Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
pl:statpqpl:metapl
Spis treści
Meta-analiza

Liczba pojawiających się prac naukowych w ostatniej dekadzie bardzo wzrosła. Jest to związane z szeregiem korzyści, ale utrudnia nadążenie za wciąż pojawiającymi się nowymi informacjami. Jeśli na przykład lekarz zastosował by nowy sposób leczenia dla swoich pacjentów na podstawie przeczytanej pracy naukowej mógłby popełnić błąd. Błąd może wynikać z faktu opublikowania całego szeregu innych prac, które przeczą skuteczności tego leczenia. Aby decyzja podjęta przez lekarza obarczona była jak najmniejszym błędem, powinien on przeczytać większość prac naukowych, jakie ukazały się w tym temacie. W rezultacie ciągła konieczność przeglądania coraz to większych zbiorów literatury zajęłaby lekarzowi tak dużo czasu, że mogłoby go zabraknąć na leczenie pacjentów. Meta-analiza pozwala na szybkie dokonanie takiego przeglądu ponieważ jest rezultatem przeprowadzonego przez jej autora szerokiego przeglądu literatury i wykonaniu statystycznego podsumowania opisanych tam wyników.
Meta-analiza w programie PQStat wykonywana jest na podstawie następujących miar:
- Różnica średnich,
- d Cohen,
- g Hedges,
- Iloraz średnich,
- Iloraz szans (OR),
- Relatywne ryzyko (RR),
- Różnica ryzyka (RD),
- Współczynnik Pearsona,
- AUC dla krzywej ROC,
- Proporcja.
Wprowadzenie
Najbardziej znanym obrazem związanym z meta-analizą jest wykres leśny przedstawiający wyniki poszczególnych badań wraz z ich podsumowaniem.
(2.6,4)
\rput(-0.8,0.8){\scriptsize Podsumowanie}
\psdiamond[framearc=.3,fillstyle=solid, fillcolor=lightgray](2.6,0.8)(0.4,0.15)
\rput(-0.6,1.575){\scriptsize Badanie 5}
\psline[linewidth=0.2pt](2.3,1.575)(2.9,1.575)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](2.5,1.5)(2.65,1.65)
\rput(-0.6,2.1){\scriptsize Badanie 4}
\psline[linewidth=0.2pt](2.53,2.1)(3.1,2.1)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](2.7,2)(2.9,2.2)
\rput(-0.6,2.54){\scriptsize Badanie 3}
\psline[linewidth=0.2pt](1,2.54)(3.35,2.54)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](2,2.5)(2.08,2.58)
\rput(-0.6,3.04){\scriptsize Badanie 2}
\psline[linewidth=0.2pt](1.25,3.04)(3.25,3.04)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](2.1,3)(2.18,3.08)
\rput(-0.6,3.55){\scriptsize Badanie 1}
\psline[linewidth=0.2pt](0.85,3.55)(2.5,3.55)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](1.5,3.5)(1.6,3.6)
\rput(2.4,-0.3){\scriptsize Wielkość efektu}
\end{pspicture}](/lib/exe/fetch.php?media=wiki:latex:/imgcefa9473f83c5b0ad44d1798ab1d101b.png "LaTeX")
Aby można było dokonać wspólnego podsumowania wybranej literatury musi być ona spójna w opisie, a podane tam miary muszą być tożsame.
By dana praca naukowa mogła być wykorzystana w meta-analizie powinna opisywać: Efekt końcowy czyli pewnego rodzaju miarę statystyczną wskazującą na uzyskany w pracy wynik (efekt). W rzeczywistości mogą to być różnego rodzaju wielkości np. różnica pomiędzy wartościami średnimi, iloraz szans, relatywne ryzyko itp.
Błąd efektu czyli SE (ang. Standard Error) pozwalający określić precyzję przeprowadzonego badania. Owa precyzja nadaje wagę badania. Im mniejszy jest błąd (SE), tym większa jest precyzja danego badania i tym przypisana waga będzie wyższa, przez co dane badanie będzie miało większy wpływ na wyniki meta-analizy.
Liczność jest to liczba obiektów na jakiej przeprowadzone zostało badanie.
Uwaga! Często zdarza się, że praca naukowa nie zawiera wszystkich wymienionych wyżej elementów, wówczas należy szukać w niej danych, na podstawie których wyliczenie tych miar będzie możliwe.
Uwaga! Program PQstat obliczenia związane z meta-analizą wykonuje na danych zawierających: Efekt końcowy, Błąd efektu i w niektórych sytuacjach Liczność. Zaleca się, aby przed przystąpieniem do meta-analizy wprowadzić dane dotyczące każdej publikacji w oknie przygotowania danych. Jest to szczególnie przydatne w przypadku kiedy w danej pracy nie podano wprost tych trzech miar.
Okno przygotowania danych wywołujemy poprzez menu:
Statystyki zaawansowane→Meta-analiza→Przygotowanie danych.
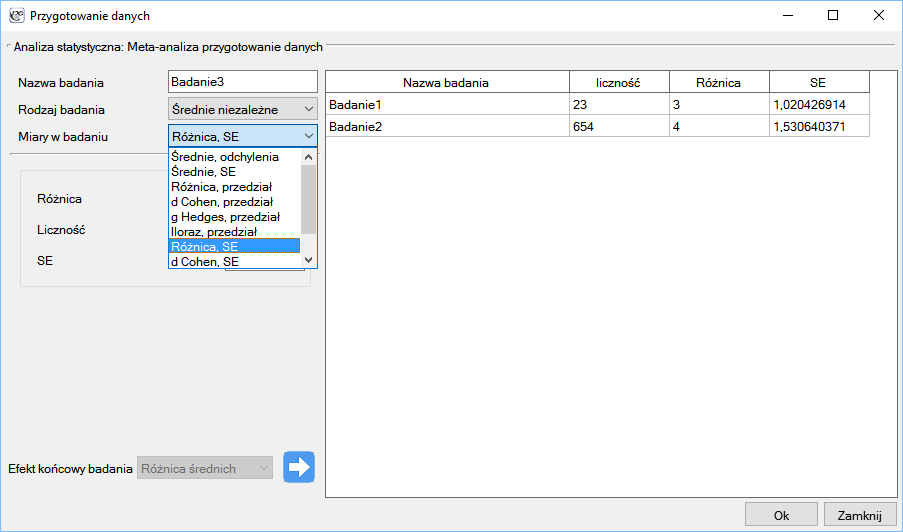
W oknie przygotowania danych do meta-analizy badacz najpierw podaje nazwę wprowadzanego badania. Nazwa ta powinna jednoznacznie identyfikować badanie, ponieważ będzie je opisywać we wszystkich wynikach meta-analizy, w tym również na wykresach. Pożądany Efekt końcowy badania Błąd efektu i Liczność zostają wyliczone w oparciu o miary pozyskane z odpowiedniej pracy naukowej. Miary zawarte w badaniach na podstawie których mogą być wyliczone efekty końcowe, przedstawia poniższa tabela:

