Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:survpl:phcoxpl
Spis treści
Cox proportional hazard regression
The window with settings for Cox regression is accessed via the menu Advanced statistics→Survival analysis→Cox PH regression
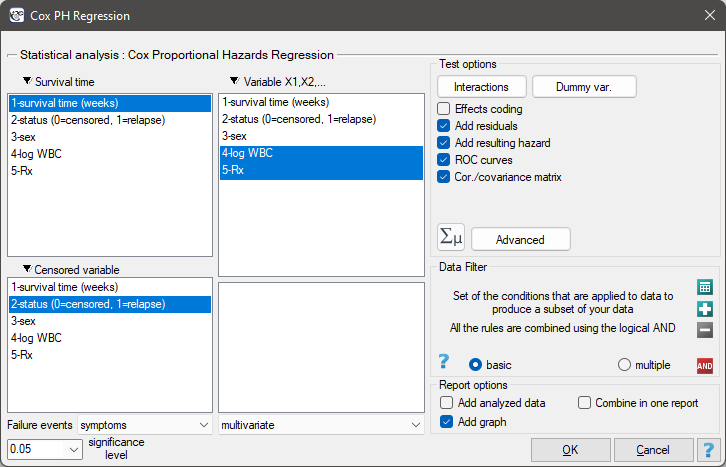
Cox regression, also known as the Cox proportional hazard model (Cox D.R. (1972)1)), is the most popular regressive method for survival analysis. It allows the study of the impact of many independent variables ( ,
,  ,
,  ,
,  ) on survival rates. The approach is, in a way, non-parametric, and thus encumbered with few assumptions, which is why it is so popular. The nature or shape of the hazard function does not have to be known and the only condition is the assumption which also pertains to most parametric survival models, i.e. hazard proportionality.
) on survival rates. The approach is, in a way, non-parametric, and thus encumbered with few assumptions, which is why it is so popular. The nature or shape of the hazard function does not have to be known and the only condition is the assumption which also pertains to most parametric survival models, i.e. hazard proportionality.
The function on which Cox proportional hazard model is based describes the resulting hazard and is the product of two values only one of which depends on time ( ):
):

where:
 - the resulting hazard describing the risk changing in time and dependent on other factors, e.g. the treatment method,
- the resulting hazard describing the risk changing in time and dependent on other factors, e.g. the treatment method, - the baseline hazard, i.e. the hazard with the assumption that all the explanatory variables are equal to zero,
- the baseline hazard, i.e. the hazard with the assumption that all the explanatory variables are equal to zero,
 - a combination (usually linear) of independent variables and model parameters,
- a combination (usually linear) of independent variables and model parameters,
 - explanatory variables independent of time,
- explanatory variables independent of time,
 - parameters.
- parameters.
Dummy variables and interactions in the model
A discussion of the coding of dummy variables and interactions is presented in chapter Preparation of the variables for the analysis in multidimensional models.
Correction for ties in Cox regression is based on Breslow's method2)
The model can be transformed into a the linear form:

In such a case, the solution of the equation is the vector of the estimates of parameters  called regression coefficients:
called regression coefficients:

The coefficients are estimated by the so-called partial maximum likelihood estimation. The method is called „partial” as the search for the maximum of the likelihood function  (the program makes use of the Newton-Raphson iterative algorithm) only takes place for complete data; censored data are taken into account in the algorithm but not directly.
(the program makes use of the Newton-Raphson iterative algorithm) only takes place for complete data; censored data are taken into account in the algorithm but not directly.
There is a certain error of estimation for each coefficient. The magnitude of that error is estimated from the following formula:

where:
 is the main diagonal of the covariance matrix.
is the main diagonal of the covariance matrix.
Note
When building a model it ought to be remembered that the number of observations should be ten times greater than or equal to the ratio of the estimated model parameters ( ) and the smaller one of the proportions of the censored or complete sizes (
) and the smaller one of the proportions of the censored or complete sizes ( ), i.e. (
), i.e. ( ) Peduzzi P., et al(1995)3).
) Peduzzi P., et al(1995)3).
Note
When building the model you need remember that the independent variables should not be multicollinear. In a case of multicollinearity estimation can be uncertain and the obtained error values very high.
Note
The criterion of convergence of the function of the Newton-Raphson iterative algorithm can be controlled with the help of two parameters: the limit of convergence iteration (it gives the maximum number of iterations in which the algorithm should reach convergence) and the convergence criterion (it gives the value below which the received improvement of estimation shall be considered to be insignificant and the algorithm will stop).
EXAMPLE cont. (remissionLeukemia.pqs file)
Hazard Ratio
An individual hazard ratio (HR) is now calculated for each independent variable :
 It expresses the change of the risk of a failure event when the independent variable grows by 1 unit. The result is adjusted to the remaining independent variables in the model – it is assumed that they remain stable while the studied independent variable grows by 1 unit.
It expresses the change of the risk of a failure event when the independent variable grows by 1 unit. The result is adjusted to the remaining independent variables in the model – it is assumed that they remain stable while the studied independent variable grows by 1 unit.
The  value is interpreted as follows:
\item
value is interpreted as follows:
\item  means the stimulating influence of the studied independent variable on the occurrence of the failure event, i.e. it gives information about how much greater the risk of the occurrence of the failure event is when the independent variable grows by 1 unit.
\item
means the stimulating influence of the studied independent variable on the occurrence of the failure event, i.e. it gives information about how much greater the risk of the occurrence of the failure event is when the independent variable grows by 1 unit.
\item  means the destimulating influence of the studied independent variable on the occurrence of the failure event, i.e. it gives information about how much lower the risk is of the occurrence of the failure event when the independent variable grows by 1 unit.
\item
means the destimulating influence of the studied independent variable on the occurrence of the failure event, i.e. it gives information about how much lower the risk is of the occurrence of the failure event when the independent variable grows by 1 unit.
\item  means that the studied independent variable has no influence on the occurrence of the failure event (1).
Note
means that the studied independent variable has no influence on the occurrence of the failure event (1).
Note
If the analysis is made for a model other than linear or if interaction is taken into account, then, just as in the logistic regression model we can calculate the appropriate on the basis of the general formula which is a combination of independent variables.
EXAMPLE cont. (remissionLeukemia.pqs file)
Model verification
- Statistical significance of particular variables in the model (significance of the odds ratio)
On the basis of the coefficient and its error of estimation we can infer if the independent variable for which the coefficient was estimated has a significant effect on the dependent variable. For that purpose we use Wald test.
Hypotheses:

or, equivalently:

The Wald test statistics is calculated according to the formula:

The statistic asymptotically (for large sizes) has the Chi-square distribution with  degree of freedom.
degree of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

- The quality of the constructed model
A good model should fulfill two basic conditions: it should fit well and be possibly simple. The quality of Cox proportional hazard model can be evaluated with a few general measures based on:
 - the maximum value of likelihood function of a full model (with all variables),
- the maximum value of likelihood function of a full model (with all variables),
 - the maximum value of the likelihood function of a model which only contains one free word,
- the maximum value of the likelihood function of a model which only contains one free word,
 - the observed number of failure events.
- the observed number of failure events.
- Information criteria are based on the information entropy carried by the model (model insecurity), i.e. they evaluate the lost information when a given model is used to describe the studied phenomenon. We should, then, choose the model with the minimum value of a given information criterion.
 ,
,  , and
, and  is a kind of a compromise between the good fit and complexity. The second element of the sum in formulas for information criteria (the so-called penalty function) measures the simplicity of the model. That depends on the number of parameters () in the model and the number of complete observations (). In both cases the element grows with the increase of the number of parameters and the growth is the faster the smaller the number of observations.
is a kind of a compromise between the good fit and complexity. The second element of the sum in formulas for information criteria (the so-called penalty function) measures the simplicity of the model. That depends on the number of parameters () in the model and the number of complete observations (). In both cases the element grows with the increase of the number of parameters and the growth is the faster the smaller the number of observations.
The information criterion, however, is not an absolute measure, i.e. if all the compared models do not describe reality well, there is no use looking for a warning in the information criterion.
- Akaike information criterion

It is an asymptomatic criterion, appropriate for large sample sizes.
- Corrected Akaike information criterion

Because the correction of the Akaike information criterion concerns the sample size (the number of failure events) it is the recommended measure (also for smaller sizes).
- Bayesian information criterion or Schwarz criterion

Just like the corrected Akaike criterion it takes into account the sample size (the number of failure events), Volinsky and Raftery (2000)4).
- Pseudo R
 - the so-called McFadden R is a goodness of fit measure of the model (an equivalent of the coefficient of multiple determination
- the so-called McFadden R is a goodness of fit measure of the model (an equivalent of the coefficient of multiple determination  defined for multiple linear regression).
defined for multiple linear regression).
The value of that coefficient falls within the range of  , where values close to 1 mean excellent goodness of fit of the model,
, where values close to 1 mean excellent goodness of fit of the model,  – a complete lack of fit. Coefficient
– a complete lack of fit. Coefficient  is calculated according to the formula:
is calculated according to the formula:

As coefficient does not assume value 1 and is sensitive to the amount of variables in the model, its corrected value is calculated:

- Statistical significance of all variables in the model
The basic tool for the evaluation of the significance of all variables in the model is the Likelihood Ratio test. The test verifies the hypothesis:

The test statistic has the form presented below:

