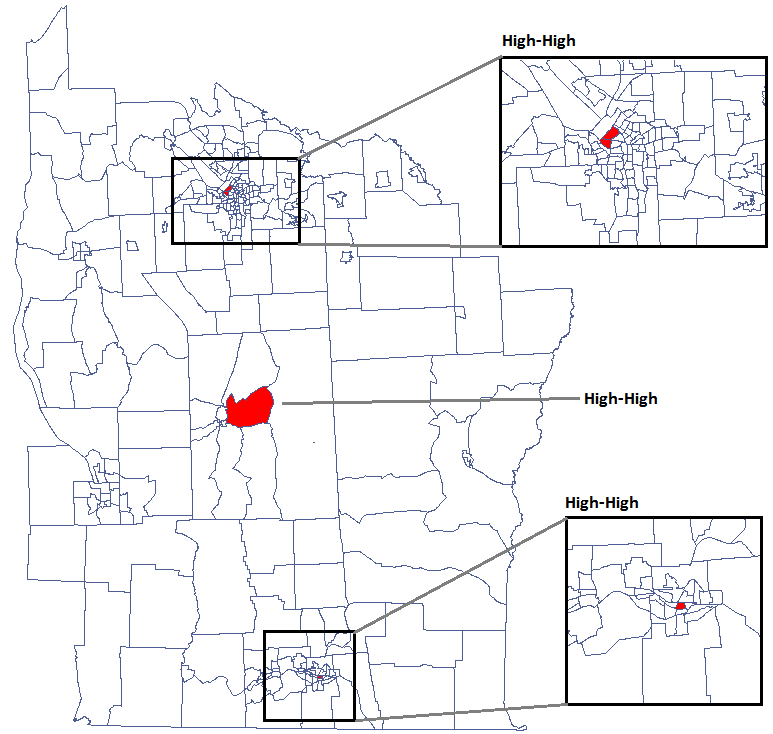
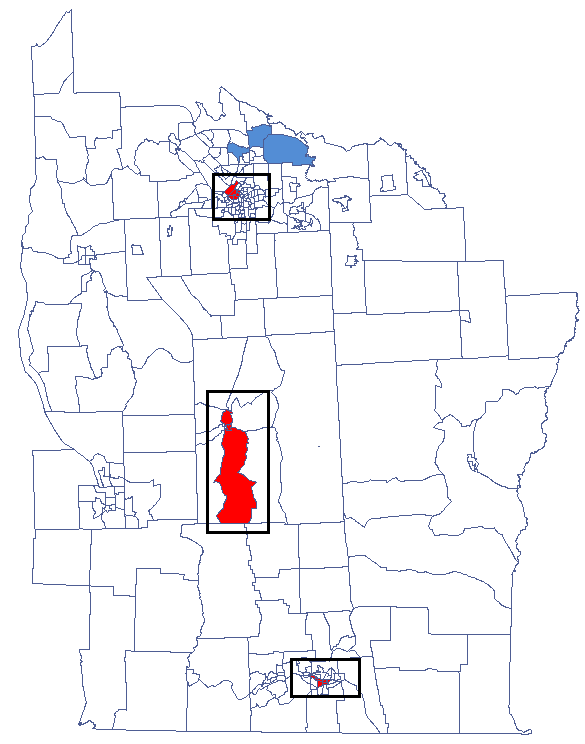
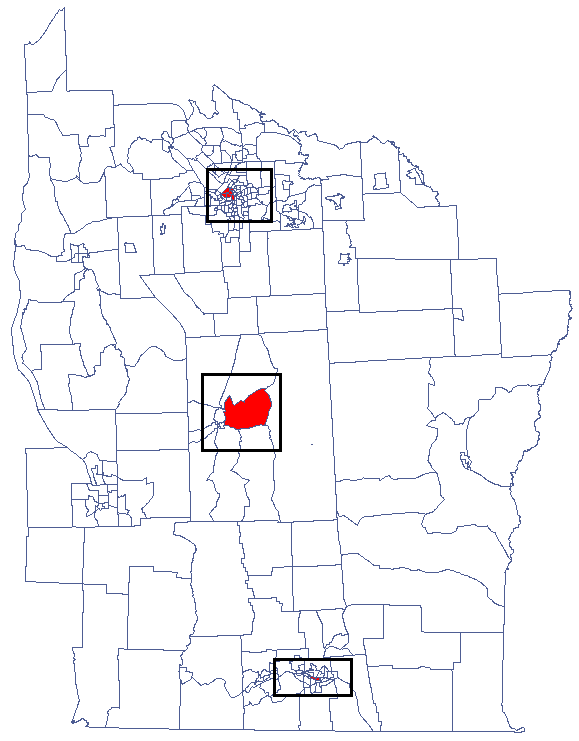
Udało się zlokalizować 3 skupiska (6 regionów spisowych w analizie współczynnika i 4 regiony w analizie współczynnika ) gdzie częstość występowania białaczki jest istotnie wyższa. Są to centra klasterów wysokich wartości białaczki oznaczone na mapie kolorem czerwonym.