gdzie poszczególne efekty końcowe, to:
a - Różnica średnich
b - d Cohen
c - g Hadges
d - Średnia
e - Iloraz średnich
f - Iloraz szans (OR)
g - Relatywne ryzyko (RR)
h - Różnica ryzyka (RD)
i - Współczynnik Pearsona
j - AUC (krzywa ROC)
k - Proporcja
Uwaga! Przy wyznaczaniu błędu współczynników takich jak OR lub RR i innych opartych na tabelach, gdy występują zerowe wartości w tabelach lub przy wyznaczaniu błędu proporcji, gdy proporcja wynosi 0 lub 1, stosowana jest korekta na ciągłość wykorzystująca współczynnik zwiększenia równy 0,5. Przedział ufności dla proporcji wyznaczany jest zgodnie z dokładną metodą Cloppera-Pearsona1).
Jesteśmy zainteresowani wpływem palenia papierosów na ryzyko wystąpienia choroby X. Chcemy przeprowadzić meta-analizę, dla której efektem końcowym będzie relatywne ryzyko (RR). Przy takim założeniu, prace wytypowane do meta-analizy muszą mieć możliwość wyliczenia RR i jego błędu.
Krok 1. Na podstawie opisu efektu końcowego (patrz powyższa tabela) ustalono, że relatywne ryzyko (opisane jako wynik g) jest możliwe do wyznaczenia w programie PQStat w trzech sytuacjach tzn. jeżeli w danej pracy naukowej podano: RR i przedział ufności dla niego lub RR wraz z błędem, lub gdy podane są odpowiednie liczności w czterech kategoriach tzn. tabela 2×2.
Krok 2. Wytypowano do meta-analizy 10 prac, które spełniały kryteria włączenia do badań oraz miały możliwość wyznaczenia relatywnego ryzyka (patrz krok 1). Potrzebne dane zawarte w wytypowanych pracach to:
Badanie 1: liczności: (palący i chorujący)=100, (palący i niechorujący)=73, (niepalący i chorujący)=80, (niepalący i niechorujący)=70,
Badanie 2: liczności: (palący i chorujący)=182, (palący i niechorujący)=172, (niepalący i chorujący)=180, (niepalący i niechorujący)=172,
Badanie 3: liczności: (palący i chorujący)=157, (palący i niechorujący)=132, (niepalący i chorujący)=125, (niepalący i niechorujący)=201,
Badanie 4: liczności: (palący i chorujący)=19, (palący i niechorujący)=15, (niepalący i chorujący)=35, (niepalący i niechorujący)=20,
Badanie 5: liczność: 278, RR[95%CI]=1.03[0.85-1.25],
Badanie 6: liczność: 560, RR[95%CI]=1.21[1.05-1.40],
Badanie 7: liczność: 1207, RR[95%CI]=1.04[0.93-1.15],
Badanie 8: liczność: 214, RR[95%CI]=1.15[0.95-1.40],
Badanie 9: liczność: 285, RR[95%CI]=1.36[1.03-1.79],
Badanie 10: liczność: 1968, RR=1.17, SE(lnRR)=0.0437,
Krok 3. Korzystając z okna przygotowania badań do meta-analizy wprowadzono dane do arkusza. Pierwsze cztery badania wprowadzamy wybierając tabele, badania od piątego do dziewiątego wprowadzamy wybierając RR i przedział, ostatnie badanie podaje wszystkie niezbędne dane tzn. RR i SE. Jeko Efekt końcowy badania ustawiamy Relatywne ryzyko (RR):
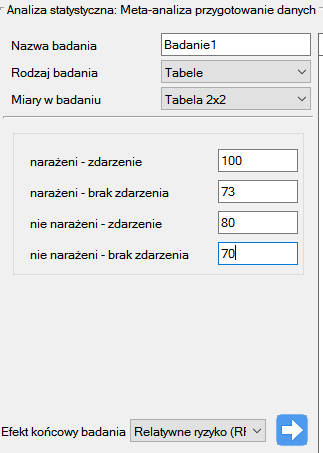
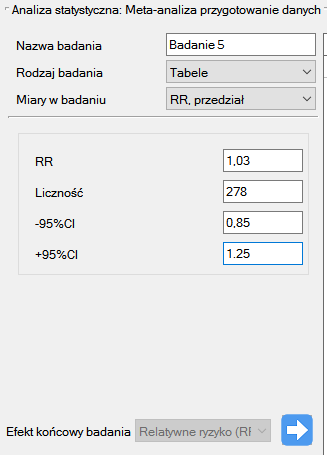
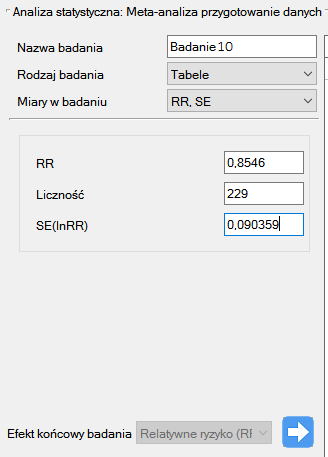
Każde wprowadzone badanie przenosimy do okna po prawej stronie  . Przyciskiem
. Przyciskiem OK przenosimy przygotowane badania do arkusza danych. Na podstawie zawartych w arkuszu informacji o poszczególnych badaniach można przystąpić do wykonywania meta-analizy.}
Wartość p, a więc istotność statystyczna nie jest bezpośrednio wykorzystywana w meta-analizie. Ta sama wielkość efektu może być istotna statystycznie w badaniu dużym, a nieistotna w badaniu opartym na małej liczności. Co więcej, zupełnie mała wielkość efektu może być istotna statystycznie w badaniu dużym, a całkiem duża wielkość efektu może być nieistotna w badaniu małym. Fakt ten związany jest z mocą testów statystycznych. Badając istotność statystyczną sprawdzamy czy efekt w ogóle istnieje, tzn. czy jest różny od zera, a nie czy jest on na tyle duży by miał przełożenie na pożądane skutki. Na przykład fakt, że lek obniża ciśnienie istotnie statystycznie o 1mmHg nie spowoduje że będzie stosowany, gdyż z klinicznego punktu widzenia 1 mmHg jest zbyt małą wielkością. Meta-analiza skupia swoje działanie na wielkości poszczególnych efektów a nie na ich istotności statystycznej. W rezultacie nie ma większego znaczenia, czy prace wykorzystywane w meta-analizie wskazują na istotność statystyczną danego efektu czy też nie.
W programie PQStat, dla każdego badania wyliczana jest istotność statystyczna podana dla stosunku efektu i błędu tego efektu. Jest to podejście asymptotyczne, oparte na rozkładzie normalnym i dedykowane dla licznych grup. Jeśli w cytowanym badaniu do sprawdzenia istotności statystycznej użyto innego testu, uzyskane wyniki mogą się nieco różnić.
Efekt podsumowujący
W wyniku działania meta-analizy najbardziej pożądanym jej elementem jest podsumowanie zebranych badań, czyli podanie wspólnego efektu  . Takie podsumowanie może odbywać się na dwa sposoby, poprzez wyznaczenie efektu stałego lub efektu zmiennego.
. Takie podsumowanie może odbywać się na dwa sposoby, poprzez wyznaczenie efektu stałego lub efektu zmiennego.
Efekt stały
Wyliczając efekt stały zakładamy, że wszystkie badania w meta-analizie dzielą jeden wspólny prawdziwy efekt. Jeśli więc każde badanie dotyczyłoby tej samej populacji np. tego samego kraju, to chcąc podsumować meta-analizę efektem stałym zakładamy, że w każdym z tych badań prawdziwy (populacyjny) efekt będzie taki sam. Co za tym idzie, wszystkie czynniki, które mogłyby zaburzać wielkość tego efektu są takie same. Na przykład, jeśli na uzyskany efekt może wpływać wiek lub płeć badanych, to w każdym badaniu owe czynniki są podobne. Tak więc różnice w uzyskanych efektach dla poszczególnych badań wynikają tylko z błędu próbkowania (błędu wewnętrznego każdego badania) - czyli wielkości  .
.
Efekt stały oszacowuje populacyjny efekt - prawdziwy efekt dla każdego z badań.
Przedział ufności wokół efektu stałego (szerokość rombu w wykresie leśnym) zależy tylko od poszczególnych .
Efekt zmienny
Wyliczając efekt zmienny zakładamy, że każde badanie reprezentuje nieco inną populację, przez co prawdziwy (populacyjny) efekt będzie inny dla każdej populacji. Jeśli więc każde badanie dotyczyłoby innego kraju, to chcąc podsumować meta-analizę efektem zmiennym zakładamy, że niektóre czynniki, które mogłyby zaburzać wielkość tego efektu mogą mieć różne wielkości w poszczególnych krajach. Na przykład, jeśli na uzyskany efekt (np. średni wzrost dzietności) może wpływać poziom wykształcenia badanych czy zamożność danego kraju, a owe kraję różnią się tymi czynnikami, to w rezultacie prawdziwy efekt (średni wzrost dzietności) będzie nieco inny w każdym z tych krajów. Tak więc różnice w uzyskanych efektach dla poszczególnych badań wynikają z błędu próbkowania (błędu wewnątrz każdego badania) - czyli wielkości , oraz z różnic między badanymi populacjami (wariancji między badaniami - heterogeniczności badań) - czyli  . Owa heterogeniczność nie może być zbyt duża, zbyt duże zróżnicowanie pomiędzy badanymi populacjami wskazuje brak podstaw do wspólnego podsumowania.
. Owa heterogeniczność nie może być zbyt duża, zbyt duże zróżnicowanie pomiędzy badanymi populacjami wskazuje brak podstaw do wspólnego podsumowania.
Efekt zmienny oszacowuje średnią ważoną z prawdziwych (populacyjnych) efektów poszczególnych badań.
Przedział ufności wokół efektu zmiennego (szerokość rombu w wykresie leśnym) zależy od poszczególnych oraz od .
Przedział ufności a przedział predykcji
95% przedział ufności (szerokość rombu w wykresie leśnym) - oznacza , że w 95% przypadkach takich meta-analiz podsumowujący efekt zmienny wpadnie do wyznaczonego przez romb przedziału.
95% przedział predykcji - oznacza, że w 95% przypadków prawdziwy (populacyjny) efekt nowego badania wpadnie do wyznaczonego przedziału.
Okno z ustawieniami opcji meta-analizy wywołujemy poprzez menu:
Statystyki zaawansowane→Meta-analiza→Podsumowanie.
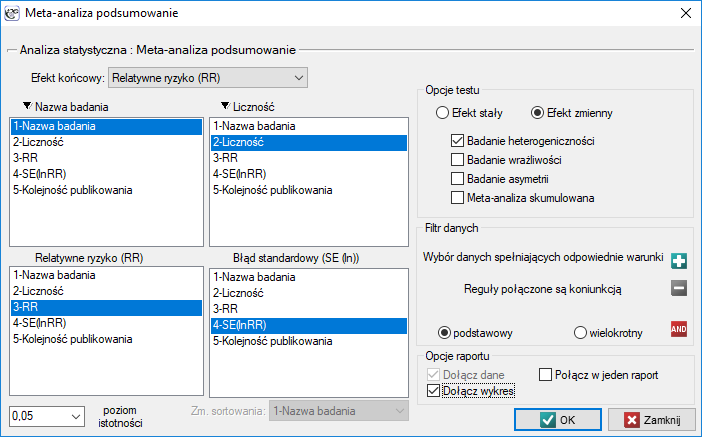
W oknie tym, w zależności od wybranego Efektu końcowego można dokonać podsumowania meta-analizy i przeprowadzić podstawowe analizy pozwalające na sprawdzenie jej założeń takich jak: heterogeniczność, błąd publikacyjny (badanie wrażliwości, asymetrii) oraz przeprowadzić meta-analizę skumulowaną.
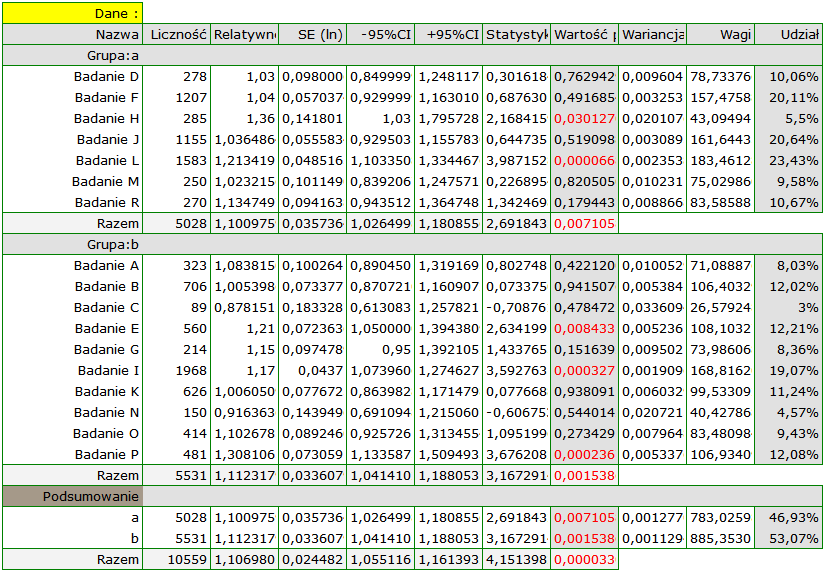
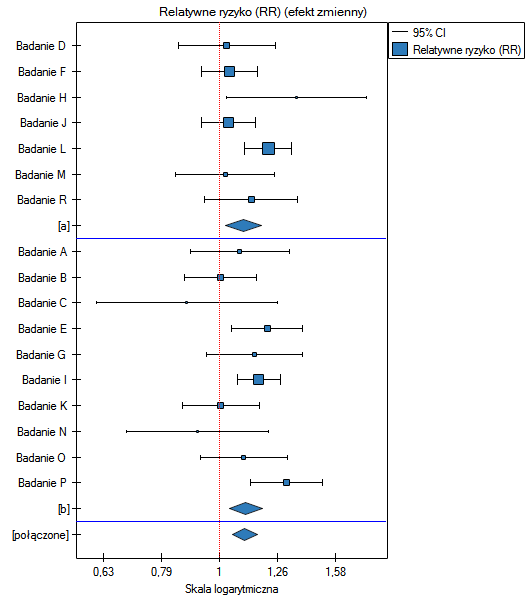
Przykład (plik MetaanalizaRR.pqs)
Badano ryzyko choroby X dla osób palących i dla niepalących. W niektórych pracach naukowych wskazywano, że ryzyko wystąpienia choroby X jest większe dla palących, a w niektórych pracach nie udowodniono takiego związku. By ustalić czy palenie papierosów ma wpływa na występowanie choroby X zaplanowano przeprowadzenie meta-analizy. Wykonano dokładny przegląd literatury dotyczącej tego tematu i na tej podstawie wytypowano 10 prac naukowych do meta-analizy. Prace te dysponowały danymi, na podstawie których możliwe było wyliczenie relatywnego ryzyka (tzn. ryzyka zachorowania dla palących w stosunku do ryzyka zachorowania dla niepalących) i możliwe było ustalenie błędu jakim jest obciążone podane relatywne ryzyko (tzn. precyzji danego badania). Dane przygotowano do meta-analizy i zapisano w pliku.
Ze względu na to, że prace włączone do meta-analizy pochodziły z różnych ośrodków i obejmowały nieco inne populacje, podsumowania dokonano wybierając efekt zmienny. Jako efekt końcowy wybrano relatywne ryzyko oraz przedstawiono wyniki na wykresie leśnym.
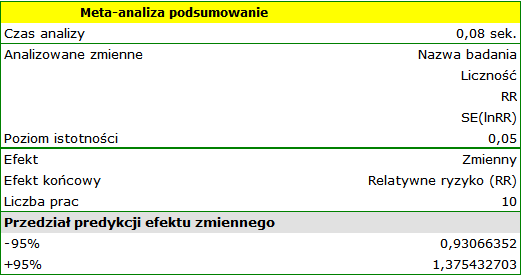
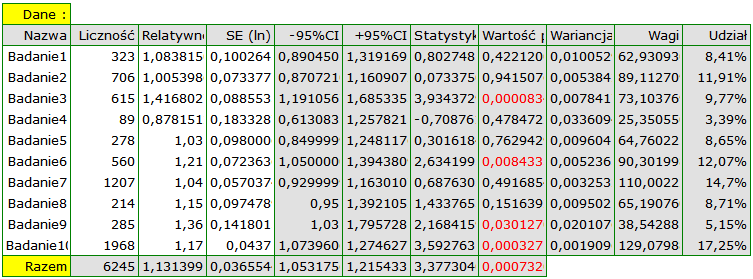
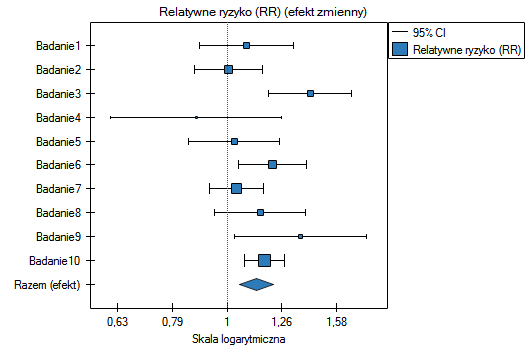
Wyniki czterech badań (badania 3, 6, 9 i 10) wskazują na istotnie wyższe ryzyko zachorowania dla palących. Wynik podsumowujący przeprowadzoną meta-analizę również jest istotny statystycznie i potwierdza ten sam efekt. Uzyskane relatywne ryzyko dla efektu podsumowującego wraz z 95% przedziałem ufności znajduje się powyżej wartości jeden: RR[95%CI]=1.13[1.05-1.22]. Niestety przedział predykcji efektu zmiennego jest szerszy: [0.93-1.38], co oznacza że w 95% przypadków prawdziwe, populacyjne relatywne ryzyko uzyskane w kolejnych badaniach, może być zarówno większe jak i mniejsze niż jeden.
Uwaga! Przed interpretacją wyników należy sprawdzić spełnienie założeń meta-analizy. W tym przypadku należy się zastanowić nad wykluczeniem badania trzeciego (patrz wyniki analizy wrażliwości, analizy asymetrii, meta-analizy skumulowanej oraz założenie heterogeniczności).
Wagi poszczególnych badań
Waga  badania zależy od obserwowanej zmienności.
badania zależy od obserwowanej zmienności.
Dla efektu stałego zmienność wynika tylko z błędu próbkowania (błędu wewnątrz każdego badania) - czyli wielkości :

