Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:porown3grpl:parpl:anovaposthpl
Kontrasty i testy POST-HOC
Analiza wariancji daje informację tylko o tym, czy między populacjami występują istotne statystycznie różnice. Nie mówi ona, które populacje różnią się między sobą. By uzyskać wiedzę o różnicach dla fragmentu naszego złożonego układu stosujemy kontrasty (gdy dokonujemy wcześniej zaplanowanych i zwykle tylko wybranych porównań - tzw. a'priori), lub procedury porównań wielokrotnych czyli testy POST-HOC (gdy po wykonanej analizie wariancji szukamy różnic, zwykle pomiędzy wszystkimi parami).
Liczba wszystkich możliwych porównań prostych wyliczana jest z wzoru:

Hipotezy:
Przykład 1 - porównania proste (porównanie pomiędzy sobą 2 wybranych średnich):

Przykład 2 - porównania złożone (porównanie kombinacji wybranych średnich):
![\begin{array}{cc}
\mathcal{H}_0: & \mu_1=\frac{\mu_2+\mu_3}{2},\\[0.1cm]
\mathcal{H}_1: & \mu_1\neq\frac{\mu_2+\mu_3}{2}.
\end{array}](/lib/exe/fetch.php?media=wiki:latex:/imgf0472a7ad15f9b99bbf5ce50cb721339.png "LaTeX")
By można było zdefiniować wybrane hipotezy należy dla każdej średniej przypisać wartość kontrastu  ,
,  . Wartości są tak wybierane by ich sumy dla porównywanych stron były liczbami przeciwnymi, a ich wartość dla średnich nie biorących udziału w analizie wynosi 0.
. Wartości są tak wybierane by ich sumy dla porównywanych stron były liczbami przeciwnymi, a ich wartość dla średnich nie biorących udziału w analizie wynosi 0.
- Przykład 1:
 ,
,  ,
,  .
. - Przykład 2:
 , ,
, ,  ,
,  ,…,
,…,  .
.
Wyboru właściwej hipotezy możemy dokonać:

 Porównując wyznaczoną na podstawie statystyki testowej odpowiedniego testu POST-HOC wartość
Porównując wyznaczoną na podstawie statystyki testowej odpowiedniego testu POST-HOC wartość  z poziomem istotności:
z poziomem istotności:

Dla porównań prostych i złożonych, zarówno równolicznych jak i różnolicznych grup, gdy wariancje nie różnią się istotnie.
 Wartość najmniejszej istotnej różnicy wyliczana jest z wzoru:
Wartość najmniejszej istotnej różnicy wyliczana jest z wzoru:

gdzie:
 - to wartość krytyczna (statystyka) rozkładu F Snedecora dla zadanego poziomu istotności
- to wartość krytyczna (statystyka) rozkładu F Snedecora dla zadanego poziomu istotności  oraz dla stopni swobody odpowiednio: 1 i
oraz dla stopni swobody odpowiednio: 1 i  .
.
- Statystyka testowa ma postać:

Statystyka ta podlega rozkładowi t-Studenta z stopniami swobody.
Dla porównań prostych zarówno równolicznych jak i różnolicznych grup, gdy wariancje nie różnią się istotnie.
- Wartość najmniejszej istotnej różnicy wyliczana jest z wzoru:

gdzie:
 - to wartość krytyczna (statystyka) rozkładu F Snedecora dla zadanego poziomu istotności oraz
- to wartość krytyczna (statystyka) rozkładu F Snedecora dla zadanego poziomu istotności oraz  i stopni swobody.
i stopni swobody.
- Statystyka testowa ma postać:

Statystyka ta podlega rozkładowi F Snedecora z i stopniami swobody.
Dla porównań prostych zarówno równolicznych jak i różnolicznych grup, gdy wariancje nie różnią się istotnie.
- Wartość najmniejszej istotnej różnicy wyliczana jest z wzoru:

gdzie:
 - to wartość krytyczna (statystyka) rozkładu studentyzowanego rozstępu dla zadanego poziomu istotności oraz i
- to wartość krytyczna (statystyka) rozkładu studentyzowanego rozstępu dla zadanego poziomu istotności oraz i  stopni swobody.
stopni swobody.
- Statystyka testowa ma postać:

Statystyka ta podlega rozkładowi studentyzowanego rozstępu z i stopniami swobody.
Info.
Algorytm obliczania wartości p i statystyki rozkładu studentyzowanego rozstępu w PQStat bazuje na pracy Lunda (1983)1). Inne programy lub strony internetowe mogą wyliczać nieco inne wartości niż PQStat, gdyż mogą bazować na mniej precyzyjnych lub bardziej restrykcyjnych algorytmach (Copenhaver i Holland (1988), Gleason (1999)).
Test badający istnienie trendu może być wyliczany w takiej samej sytuacji jak ANOVA dla zmiennych niezależnych, gdyż bazuje na tych samych założeniach, inaczej jednak ujmuje hipotezę alternatywną - wskazując w niej na istnienie trendu wartości średnich dla kolejnych populacji. Analiza trendu w ułożeniu średnich oparta jest na kontrastach LSD Fishera. Budując odpowiednie kontrasty można badać dowolny rodzaj trendu np. liniowy, kwadratowy, sześcienny, itd. Poniżej znajduje się tabela przykładowych wartości kontrastów dla wybranych trendów.