Uzyskane wyniki możemy dodatkowo zobrazować kolorując mapę wartościami lokalnego współczynnika Getisa i Orda lub też wartościami statystyki testowej bądź wartościami . Wystarczy jedynie wcześniej przekopiować odpowiednie kolumny z raportu do arkusza danych. W tym przykładzie do kolorowania wykorzystamy wartości statystyki testowej  . Po wklejeniu jej do pustej kolumny arkusza danych, w menadżerze map kolorujemy mapę bazową zgodnie z wartościami tej kolumny wybierając odchylenie standardowe o współczynniku 3 jako sposób gradacji kolorów. Dodatnie i wysokie wartości statystyki świadczą o skoncentrowaniu obiektów o wysokich wartościach, wartości ujemne i niskie - obiektów o niskich wartościach, a wartości bliskie zeru wskazują na losowy rozkład badanej zmiennej w przestrzeni.
. Po wklejeniu jej do pustej kolumny arkusza danych, w menadżerze map kolorujemy mapę bazową zgodnie z wartościami tej kolumny wybierając odchylenie standardowe o współczynniku 3 jako sposób gradacji kolorów. Dodatnie i wysokie wartości statystyki świadczą o skoncentrowaniu obiektów o wysokich wartościach, wartości ujemne i niskie - obiektów o niskich wartościach, a wartości bliskie zeru wskazują na losowy rozkład badanej zmiennej w przestrzeni.
Analizując wygładzoną zmienną prev wzmacniamy efekt klasteryzacji. Uzyskujemy podobny rezultat, czyli 3 skupiska (15 regionów spisowych w analizie współczynnika i 9 regionów w analizie współczynnika ) będące centrami klasterów.
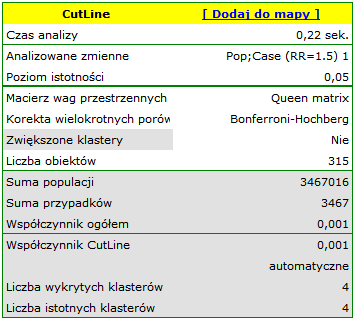
CutL - wersja eksperymentalna
Metoda CutL jest rozwijana w celu wykrywania klasterów o istotnie wyższym współczynniku częstości niż wskazany przez badacza (Więckowska B. 2017 2)). W rezultacie program znajduje klastery, bada ich istotność statystyczną i wyrysowuje je na mapie.
Uwaga! Analiza bazuje na często wykorzystywanym teście dokładnym dla jednej proporcji.
By przeprowadzić analizę powinniśmy dysponować danymi mapy zawierającej obiekty typu wielokąt. Dane do analizy powinny być zorganizowane w postaci dwóch kolumn, gdzie dla każdego obiektu podana jest liczność populacji i odpowiednia liczba przypadków wyszczególnionych.

Okno z ustawieniami opcji testu CutL wywołujemy poprzez menu Analiza przestrzenna→Statystyki przestrzenne→CutL
Analiza bazuje na liczności populacji i liczbie przypadków oraz na macierzy sąsiedztwa przestrzennego.
Wykorzystanie macierzy sąsiedztwa:
Domyślnie wyliczaną w analizie macierzą sąsiedztwa jest macierz przyległości granic typu Queen. Inne macierze mogą być użyte w analizie, ale wymaga to ich wcześniejszego przygotowania i wybrania w oknie analizy CutL.
Punkt odcięcia jest wartością powyżej której wyszukiwane są istotne statystycznie klastery i powinien być ustawiony w oknie analizy. Jeśli badacz nie określi tej wartości, wówczas stanowi ją ogólny współczynnik częstości wyliczony dla całego badanego obszaru.