Dla efektu zmiennego zmienność wynika z błędu próbkowania (błędu wewnątrz każdego badania) - czyli wielkości , oraz z różnic pomiędzy badaniami - czyli obserwowanej wariancji :

Na podstawie wag przypisanych poszczególnym badaniom wyznacza się udział danego badania w całej analizie. Jest to odsetek jaki stanowi waga danego badania w stosunku do łącznej wagi wszystkich włączonych badań.
Badanie heterogeniczności
Trudno oczekiwać by każde badanie kończyło się uzyskaniem dokładnie tej samej wielkości efektu. W naturalny sposób uzyskane w różnych pracach wyniki będą nieco inne. Badanie heterogeniczności ma ustalić na ile pojawiające się różnice pomiędzy uzyskanymi w różnych pracach efektami mają wpływ na budowany w meta-analizie efekt sumaryczny. Efekt sumaryczny dobrze podsumowuje wyniki uzyskane w poszczególnych pracach, jeśli różnice między poszczególnymi efektami są naturalne tzn. nieduże. Duże różnice w obserwowanych efektach mogą świadczyć o niejednorodności badań i konieczności wydzielenia bardziej homogenicznych podgrup np. podzielenia zebranych prac na kilka podgrup względem dodatkowego czynnika. Dla przykładu: dany lek inaczej działa na osoby młodsze a inaczej na starszych, więc w pracach opartych na danych pochodzących głównie od osób młodych uzyskiwany efekt może znacznie odbiegać od prac przeprowadzanych na osobach starszych. Podzielenie zebranych prac na bardziej jednorodne podgrupy pozwoli na dobre oszacowanie efektu sumarycznego dla każdej z tych podgrup oddzielnie.
Badanie heterogeniczności ma na celu sprawdzenie czy zmienność pomiędzy badaniami jest zerowa.
Hipotezy:

gdzie:
 - to wariancja prawdziwych (populacyjnych) efektów poszczególnych badań.
- to wariancja prawdziwych (populacyjnych) efektów poszczególnych badań.
Statystyka testowa ma postać:

gdzie:
- to wariancja obserwowanych efektów,
 - współczynnik wyliczony na podstawie wag przypisanych do poszczególnych badań,
- współczynnik wyliczony na podstawie wag przypisanych do poszczególnych badań,
 - liczba badań.
- liczba badań.
Statystyka ta ma asymptotycznie (dla dużych liczności) rozkład chi-kwadrat z liczbą stopni swobody wyliczaną według wzoru:  .
.
Wyznaczoną na podstawie statystyki testowej wartość  porównujemy z poziomem istotności poziomem istotności
porównujemy z poziomem istotności poziomem istotności  :
:

Uwaga!
- Jeśli uzyskamy wynik jest istotny statystycznie - jest to mocna sugestia, by zrezygnować z wspólnego podsumowywania wszystkich zebranych badań.
- Jeśli uzyskany wynik jest nieistotny statystycznie - możemy podsumować badania wspólnym efektem. Przy czym sugeruje się, by podsumowania dokonywać zwykle efektem zmiennym - zgodnie z poniższym uzasadnieniem.
Uzasadnienie wyboru efektu zmiennego:
Podsumowanie badania efektem zmiennym bierze pod uwagę zmienność pomiędzy badaniami (), natomiast podsumowanie efektem stałym nie bierze pod uwagę tej zmienności. Jeśli jednak jest małe, to wynik działania modelu z efektem stałym będzie bliski wynikom działania modelu z efektem zmiennym, a gdy  , oba modele dadzą dokładnie ten sam wynik.
, oba modele dadzą dokładnie ten sam wynik.
Dodatkowymi miarami opisującymi heterogeniczność są współczynniki  i
i  :
:

Współczynnik określa procent obserwowanej wariancji, jaki wynika z rzeczywistej różnicy w wielkości badanych efektów (graficznie, odzwierciedla stopień zazębiania się przedziałów ufności poszczególnych badań). Ze względu na to, że mieści się on pomiędzy 0% a 100%, podlega prostej interpretacji i jest chętnie stosowany. Jeśli  , wówczas cała obserwowana wariancja wielkości efektów jest „fałszywa”, więc jeśli w wyznaczonym wokół współczynnika przedziale ufności znajdzie się wartość 0, uzyskaną wariancję można uznać za nieistotną statystycznie. Natomiast czym wartość jest bliższa 100%, tym bardziej należy się zastanowić nad rezygnacją z wspólnego podsumowania badań. Przyjmuje się, że
, wówczas cała obserwowana wariancja wielkości efektów jest „fałszywa”, więc jeśli w wyznaczonym wokół współczynnika przedziale ufności znajdzie się wartość 0, uzyskaną wariancję można uznać za nieistotną statystycznie. Natomiast czym wartość jest bliższa 100%, tym bardziej należy się zastanowić nad rezygnacją z wspólnego podsumowania badań. Przyjmuje się, że  oznacza słabą,
oznacza słabą,  średnią, a
średnią, a  silną heterogeniczność badań. Współczynnik rozpatruje się natomiast w odniesieniu do wartości 1. Jeśli przedział ufności dla zawiera wartość 1, wówczas uzyskaną wariancję można uznać za nieistotną statystycznie, a im wyższa wartość , tym większa heterogeniczność badań.
silną heterogeniczność badań. Współczynnik rozpatruje się natomiast w odniesieniu do wartości 1. Jeśli przedział ufności dla zawiera wartość 1, wówczas uzyskaną wariancję można uznać za nieistotną statystycznie, a im wyższa wartość , tym większa heterogeniczność badań.
Przykład c.d. (plik MetaanalizaRR.pqs)
Badając wpływ palenia papierosów na wystąpienie choroby X sprawdzono założenie dotyczące heterogeniczności badań. W tym celu, w oknie analizy wybrano opcję Badanie heterogeniczności.

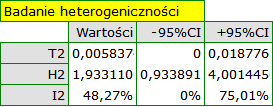
Uzyskano istotny statystycznie wynik statystyki Q (p=0.04284). Wariancja obserwowanych efektów nie jest zerowa (T2=0.0058), a współczynnik I2=48.27%, wskazuje na przeciętną heterogeniczność badań. Jedynie przedział ufności dla współczynnika H2 uznaje za nieistotną zmienność pomiędzy badaniami (przedział dla tego współczynnika to [0.93-4.00]). Mając na uwadze powyższe wyniki, należy się zastanowić, czy zebrane prace mogą być podsumowane jednym wspólnym efektem końcowym (wspólnym relatywnym ryzykiem), czy też warto wyznaczyć bardziej homogeniczną grupę prac i przeprowadzić analizę ponownie.
Badanie wrażliwości
Efekt podsumowujący badania może się zmieniać w zależności od tego, które badania włączymy do analizy, a które z niej wyłączymy. Powinnością badacza jest sprawdzenie, jak wrażliwa jest analiza na zmianę kryteriów doboru badań. Sprawdzenie wrażliwości pozwala ustalić zmiany efektu podsumowującego będącego skutkiem usunięcia danego badania. Badania powinny być na tyle zbliżone, by usunięcie jednego z nich nie zmieniało całkowicie interpretacji efektu podsumowującego.
Przypisana do danego badania wartość udziału pozostałych definiuje odsetek jaki stanowi łączna waga pozostałych w analizie badań po wykluczeniu danego badania. Zmiana precyzji informuje natomiast jak zmieni się precyzja efektu podsumowującego (szerokość przedziału ufności), gdy dane badanie zostanie wykluczone z analizy.
Dobrym zilustrowaniem analizy wrażliwości jest wykres leśny wielkości efektu i wykres zmian precyzji, przy wyłączeniu poszczególnych badań.
Przykład c.d. (plik MetaanalizaRR.pqs)
Badając wpływ palenia papierosów na wystąpienie choroby X sprawdzono wrażliwość analizy na wyłączanie poszczególnych badań. W tym celu w oknie analizy wybrano opcję Badanie wrażliwości oraz wskazano wykres leśny (wrażliwości) i wykres słupkowy (wrażliwości).
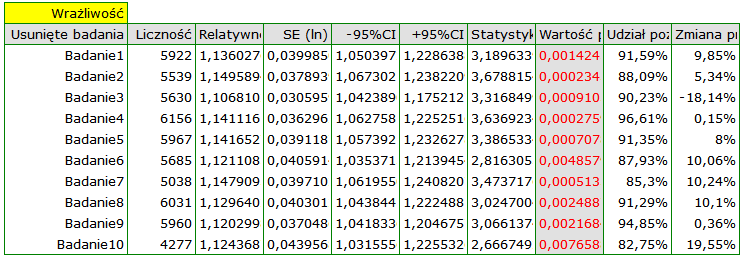
Wyniki wspólnego relatywnego ryzyka, jednakże nie uwzględniającego poszczególnych badań, wciąż pozostają istotne statystycznie. Zastrzeżenie budzi jedynie badanie 3, po jego wyłączeniu precyzja uzyskanego podsumowania wzrasta, przedział ufności dla efektu końcowego jest wówczas węższy o około 18%.
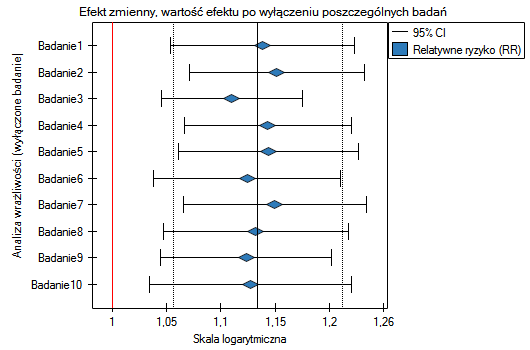
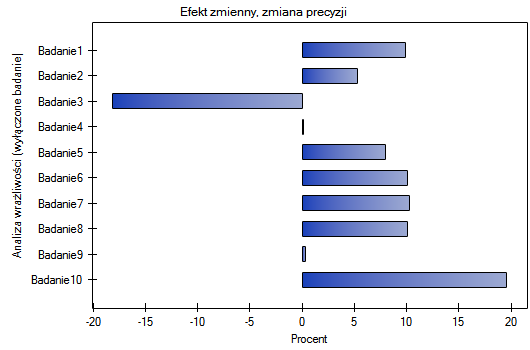
Do tych samych wniosków prowadzi analiza wykresów. Najwęższy przedział i najkorzystniejszą zmianę precyzji uzyskamy po wykluczeniu badania 3.
Badanie asymetrii
Symetria w uzyskanych efektach zwykle świadczy o braku obciążenia publikacyjnego, należy jednak pamiętać, że wiele obiektywnych czynników może zakłócić symetrię np. często nie są publikowane badania o nieistotnych statystycznie efektach lub badania małe, co znacznie utrudnia dotarcie do takich wyników. Jednocześnie brak jest dostatecznie wszechstronnych i uniwersalnych narzędzi statystycznych do detekcji asymetrii. W konsekwencji znaczna część przeprowadzanych meta-analiz publikowana jest mimo występującej zdiagnozowanej asymetrii. Badania takie wymagają jednakże dobrego uzasadnienia takiego postępowania.
Wykres lejkowy
(-0.9,-0.9)
\rput(3.5,1){\scriptsize bias}
\rput(5.5,1.9){\scriptsize obciążenie publikacyjne}
\rput(5.9,1.3){\scriptsize asymetryczny wykres}
\rput(6.5,1.6){\tiny brak badań w prawym dolnym roku wykresu}
\end{pspicture}](/lib/exe/fetch.php?media=wiki:latex:/imgc498871d76b1ee80598ed43761c46c32.png "LaTeX")
Standardowym sposobem sprawdzenia obciążenia publikacyjnego w postaci asymetrii jest wykres lejkowy, pokazujący zależność pomiędzy wielkością badania (oś Y) a wielkością efektu podsumowującego (oś X). Zakłada się, że duże badania (umieszczone w górnej części wykresu) w prawidłowo dobranym zestawie, zlokalizowane są blisko siebie i wyznaczają środek leja, a badania mniejsze znajdują się niżej oraz są bardziej zróżnicowane i symetrycznie rozłożone. Zamiast wielkości badania na osi Y można przedstawić błąd efektu w danym badaniu, co jest lepszym rozwiązaniem niż przedstawienie samej wielkości badania. Błąd efektu jest bowiem miarą wskazującą na jakość badania i niosącą w sobie również informację o jego liczności.
Test Egger'a
Ponieważ interpretacja wykresu lejkowego jest zawsze subiektywna, pomocą może być wykorzystanie współczynnika Egger'a (Egger 19972)) - wyrazu wolnego w dopasowanej prostej regresji. Współczynnik ten bazuje na korelacji pomiędzy odwrotnością błędu standardowego i stosunkiem wielkości efektu do jego błędu. Czym bardziej oddalona od 0 wartość współczynnika, tym większa asymetria. Kierunek współczynnika określa rodzaj asymetrii: wartość dodatnia wraz z dodatnim przedziałem ufności dla niej wskazuje na zbyt wysoką wielkość efektu w małych badaniach a ujemna wraz z ujemnym przedziałem ufności na zbyt niską wielkość efektu w małych badaniach.
Uwaga! Test Egger'a powinien być używany tylko przy dużym zróżnicowaniu wielkości badań i występowaniu badania o średniej wielkości.
Uwaga!
Przy niewielu badaniach (małej liczbie ) trudno jest osiągnąć istotny wynik mimo widocznej asymetrii.
Hipotezy:

gdzie:
 - to wyraz wolny w równaniu regresji Egger'a.
- to wyraz wolny w równaniu regresji Egger'a.
Statystyka testowa ma postać:

gdzie:
 - błąd standardowy wyrazu wolnego.
- błąd standardowy wyrazu wolnego.
Statystyka testowa ma rozkład t-Studenta z  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Badanie liczby „Fail-safe”
Nfs Rosenthal’a - liczba „Fail-safe” opisana przez Rosenthal’a (19793)) określa liczbę prac nie wskazujących na występowanie efektu (np. różnica średnich równa 0, iloraz szans równy 1 itp.) jaka jest potrzebna by zredukować efekt podsumowujący z istotnego statystycznie do statystycznie nieistotnego.

gdzie:
 - wartość statystyki testowej (o rozkładzie normalnym) danego badania,
- wartość statystyki testowej (o rozkładzie normalnym) danego badania,
 - wartość krytyczna rozkładu normalnego dla zadanego poziomu istotności,
- wartość krytyczna rozkładu normalnego dla zadanego poziomu istotności,
- liczba badań w meta-analizie.
Rosenthal (1984) określił liczbę prac będącą punktem odcięcia jako  . Wyznaczając iloraz
. Wyznaczając iloraz  i punktu odcięcia uzyskujemy współczynnik(fs). Według interpretacji Rosenthal'a, jeśli współczynnik(fs) będzie większy niż 1, to prawdopodobieństwo obciążenia publikacyjnego jest minimalne.
i punktu odcięcia uzyskujemy współczynnik(fs). Według interpretacji Rosenthal'a, jeśli współczynnik(fs) będzie większy niż 1, to prawdopodobieństwo obciążenia publikacyjnego jest minimalne.
Nfs Orwin’a - liczba „Fail-safe” opisana przez Orwin’a (19834)) określa liczbę prac o średnim efekcie wskazanym przez badacza  , jaka jest potrzebna by zredukować efekt podsumowujący do pożądanej wielkości
, jaka jest potrzebna by zredukować efekt podsumowujący do pożądanej wielkości  wskazanej przez badacza.
wskazanej przez badacza.

gdzie:
- efekt podsumowujący uzyskany w meta-analizie.
Przykład c.d. (plik MetaanalizaRR.pqs)
Badając wpływ palenia papierosów na wystąpienie choroby X sprawdzono założenie dotyczące asymetrii badań, a więc obciążenia publikacyjnego. W tym celu w oknie analizy wybrano opcję Badanie asymetrii oraz wskazano wykres lejkowy.