Trend liniowy
Trend liniowy, tak jak pozostałe trendy, możemy analizować wpisując odpowiednie wartości kontrastów. Jeśli jednak znany jest kierunek trendu liniowego, wystarczy skorzystać z opcji Trend liniowy i wskazać oczekiwaną kolejność populacji przypisując im kolejne liczby naturalne.
Analiza przeprowadzana jest w oparciu o kontrast liniowy, czyli wskazanym według naturalnego uporządkowania grupom przypisane są odpowiednie wartości kontrastu i wyliczona zostaje statystyka LSD Fishera.
Przy znanym oczekiwanym kierunku trendu, hipoteza alternatywna jest jednostronna i interpretacji podlega jednostronna wartość . Interpretacja dwustronnej wartości oznacza, że badacz nie zna (nie zakłada) kierunku ewentualnego trendu. Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Grupy jednorodne
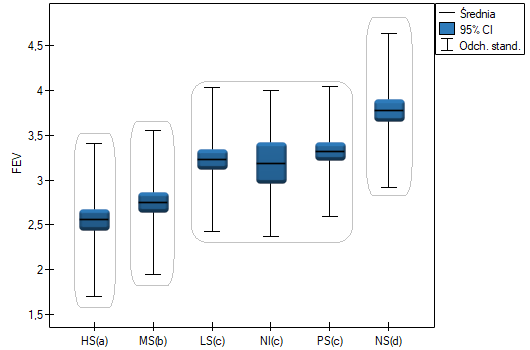
Dla każdego testu post-hoc, budowane są grupy jednorodne. Każda grupa jednorodna przedstawia zbiór grup, które nie różnią się od siebie w sposób istotny statystycznie. Na przykład, załóżmy, że podzieliliśmy badanych na sześć grup odnośnie statusu palenia: Nonsmokers (NS), Passive smokers (PS), Noninhaling smokers (NI), Light smokers (LS), Moderate smokers (MS), Heavy smokers (HS) i badamy dla nich parametry wydechowe. W przeprowadzonej analizie typu ANOVA uzyskaliśmy istotne statystycznie różnice w parametrach wydechowych pomiędzy badanymi grupami. Chcąc wskazać które grupy różnią się istotnie, a które nie, wykonujemy testy typu post-hoc. W rezultacie oprócz tabeli z wynikami poszczególnych par porównań i podanej istotności statystycznej w postaci wartości
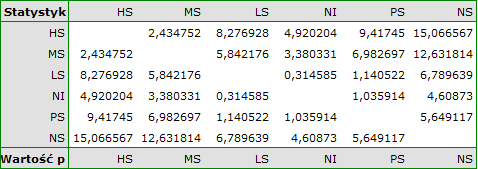
uzyskujemy podział na grupy jednorodne:
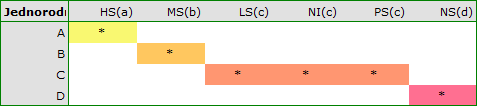
W tym przypadku uzyskano 4 grupy jednorodne tzn. A, B, C i D, co wskazuje na możliwość przeprowadzania badania w oparciu o mniejszy podział tzn. zamiast sześciu grup, które badaliśmy pierwotnie można prowadzić dalsze analizy w oparciu o cztery wyznaczone tu grupy jednorodne. Kolejność grup ustalona została na podstawie średnich ważonych wyliczonych dla poszczególnych grup jednorodnych, w taki sposób, by litera A przypisana została go grupy o najniższej średniej ważonej średniej ważonej, a dalsze litery alfabetu kolejno do grup o coraz wyższych średnich.
Okno z ustawieniami opcji jednoczynnikowej ANOVA dla grup niezależnych wywołujemy poprzez menu Statystyka→Testy parametryczne→ANOVA dla grup niezależnych lub poprzez Kreator.
1)
Lund R.E., Lund J.R. (1983), Algorithm AS 190, Probabilities and Upper Quantiles for the Studentized Range. Applied Statistics; 34
statpqpl/porown3grpl/parpl/anovaposthpl.txt · ostatnio zmienione: 2022/01/27 17:30 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
