Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:porown3grpl:parpl:anova_repeatedpl
The ANOVA for dependent groups
The single-factor repeated-measures analysis of variance (ANOVA for dependent groups) is used when the measurements of an analysed variable are made several times ( ) each time in different conditions (but we need to assume that the variances of the differences between all the pairs of measurements are pretty close to each other).
) each time in different conditions (but we need to assume that the variances of the differences between all the pairs of measurements are pretty close to each other).
This test is used to verify the hypothesis determining the equality of means of an analysed variable in several () populations.
Basic assumptions:
- measurement on an interval scale,
- the normal distribution for all variables which are the differences of measurement pairs (or the normal distribution for an analysed variable in each measurement),
Hypotheses:

where:
 ,
, ,…,
,…, – means for an analysed features, in the following measurements from the examined population.
– means for an analysed features, in the following measurements from the examined population.
The test statistic is defined by:

where:
 – mean square between-conditions,
– mean square between-conditions,
 – mean square residual,
– mean square residual,
 – between-conditions sum of squares,
– between-conditions sum of squares,
 – residual sum of squares,
– residual sum of squares,
 – total sum of squares,
– total sum of squares,
 – between-subjects sum of squares,
– between-subjects sum of squares,
 – between-conditions degrees of freedom,
– between-conditions degrees of freedom,
 – residual degrees of freedom,
– residual degrees of freedom,
 – total degrees of freedom,
– total degrees of freedom,
 – between-subjects degrees of freedom,
– between-subjects degrees of freedom,
 ,
,
 – sample size,
– sample size,
 – values of the variable from
– values of the variable from  subjects
subjects  in
in  conditions
conditions  .
.
The test statistic has the F Snedecor distribution with  and
and  degrees of freedom.
degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

Effect size - partial <latex>$\eta^2$</latex>
This quantity indicates the proportion of explained variance to total variance associated with a factor. Thus, in a repeated measures model, it indicates what proportion of the between-conditions variability in outcomes can be attributed to repeated measurements of the variable.

Testy POST-HOC
Introduction to the contrasts and the POST-HOC tests was performed in the \ref{post_hoc} unit, which relates to the one-way analysis of variance.
For simple and complex comparisons (frequency in particular measurements is always the same).
Hypotheses:
Example - simple comparisons (comparison of 2 selected means):

- [i] The value of the critical difference is calculated by using the following formula:

where:
 - is the critical value (statistic) of the F Snedecor distribution for a given significance level and degrees of freedom, adequately: 1 and .
- is the critical value (statistic) of the F Snedecor distribution for a given significance level and degrees of freedom, adequately: 1 and .
- [ii] The test statistic is defined by:

The test statistic has the t-Student distribution with degrees of freedom.
Note!
For contrasts  is used instead of
is used instead of  , and degrees of freedem:
, and degrees of freedem:  .
.
For simple comparisons (frequency in particular measurements is always the same).
- [i] The value of the critical difference is calculated by using the following formula:

where:
 - is the critical value (statistic) of the F Snedecor distribution for a given significance level and and degrees of freedom.
- is the critical value (statistic) of the F Snedecor distribution for a given significance level and and degrees of freedom.
- [
 ] The test statistic is defined by:
] The test statistic is defined by:
 The test statistic has the F Snedecor distribution with and
The test statistic has the F Snedecor distribution with and  degrees of freedom.
degrees of freedom.
For simple comparisons (frequency in particular measurements is always the same).
- [i] The value of the critical difference is calculated by using the following formula:

where:
 - is the critical value (statistic) of the studentized range distribution for a given significance level and and
- is the critical value (statistic) of the studentized range distribution for a given significance level and and  degrees of freedom.
degrees of freedom.
- [ii] The test statistic is defined by:

The test statistic has the studentized range distribution with and degrees of freedom.
Info.
The algorithm for calculating the p-value and statistic of the studentized range distribution in PQStat is based on the Lund works (1983)\cite{lund}. Other applications or web pages may calculate a little bit different values than PQStat, because they may be based on less precised or more restrictive algorithms (Copenhaver and Holland (1988), Gleason (1999)).
Test for trend.
The test that examines the existence of a trend can be calculated in the same situation as ANOVA for dependent variables, because it is based on the same assumptions, but it captures the alternative hypothesis differently – indicating in it the existence of a trend of mean values in successive measurements. The analysis of the trend in the arrangement of means is based on contrasts Fisher LSD test. By building appropriate contrasts, you can study any type of trend, e.g. linear, quadratic, cubic, etc. A table of example contrast values for selected trends can be found in the description of the testu dla trendu for ANOVA of independent variables.
Linear trend
Trend liniowy, tak jak pozostałe trendy, możemy analizować wpisując odpowiednie wartości kontrastów. Jeśli jednak znany jest kierunek trendu liniowego, wystarczy skorzystać z opcji Trend liniowy i wskazać oczekiwaną kolejność populacji przypisując im kolejne liczby naturalne.
A linear trend, like other trends, can be analyzed by entering the appropriate contrast values. However, if the direction of the linear trend is known, simply use the Fisher LSD test option and indicate the expected order of the populations by assigning them consecutive natural numbers.
With the expected direction of the trend known, the alternative hypothesis is one-sided and the one-sided p-values is interpreted. The interpretation of the two-sided p-value means that the researcher does not know (does not assume) the direction of the possible trend.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
The settings window with the Single-factor repeated-measures ANOVA can be opened in Statistics menu→Parametric tests→ANOVA for dependent groups or in ''Wizard''.
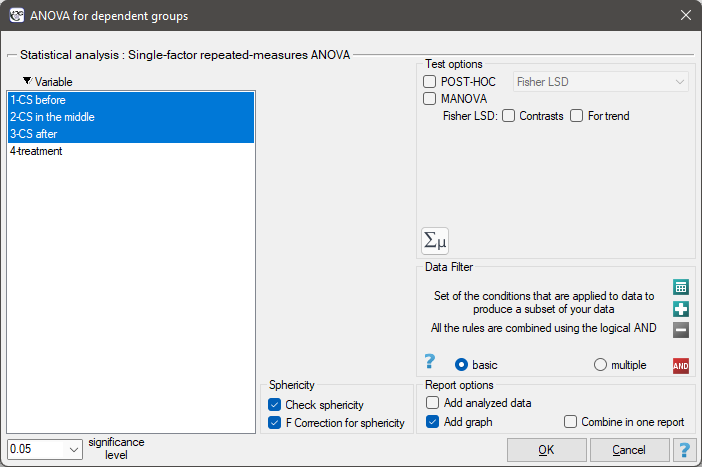
EXAMPLE (pressure.pqs file)
en/statpqpl/porown3grpl/parpl/anova_repeatedpl.txt · ostatnio zmienione: 2022/02/13 11:56 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