Wynik testu Eggera nie są istotne statystycznie (p=0.9137), co wskazuje na brak obciążenia publikacyjnego.
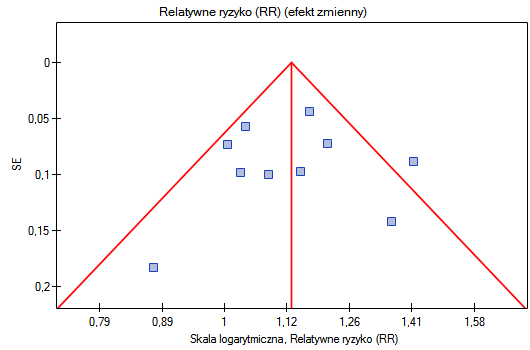
Punkty, przedstawiające poszczególne badania są rozłożone symetrycznie na wykresie lejkowym. Co prawda jedno badanie znajduje się poza obrębem trójkąta (Badanie 3), ale jest blisko jego brzegów. Na podstawie wykresu również nie mamy zasadniczych zastrzeżeń co do doboru badań, jedyna wątpliwość dotyczy badania trzeciego.
Liczba publikacji „Fail-safe” wyznaczona metodą Rosenthal'a jest duża i wynosi 72. Zatem, jeśli efekt podsumowujący (wspólne dla wszystkich badań relatywne ryzyko) miałby być nieistotny statystycznie (palenie papierosów miałoby nie wpływać na ryzyko choroby X), należałoby dołączyć do zebranych prac jeszcze 72 prace w których relatywne ryzyko wynosi jeden. Uzyskany efekt można więc uznać za stabilny, gdyż nie będzie można łatwo (niewielką liczbą prac) podważyć uzyskanego efektu.
Uzyskane, wspólne relatywne ryzyko wynosi RR=1.13. Wykorzystując metodę Orwin'a sprawdzono jak wiele prac o relatywnym ryzyku równym 1.11 potrzeba włączyć, by wspólne relatywne ryzyko spadło do wielkości 1.12. Uzyskany rezultat to 11 prac. Natomiast zmniejszając wielkość relatywnego ryzyka z 1.11 do 1.10 już tylko 5 prac potrzeba by wspólne relatywne ryzyko wyniosło 1.12.
Meta-analiza skumulowana
Typowym celem przeprowadzenia meta-analizy skumulowanej jest pokazanie jak zmienił się efekt od czasu przeprowadzenia/opublikowania ostatniej meta-analizy dotyczącej danego tematu, lub jak zmieniał się na przestrzeni ostatnich lat. Wówczas chronologicznie (zgodnie z linią czasu) dodawane są kolejne badania i każdorazowo wyliczany efekt podsumowujący. Równie ważna jest skumulowana analiza w badaniu zmiany efektu podsumowującego w zależności od wielkości wpływu wybranego, dodatkowego czynnika. Wówczas badania są sortowane zgodnie z wielkością tego czynnika i dla kolejno dodawanych badań wyliczany jest wspólny efekt podsumowujący.
W zależności od celu, któremu ma służyć kumulacja należy wybrać zmienną wg której poszczególne badania będą sortowane, czyli ustalić kolejność dodawania badań do podsumowania meta-analizą. Może to być dowolna zmienna liczbowa.
Przypisana do danego badania wartość udziału skumulowanego definiuje odsetek jaki stanowi łączna waga włączonych do analizy badań tzn. danego badania i badań go poprzedzających. Zmiana precyzji informuje natomiast jak zmieni się precyzja efektu podsumowującego (szerokość przedziału ufności), gdy dane badanie zostanie dołączone do badań go poprzedzających.
Dobrym zilustrowaniem analizy skumulowanej jest wykres leśny wielkości efektu i wykres zmian precyzji, przy dołączaniu poszczególnych badań.
Przykład c.d. (plik MetaanalizaRR.pqs)
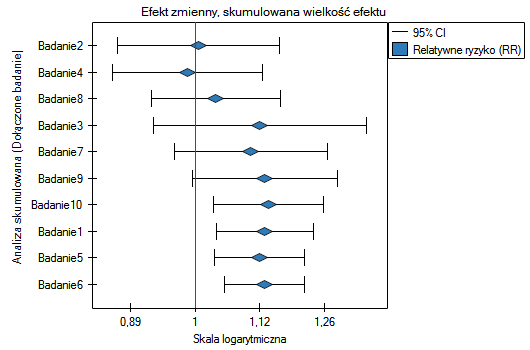
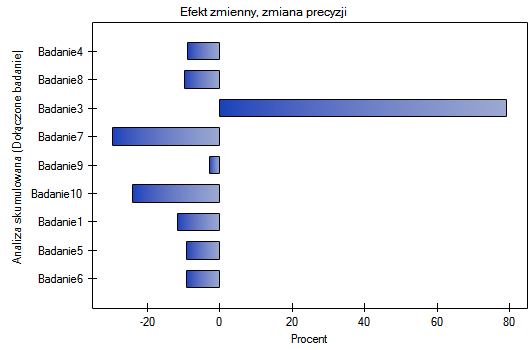
Badając wpływ palenia papierosów na wystąpienie choroby X sprawdzono jak uzyskane wyniki ewaluowały w czasie. W tym celu, w oknie analizy wybrano opcję Meta-analiza skumulowana i zmienną według której kolejne prace będą włączane do meta-analizy, oraz wskazano wykres leśny (skumulowany) i wykres słupkowy (skumulowany).
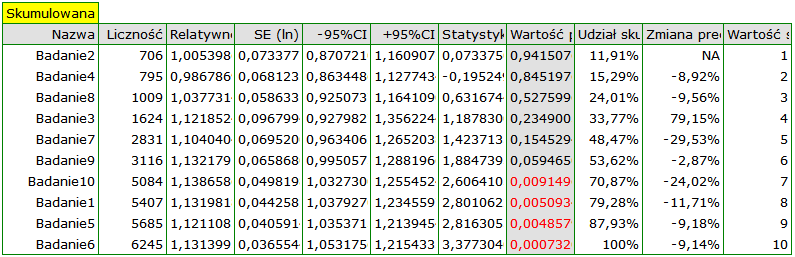
Wraz z pojawianiem się nowych prac uzyskiwany efekt podsumowujący zyskiwał na sile, a jego istotność uzyskano dodając do wcześniejszych prac Badanie 10, a następnie również kolejne badania. Zasadniczo dodanie kolejnych prac zwiększało precyzję uzyskanego relatywnego ryzyka, za wyjątkiem sytuacji, w której dodano Badanie 3. Przedział ufności podsumowującego relatywnego ryzyka poszerzył się wówczas o 79.15%. Efekt ten widzimy w tabeli oraz na dołączonych wykresach. W rezultacie należy się zastanowić nad wykluczeniem Badania 3 z przeprowadzonej meta-analizy.
Porównanie grup
Bywają sytuacje, w których zebrane dane dotyczą tego samego efektu, są wykonywane na tej samej populacji, ale w nieco innych warunkach. Załóżmy że część badań była przeprowadzona w warunkach A, a część w warunkach B. Wówczas interesujące może być porównanie uzyskanych dla każdej grupy efektów podsumowujących. Wykazanie różnic pomiędzy efektami podsumowującymi może być głównym celem meta-analizy i wówczas niewskazane jest podsumowanie jednym wspólnym efektem obu podgrup jednocześnie. Jeśli jednak badacz zdaje sobie sprawę że badania przeprowadzane były w różnych warunkach, ale celowe wydaje się wspólne podsumowanie wszystkich badań, wówczas wykazując brak istotnych statystycznie (lub klinicznie) różnic, może dokonać wspólnego podsumowania uwzględniając jednocześnie ów podział na podgrupy A i B, czyli wyznaczyć wspólne podsumowanie w korekcji o różne warunki eksperymentu. Np. W kraju A panuje nieco inny klimat niż w kraju B. Dysponujemy szeregiem badań dotyczących kraju A i szeregiem badań dotyczących kraju B. Jeśli naszą populacją badaną jest roślinność tych dwóch krajów, to możemy sprawdzić, czy warunki klimatyczne mają wpływ na uzyskane efekty badań dla poszczególnych krajów. Analiza porównawcza wyznaczonych w ten sposób podgrup pozwoli ocenić czy klimat ma zasadniczy wpływ na uzyskiwane wyniki, czy też nie i czy można rzeczywiście wyniki badań obejmujące te dwa kraje podsumować jednym wspólnym efektem, czy też powinniśmy wyznaczać oddzielne podsumowania dla każdego kraju. Innym przykładem może być sytuacja, gdy część badań to badania, w których przeprowadzona była randomizacja ale w części nie mamy pełnej randomizacji, wówczas możemy podzielić badania na podgrupy, by następnie sprawdzić czy badania bez randomizacji dają na tyle zbliżone efekty do badań z randomizacją by móc je włączyć do dalszej, wspólnej analizy.
Heterogeniczność grup
Badanie heterogeniczności grup
Porównania grup możemy dokonać wybierając jako efekt podsumowujący: efekt stały, efekt zmienny - oddzielne lub efekt zmienny - wspólne , gdzie to wariancja obserwowanych efektów.
- Efekt stały wybieramy wtedy, gdy zakładamy, że badania wewnątrz każdej grupy dzielą jeden wspólny prawdziwy (tzn. populacyjny) efekt.
- Efekt zmienny (oddzielne T2) wybieramy wtedy, gdy zakładamy że badania wewnątrz każdej grupy reprezentują nieco inne populacje, oraz grupy różnią się wariancją pomiędzy badaniami.
- Efekt zmienny (wspólne T2) wybieramy wtedy, gdy zakładamy że badania wewnątrz każdej grupy reprezentują nieco inne populacje, ale wariancja pomiędzy badaniami jest taka sama, bez względu na grupę do której przynależą.
W rezultacie każda grupa zostaje opisana oddzielnie wybranym efektem podsumowującym.
Celem głównym jest porównanie grup, czyli ustalenie, czy porównywane grupy różnią się prawdziwym (tzn. populacyjnym) efektem podsumowującym. W praktyce jest to sprawdzenie czy wariancja efektów podsumowujących grupy jest zerowa, czyli badanie heterogeniczności grup. Opis i interpretacja wyników analizy heterogeniczności znajduje się w rozdziale Badanie heterogeniczności, z tym że w przypadku porównania grup heterogeniczność dotyczy efektów podsumowujących porównywanych grup, nie poszczególnych badań, a wynik uzależniony jest od wybranego efektu podsumowującego.
Hipotezy:
gdzie:
- to wariancja prawdziwych (populacyjnych) efektów podsumowujących porównywanych grup.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Jeśli uzyskamy wynik jest istotny statystycznie (wynik statystyki Q, współczynnika I2 lub współczynnika H2), jest to mocna sugestia, by zrezygnować z wspólnego podsumowywania porównywanych grup.
Badanie heterogeniczności w grupach
Dodatkową opcją analizy jest możliwość przeanalizowania każdej grupy oddzielnie pod kątem heterogeniczności, zgodnie z opisem w rozdziale Badanie heterogeniczności. Uzyskane wyniki (w szczególności wyznaczona wariancja T2) ułatwiają podjęcie decyzji co do sposobu porównania grup tzn. wyboru efektu zmiennego (oddzielne ) lub efektu zmiennego (wspólne ).
Wspólne podsumowanie grup
W sytuacji, w której na podstawie wyników porównania grup, różnice uzyskane pomiędzy efektami podsumowującymi poszczególne grupy są niewielkie i nieistotne, można dokonać wspólnego podsumowania tych grup. Podsumowanie odbywa się w korekcji o podział na wskazane grupy. Jeśli na przykład badania dzieliliśmy na podstawie różnych warunków prowadzonego eksperymentu, wówczas wspólne podsumowanie dokonane zostanie w korekcji o różne warunki eksperymentu. Rezultat wspólnego podsumowania zależy od obserwowanych różnic (od wariacji pomiędzy badaniami i pomiędzy grupami) czyli od wyboru efektu podsumowującego (czy jest to efekt stały, czy zmienny (oddzielne ), czy też zmienny (wspólne )).
Dobrym zilustrowaniem wspólnego podsumowania grup w meta-analizie jest wykres leśny przedstawiający wyniki poszczególnych badań wraz z podsumowaniem każdej grupy i wspólnym podsumowaniem grup.
Porównanie ANOVA
Porównanie ANOVA jest dodatkową opcją porównania grup, jest to nieco inna metoda porównania niż porównanie poprzez badanie heterogeniczności grup (oparta na innym modelu matematycznym). Obie metody dają jednakże zbieżne wyniki, co do porównania grup. W przypadku porównania grup metodą ANOVA obserwowana wariancja zostaje rozbita na wariancję między grupami i wariancję wewnątrz grup. Wariancja wewnątrz grup rozbita zostaje następnie na wariancję każdej grupy oddzielnie. W rezultacie wyznaczone zostają następujące statystyki  :
:
- Statystyka (grupa 1) - bada tę część wariancji łącznej, która odnosi się do grupy pierwszej, czyli wariancję pomiędzy badaniami znajdującymi się wewnątrz grupy pierwszej,
- Statystyka (grupa 2) - bada tę część wariancji łącznej, która odnosi się do grupy drugiej, czyli wariancję pomiędzy badaniami znajdującymi się wewnątrz grupy drugiej,
- …
- Statystyka (grupa g) - bada tę część wariancji łącznej, która odnosi się do grupy ostatniej, czyli wariancję pomiędzy badaniami znajdującymi się wewnątrz grupy ostatniej,
- Statystyka Q(wewnątrz grup) = (grupa 1) + (grupa 2) + … + (grupa g) - bada tę część wariancji łącznej, która odnosi się do wnętrza poszczególnych grup, czyli wariancję badań wewnątrz poszczególnych grup,
- Statystyka (między grupami) - bada tę część wariancji łącznej, która odnosi się do różnic między grupami, czyli wariancję pomiędzy grupami (wynik tożsamy z badaniem heterogeniczności grup) ,
- Statystyka (łączna) - bada wariancję pomiędzy wszystkimi badaniami.
Każda z powyższych statystyk ma rozkład chi-kwadrat z odpowiednią dla niej liczbą stopni swobody.
Okno z ustawieniami opcji porównania grup dla meta-analizy wywołujemy poprzez menu: Statystyki zaawansowane→Meta-analiza→Porównanie grup.
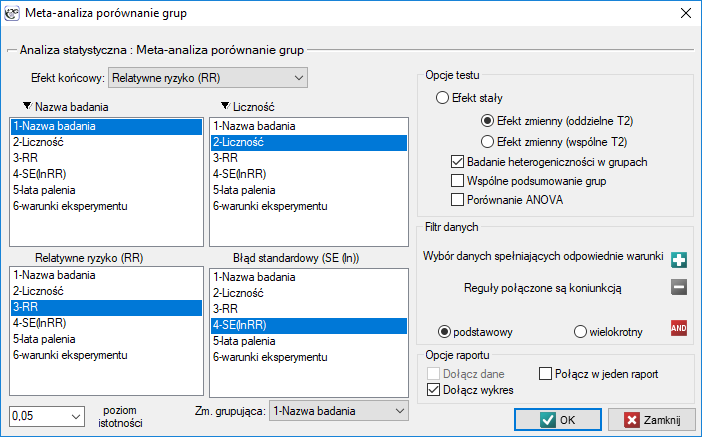
Przykład (plik MetaanalizaRR.pqs)
Badano ryzyko choroby X dla osób palących i dla niepalących. By ustalić czy czas pozostawania w nałogu ma wpływa na występowanie choroby X zaplanowano przeprowadzenie meta-analizy. Wykonano dokładny przegląd literatury dotyczącej tego tematu i na tej podstawie wytypowano 17 prac naukowych dysponujących opisem relatywnego ryzyka i jego błędu (tzn. precyzji danego badania). Ze względu na to, że badania dotyczyły różnego czasu palenia, wyodrębniono 3 grupy badań:
(1) badania dotyczące palących dłużej niż 10 lat,
(2) badania dotyczące palących od 5 do 10 lat,
(3) badania dotyczące palących krócej niż 5 lat.
Dodatkowo dokonano podziału na dwa różne warunki przeprowadzanych badań (różne kryteria włączenia/wyłączenia osób). Dane przygotowano do meta-analizy i zapisano w pliku.
Celem przeprowadzania meta-analizy było porównanie grup wiekowych. Dodatkowo sprawdzono, czy różne warunki eksperymentu przełożyły się na różnice w uzyskanym relatywnym ryzyku.
Ze względu na to, że prace włączone do meta-analizy pochodziły z różnych ośrodków i obejmowały nieco inne populacje, podsumowania dokonano wybierając efekt zmienny (oddzielne T2). Jako efekt końcowy wybrano relatywne ryzyko oraz przedstawiono wyniki na wykresie leśnym.