Opcje
- Korekcja wielokrotnych porównań
Następujące korekty wielokrotnych porównań mogą być wykorzystane:
- Bonferroni-Hochberg
- Sidak-Hochberg
- Benjamini-Hochberg
- porównaj klaster/poza klasterem
Dodatkowo każdy klaster może być porównany z obszarem poza klasterem. Test dla jednej proporcji porównuje wówczas współczynnik częstości uzyskany w klasterze do odpowiedniego współczynnika poza klasterem. Test jest wówczas jednostronny ze względu na poszukiwanie klasterów o wyższych wartościach niż punkt odcięcia.
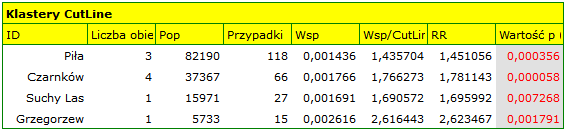
Wyniki
Wynik analizy jest prezentowany w formie raportu z dołączonymi warstwami map.
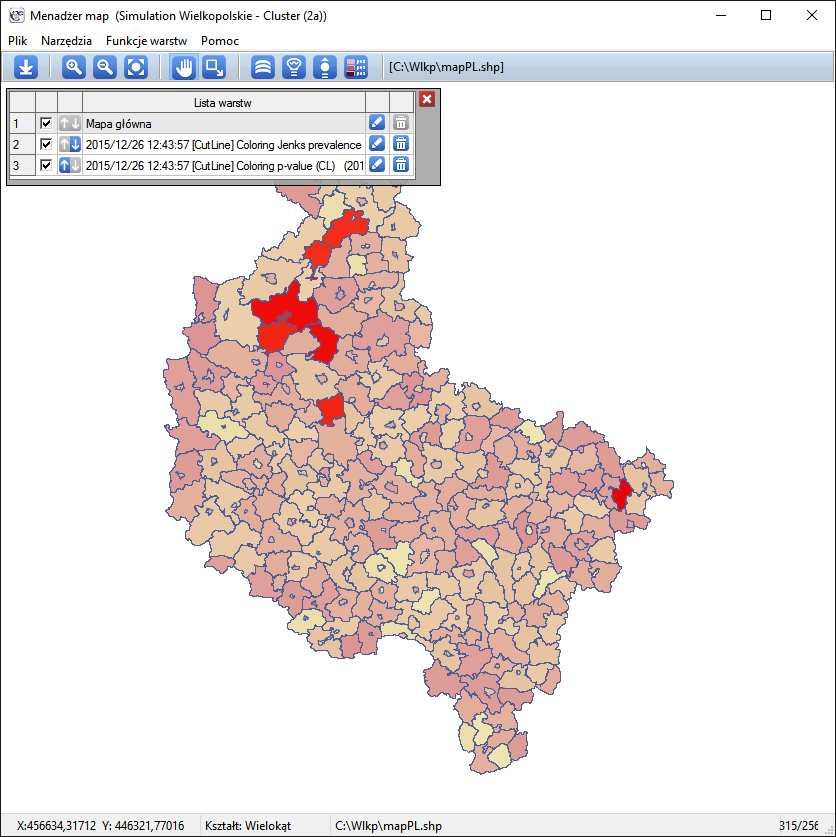
CutL czasowo-przestrzenna
Przy pomocy metody CutL możliwe jest również wyznaczenie skupień czasowo-przestrzennych (Więckowska B. 2019 3)), czyli takich, które nie utrzymują się przez cały badany zakres czasu, ale tylko przez krótszy okres. Poszczególne warstwy czasu dodajemy do arkusza danych poprzez wybór Edytuj oś czasu z drzewa projektu, po wskazaniu odpowiedniej mapy.
Okno analizy czasowo-przestrzennej uzyskujemy poprzez wybór menu Analiza przestrzenna→Statystyki→przestrzenne→CutL czasowo-przestrzenna.
1)
Anselin L. (1995), Local Indicators of Spatial Association – LISA; Geographical Analysis, 27(2): 93–115
2)
Więckowska B., Marcinkowska J. (2017), CutL: an alternative to Kulldorff’s scan statistics for cluster detection with a specified cut-off level. Geospatial Health, 12(2): 556
3)
Więckowska B., Górna I., Trojanowski M., Pruciak A., Stawińska-Witoszyńska B. (2019), Searching for space-time clusters: The CutL method compared to Kulldorff's scan statistic 14(2
przestrzenpl/lokalpl.txt · ostatnio zmienione: 2015/12/28 14:39 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