The statistic asymptotically (for large sizes) has the Chi-square distribution with degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
- AUC - area under the ROC curve - The ROC curve – constructed based on information about the occurrence or absence of an event and the combination of independent variables and model parameters – allows us to assess the ability of the built PH Cox regression model to classify cases into two groups: (1–event) and (0–no event). The resulting curve, and in particular the area under it, illustrates the classification quality of the model. When the ROC curve coincides with the diagonal
 , the decision to assign a case to the selected class (1) or (0) made on the basis of the model is as good as randomly allocating the cases under study to these groups. The classification quality of the model is good when the curve is well above the diagonal
, the decision to assign a case to the selected class (1) or (0) made on the basis of the model is as good as randomly allocating the cases under study to these groups. The classification quality of the model is good when the curve is well above the diagonal  , that is, when the area under the ROC curve is much larger than the area under the straight line , thus larger than
, that is, when the area under the ROC curve is much larger than the area under the straight line , thus larger than 
Hypotheses:

The test statistic has the form:

where:
 - field error.
- field error.
The statistic  has asymptotically (for large numbers) a normal distribution.
has asymptotically (for large numbers) a normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
In addition, a proposed cut-off point value for the combination of independent variables and model parameters is given for the ROC curve.
EXAMPLE cont. (remissionLeukemia.pqs file)
Analysis of model residuals
The analysis of the of the model residuals allows the verification of its assumptions. The main goal of the analysis in Cox regression is the localization of outliers and the study of hazard proportionality. Typically, in regression models residuals are calculated as the differences of the observed and predicted values of the dependent variable. However, in the case of censored values such a method of determining the residuals is not appropriate. In the program we can analyze residuals described as: Martingale, deviance, and Schoenfeld. The residuals can be drawn with respect to time or independent variables.
Hazard proportionality assumption
A number of graphical methods for evaluating the goodness of fit of the proportional hazard model have been created (Lee and Wang 2003\cite{lee_wang}). The most widely used are the methods based on the model residuals. As in the case of other graphical methods of evaluating hazard proportionality this one is a subjective method. For the assumption of proportional hazard to be fulfilled, the residuals should not form any pattern with respect to time but should be randomly distributed around value 0.
- Martingale – the residuals can be interpreted as a difference in time
![$[0,t]$](/lib/exe/fetch.php?media=wiki:latex:/img990afe3dc2a01ee124e9c8ef79e63b21.png "LaTeX") between the observed number of failure events and their number predicted by the model. The value of the expected residuals is 0 but they have a diagonal distribution which makes it more difficult to interpret the graph (they are in the range of
between the observed number of failure events and their number predicted by the model. The value of the expected residuals is 0 but they have a diagonal distribution which makes it more difficult to interpret the graph (they are in the range of  to 1).
to 1). - Deviance – similarly to martingale, asymptotically they obtain value 0 but are distributed symmetrically around zero with standard deviation equal to 1 when the model is appropriate. The deviance value is positive when the studied object survives for a shorter period of time than the one expected on the basis of the model, and negative when that period is longer. The analysis of those residuals is used in the study of the proportionality of the hazard but it is mainly a tool for identifying outliers. In the residuals report those of them which are further than 3 standard deviations away from 0 are marked in red.
- Schoenfeld – the residuals are calculated separately for each independent variable and only defined for complete observations. For each independent variable the sum of Shoenfeld residuals and their expected value is 0. An advantage of presenting the residuals with respect to time for each variable is the possibility of identifying a variable which does not fulfill, in the model, the assumption of hazard proportionality. That is the variable for which the graph of the residuals forms a systematic pattern (usually the studied area is the linear dependence of the residuals on time). An even distribution of points with respect to value 0 shows the lack of dependence of the residuals on time, i.e. the fulfillment of the assumption of hazard proportionality by a given variable in the model.
If the assumption of hazard proportionality is not fulfilled for any of the variables in Cox model, one possible solution is to make Cox's analyses separately for each level of that variable.
EXAMPLE cont. (remissionLeukemia.pqs file)
1)
Cox D.R. (1972), Regression models and life tables. Journal of the Royal Statistical Society, B34:187-220
2)
Breslow N.E. (1974), Covariance analysis of censored survival data. Biometrics, 30(1):89–99
3)
Peduzzi P., Concato J., Feinstein A.R., Holford T.R. (1995), Importance of events per independent variable in proportional hazards regression analysis. II. Accuracy and precision of regression estimates. Journal of Clinical Epidemiology, 48:1503-1510
4)
Volinsky C.T., Raftery A.E. (2000) , Bayesian information criterion for censored survival models. Biometrics, 56(1):256–262
en/statpqpl/survpl/phcoxpl.txt · ostatnio zmienione: 2022/02/16 10:11 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