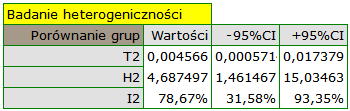
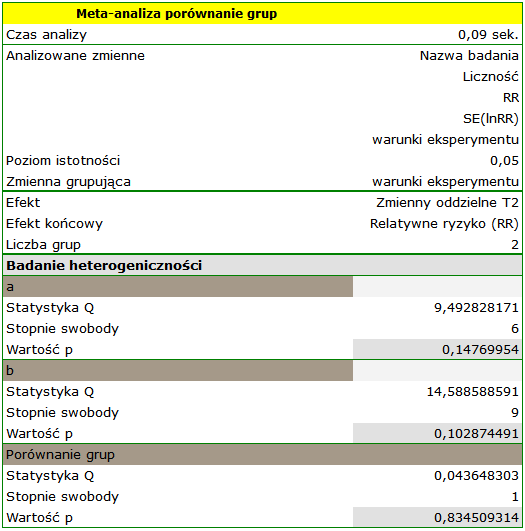
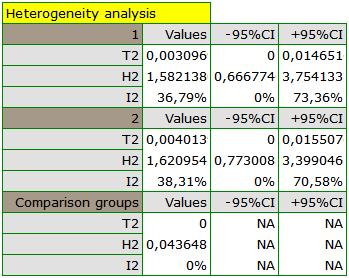
Grupy różnią się istotnie statystycznie (p=0.0092), co obserwujemy nie tylko na bazie testu heterogeniczności, ale również współczynnika H2 (współczynnik wraz z przedziałem ufności znajduje się powyżej wartości jeden) oraz I2 (78%, to wysoka heterogeniczność). Dlatego zebrane prace nie zostaną podsumowane wspólnym efektem a jedynie poprzez oddzielne podsumowanie każdej grupy.
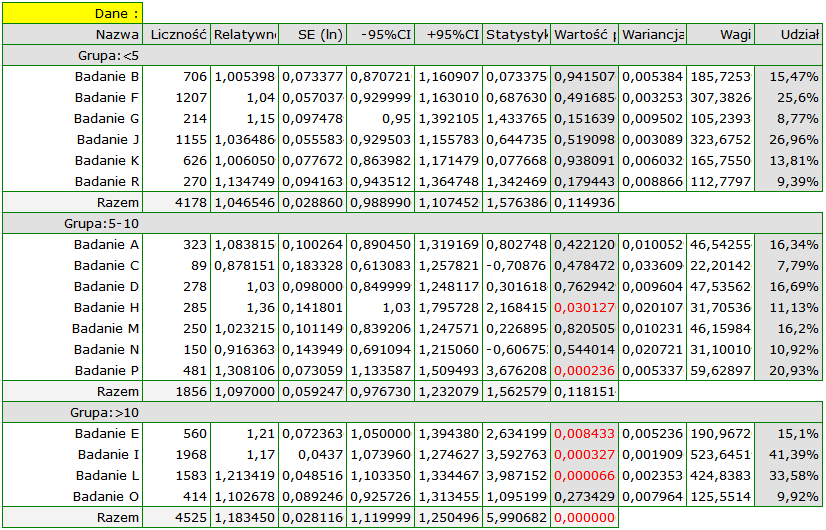
Wykres leśny również przedstawia podsumowanie każdej grupy i nie zawiera wspólnego podsumowania grup.
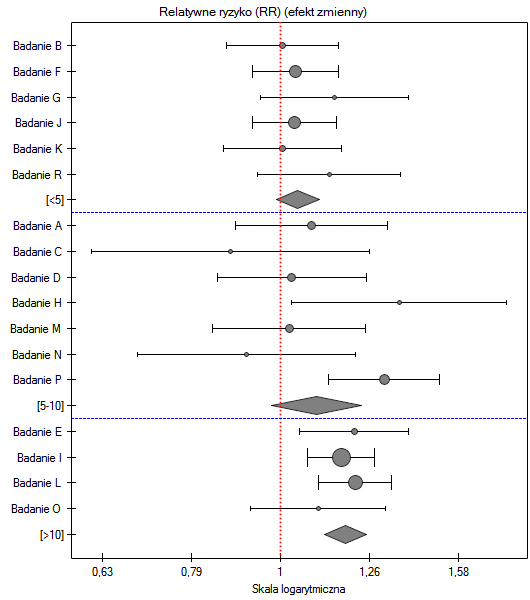
Dodatkowo sprawdzona została homogeniczność w każdej z grup, by upewnić się co do możliwości ich oddzielnego podsumowania.
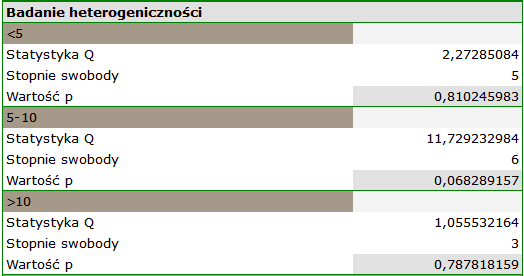
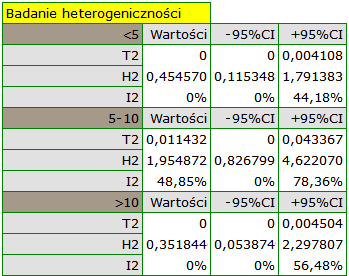
Wyniki porównania dotyczącego różnych warunków prowadzenia badań wskazują natomiast na brak istotnego wpływu tych warunków na efekt podsumowujący. W tym przypadku możliwy jest do wyliczenia wspólny efekt końcowy w korekcji o różne warunki przeprowadzania badań, czyli wspólne podsumowanie obu grup.
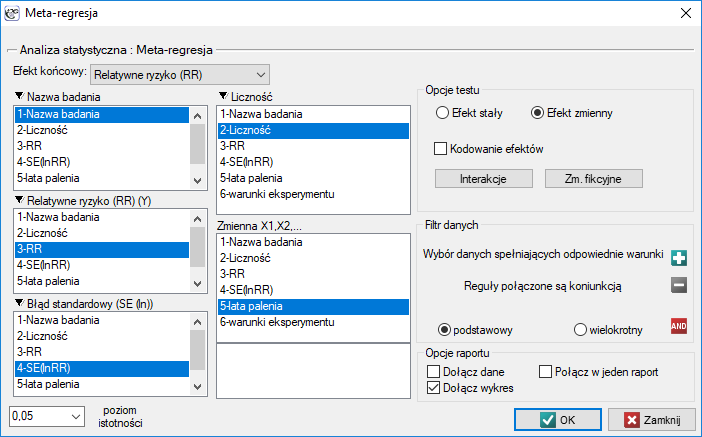
Meta-regresja
Analiza meta-regresji jest przeprowadzana w analogiczny sposób do analizy regresji opisanej w dziale Liniowa regresja wieloraka. W przypadku meta-regresji badanymi obiektami są poszczególne badania, ich wyniki (np. ilorazy szans, relatywne ryzyka, różnice średnich) stanowią zmienną zależną  czyli wyjaśnianą, natomiast dodatkowe warunki przeprowadzania tych badań stanowią zmienne niezależne (
czyli wyjaśnianą, natomiast dodatkowe warunki przeprowadzania tych badań stanowią zmienne niezależne ( ,
,  ,
,  ,
,  ) czyli wyjaśniające. Podobnie jak w tradycyjnych modelach regresji, zmienne niezależne mogą wchodzić w interakcje a te, które są opisane skalą nominalną mogą podlegać specjalnemu kodowaniu (więcej informacji na ten temat można znaleźć w rozdziale Przygotowanie zmiennych do analizy w modelach wielowymiarowych). Liczba zmiennych niezależnych powinna być niewielka, mniejsza niż liczba prac na podstawie których przeprowadza się badanie (
) czyli wyjaśniające. Podobnie jak w tradycyjnych modelach regresji, zmienne niezależne mogą wchodzić w interakcje a te, które są opisane skalą nominalną mogą podlegać specjalnemu kodowaniu (więcej informacji na ten temat można znaleźć w rozdziale Przygotowanie zmiennych do analizy w modelach wielowymiarowych). Liczba zmiennych niezależnych powinna być niewielka, mniejsza niż liczba prac na podstawie których przeprowadza się badanie ( ).
).
Meta-regresję możemy przeprowadzić wybierając efekt stały lub efekt zmienny.
- Efekt stały wybieramy wtedy, gdy zakładamy, że badania przedstawiają jeden wspólny prawdziwy efekt w taki sposób, że wszystkie czynniki, które mogłyby zaburzać wielkość tego efektu są takie same, za wyjątkiem czynników badanych jako zmienne niezależne w modelu (, , , ). Jest to sytuacja występująca bardzo rzadko w prawdziwych badaniach, ponieważ wymaga w pełni kontrolowanych warunków, co w przypadku różnych badań, prowadzonych przez różne ośrodki i różnych badaczy jest prawie niemożliwe. Wykorzystanie efektu stałego miało by uzasadnienie na przykład w sytuacji, gdy wszystkie badania przeprowadza jeden ośrodek, na tej samej populacji, przy zmianie tylko tych warunków które opisuje badana cecha. Na przykład, jeśli chcielibyśmy sprawdzić jak wpływa zmiana temperatury na zmianę opisanej w poszczególnych badaniach wielkości relatywnego ryzyka występowania choroby, wówczas wszystkie badania powinny być przeprowadzone na tej samej populacji w dokładnie tych samych warunkach za wyjątkiem zmiany temperatury, która stanowi zmienną niezależną
 w modelu.
w modelu. - Efekt zmienny wybieramy wtedy, gdy zakładamy, że badania mogą przedstawiać nieco różniące się populacje tzn. czynniki, które mogłyby zaburzać wielkość badanego efektu nie we wszystkich pracach są opisane (można założyć, że są podobne, ale nie muszą być dokładnie takie same). Każda praca podaje wielkości czynników, którymi jesteśmy zainteresowani, które biorą udział w budowaniu modelu jako zmienne niezależne (, , , ). Wykorzystanie efektu zmiennego jest częste, ponieważ poszczególne badania przeprowadzane są najczęściej przez różne ośrodki w nieco innych warunkach, interesująca zmienność dotyczy tylko tych warunków które opisują podane w badaniu czynniki np. temperatura, która stanowić będzie zmienną niezależną w modelu.
Weryfikacja modelu
Istotność statystyczna poszczególnych zmiennych w modelu.
Na podstawie współczynnika oraz jego błędu możemy wnioskować czy zmienna niezależna, dla której ten współczynnik został oszacowany wywiera istotny wpływ na efekt końcowy. W tym celu testujemy hipotezy:

Wyliczmy statystykę testową według wzoru:
 Statystyka testowa ma rozkład normalny.
Statystyka testowa ma rozkład normalny.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności poziomem istotności :
Jakość zbudowanego modelu liniowej regresji wielorakiej możemy ocenić kilkoma miarami.
- Współczynnik R2 - jest miarą dopasowania modelu. Wyraża on procent zmienności pomiędzy efektami badań tłumaczony przez model.
Wartość tego współczynnika mieści się w przedziale  , gdzie 1 oznacza doskonałe dopasowanie modelu, 0 - zupełny bark dopasowania. W jego wyznaczeniu posługujemy się następującą równością:
, gdzie 1 oznacza doskonałe dopasowanie modelu, 0 - zupełny bark dopasowania. W jego wyznaczeniu posługujemy się następującą równością:

gdzie:
 - wariancja między badaniami wyjaśniona przez model,
- wariancja między badaniami wyjaśniona przez model,
 - całkowita wariancja między badaniami.
- całkowita wariancja między badaniami.
- Współczynnik I2 - określa procent obserwowanej wariancji, jaki wynika z rzeczywistej różnicy w wielkości badanych efektów.
Uwaga! Dokładne przedstawienie opisywanej przez współczynniki wariancji można znaleźć w dziale Badanie heterogeniczności
Istotność statystyczna wszystkich zmiennych w modelu
Podstawowym narzędziem szacującym istotność wszystkich zmiennych w modelu jest ANOVA wyznaczająca (modelu).

Wykorzystując podejście ANOVA, obserwowaną wariancję pomiędzy badaniami rozbija się na wariancję tłumaczoną przez model i wariancję reszt (nie tłumaczoną przez model). W rezultacie wyznaczone zostają następujące statystyki :
- Statystyka (reszty) - bada tę część wariancji łącznej, która nie jest tłumaczona przez model,
- Statystyka (modelu) - bada tę część wariancji łącznej, która jest tłumaczona przez model,
- Statystyka (łączna) - bada wariancję pomiędzy wszystkimi badaniami.
Każda z powyższych statystyk ma rozkład chi-kwadrat z odpowiednią dla niej liczbą stopni swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności poziomem istotności :
Okno z ustawieniami opcji porównania grup dla meta-analizy wywołujemy poprzez menu: Statystyki zaawansowane→Meta-analiza→Porównanie grup.
Przykład c.d. (plik MetaanalizaRR.pqs)
Badano ryzyko choroby X dla osób palących i dla niepalących. By ustalić czy czas pozostawania w nałogu ma wpływa na występowanie choroby X oraz czy różne warunki eksperymentu przełożyły się na różnice w uzyskanym relatywnym ryzyku, wykonano meta-analizę porównującą wyodrębnione grupy badań. Na podstawie porównania grup badań udało się ustalić, że ostatnia grupa (grupa palących najdłużej, tzn. dłużej niż 10 lat) wskazuje na związek pomiędzy paleniem a występowaniem choroby X. Natomiast dla grup, w których czas palenia był krótszy, nie udało się uzyskać istotnego efektu. Zauważono jednak, że efekt systematycznie rośnie wraz z upływem lat palenia. By sprawdzić hipotezę o istotnym zwiększeniu ryzyka choroby X wraz z upływem lat palenia papierosów zbudowano dwa modele regresji. W pierwszym modelu zmienną grupującą Lata palenia potraktowano jak zmienną ciągłą. W modelu drugim ustalono, że zmienna Lata palenia traktowana będzie jako zmienna kategorialna (fikcyjna) z grupą odniesienia palącą krócej niż 5 lat. Dane przygotowano do meta-analizy i zapisano w pliku.
Ze względu na to, że prace włączone do meta-analizy pochodziły z różnych ośrodków i obejmowały nieco inne populacje, meta-regresję wykonano wybierając efekt zmienny. Jako efekt końcowy wybrano relatywne ryzyko oraz przedstawiono wyniki na wykresie.

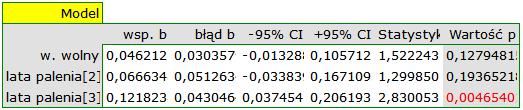
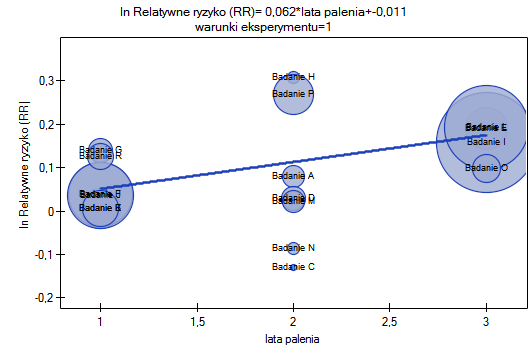
W obu modelach potwierdzono istotny związek pomiędzy czasem palenia a wielkością relatywnego ryzyka wystąpienia choroby X. W modelu pierwszym ustalono, że wraz ze upływem czasu palenia (przejściem do kolejnej grupy lat palenia) logarytm relatywnego ryzyka choroby X zwiększy się o 0.06139. Do podobnych wniosków prowadzi analiza wyników modelu drugiego. W tym przypadku wyniki rozpatrujemy w odniesieniu do grupy palących krócej niż 5 lat. Logarytm relatywnego ryzyka dla palących od 5 do 10 lat wzrasta o 0.06663 (w stosunku do palących krócej niż 5 lat), a dla palących dłużej niż dziesięć lat wzrasta aż o 0.12182 (w stosunku do palących krócej niż 5 lat).
Ponieważ część badań prowadzona była według innych kryteriów (w innych warunkach) uzyskane wyniki obu modeli skorygowano różne warunki prowadzenia badań.

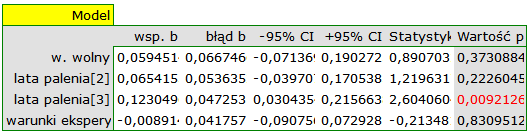
Przeprowadzona korekcja nie zmieniła zasadniczej tendencji, a więc można uznać, że ryzyko wystąpienia choroby X wzrasta wraz z upływem lat palenia bez względu na to jaką metodologię (kryteria włączenia/wyłączenia osób) stosowano by przeprowadzić badania. Uzyskaną zależność dla modelu pierwszego, przy założeniu prowadzenia badań w warunkach „a” (wskazanych jako warunki pierwsze) przedstawia wykres.
1)
Clopper C. and Pearson S. (1934), The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika 26: 404-413
2)
Egger M., Smith G. D., Schneider M., Minder C (1997), Bias in meta-analysis detected by a simple, graphical test. BMJ, 315(7109):629-634
3)
Rosenthal R. (1979), The „file drawer problem” and tolerance for null results. Psychological Bulletin, 5, 638-641
4)
Orwin R. G. (1983), A Fail-SafeN for Effect Size in Meta-Analysis. J Educ Behav Stat, 8(2):157-159
pl/statpqpl/metapl.txt · ostatnio zmienione: 2019/12/17 17:32 (edycja zewnętrzna)
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
