Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:metapl:regresja
Spis treści
Meta-regression
Meta-regression analysis is conducted in an analogous manner to the regression analysis described in the section Multiple Regression. In the case of meta-regression, the study objects are the individual studies, their results (e.g., odds ratios, relative risks, differences in means) constitute the dependent variable  i.e., the explained variable, and the additional conditions for conducting these studies constitute the independent variables (
i.e., the explained variable, and the additional conditions for conducting these studies constitute the independent variables ( ,
,  ,
,  ,
,  ) i.e., the explanatory variables. As in traditional regression models, the independent variables may interact and those described by a nominal scale may be subject to special coding (for more information, see Preparation of the variables for analysis in multivariate models). The number of independent variables should be small, less than the number of papers on which the study is based on (
) i.e., the explanatory variables. As in traditional regression models, the independent variables may interact and those described by a nominal scale may be subject to special coding (for more information, see Preparation of the variables for analysis in multivariate models). The number of independent variables should be small, less than the number of papers on which the study is based on ( ).
).
We can perform meta-regression by choosing a fixed effect or a random effect.
- Fixed effect is chosen when we assume that the studies represent one common true effect such that all factors that could perturb the magnitude of this effect are the same except for the factors tested as independent variables in the model (, , , ). This is a situation that occurs very rarely in real research because it requires fully controlled conditions, which is almost impossible in different studies, conducted in different locations and by different researchers. The use of fixed effect would be justified, for example, in a situation when all the tests are carried out at the same location, on the same population, changing only those conditions that are described by the characteristic being tested. For example, if we wanted to test the effect of changing temperature on changing the relative risk of disease described in each study, then all studies should be conducted on the same population under exactly the same conditions except for the change in temperature, which is the independent variable
 in the model.
in the model. - Random effect is chosen when we assume that studies may represent slightly different populations, i.e., factors that could perturb the magnitude of the effect under study are not described in all papers (they can be assumed to be similar, but not necessarily exactly the same). Each paper provides the magnitudes of the factors we are interested in, which are involved in model building as independent variables (, , , ). The use of a random effect is common because individual studies are usually conducted at different locations under slightly different conditions, the variability of interest is only in the conditions that describe the factors given in the study, e.g., temperature, which will be the independent variable in the model.
Model verification
- Statistical significance of individual variables in the model.
Based on the coefficient and its error, we can conclude whether the independent variable for which this coefficient was estimated has a significant effect on the final effect. For this purpose, we test the hypotheses:

Calculate the test statistic using the formula:

Test statistics has the normal distribution.
The p value, designated on the basis of the test statistic, is compared with the significance level  :
:

- Quality of the built model of a linear multivariate regression can be assessed by several measures.
- Coefficient
 – is a measure of model fit. It expresses the percentage of variability between study effects explained by the model.
– is a measure of model fit. It expresses the percentage of variability between study effects explained by the model.
The value of this coefficient is in the range  , where 1 means a perfect fit of the model, 0 – a complete lack of fit. In determining it we use the following equation:
, where 1 means a perfect fit of the model, 0 – a complete lack of fit. In determining it we use the following equation:

where:
 – variance between studies explained by the model,
– variance between studies explained by the model,
 – total variance between studies.
– total variance between studies.
- Coefficient
 – determines the percentage of the observed variance that results from the true difference in the magnitude of the effects under study.
– determines the percentage of the observed variance that results from the true difference in the magnitude of the effects under study.
Note
For a detailed representation of the variance described by the coefficients, see chapter Testing heterogeneity
- Statistical significance of all variables in the model
The primary tool for estimating the significance of all variables in the model is an ANOVA that determines  (of the model).
(of the model).

Using the ANOVA approach, the observed variance between tests is broken into the variance explained by the model and the variance of the residual (not explained by the model). As a result, the following statistics are determined:
- The statistic (of the residuals) - examines the portion of the total variance that is not explained by the model,
- The statistic (of the model) - examines the portion of the total variance that is explained by the model,
- The statistic (total) - examines the variance between all studies.
Each of the above statistics has chi-square distribution with the appropriate number of degrees of freedom.
The p value, designated on the basis of the test statistic, is compared with the significance level :
The window with settings of group comparison for meta-analysis is opened via menu: Advanced Statistics→Meta-analysis→Meta-regression.
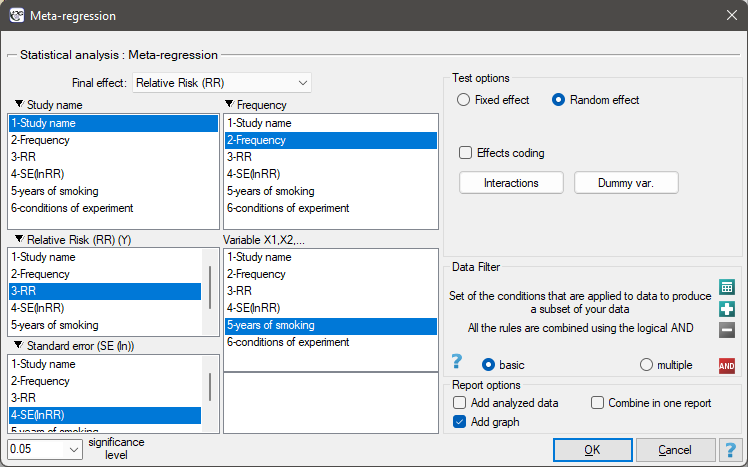
EXAMPLE cont. (MetaAnalysisRR.pqs file)
The risk of disease X was examined for smokers and non-smokers. A meta-analysis comparing groups of studies was conducted to determine whether the number of years of smoking affected the onset of disease X and whether different conditions of the experiment resulted in different relative risks. On the basis of the comparison of the groups of studies, it was possible to establish that the last group (the group of smokers who have been smoking the longest, i.e. for more than 10 years) shows an association between smoking and the onset of disease X. On the other hand, for the groups with shorter smoking duration, no significant effect could be obtained. However, it was observed that the effect systematically increased with increasing years of smoking. To test the hypothesis of a significant increase in the risk of disease X with increasing years of smoking, two regression models were constructed. In the first model, the grouping variable Years of smoking was treated as a continuous variable. In the second model, it was determined that the variable Years of smoking would be treated as a categorical (dummy) variable with the reference group smoking less than 5 years. Data were prepared for meta-regression and stored in a file.
Because the papers included in the meta-analysis were from different locations and included slightly different populations, the meta-regression was performed by selecting random effect. The relative risk was selected as the final effect, and the results were presented in the graph.


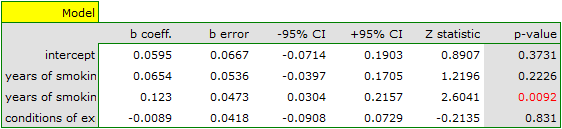
Both models confirmed a significant association between the duration of smoking and the magnitude of the relative risk of disease X. In the first model, the logarithm of the relative risk of disease X increased by 0.0614 with increasing time of smoking (moving to the subsequent group of years of smoking). Analysis of the results of the second model leads to similar conclusions. In this case, the results are considered for the group of smokers smoking less than 5 years. The logarithm of relative risk for smokers between 5 and 10 years increases by 0.0666 (relative to smokers younger than 5 years), and for smokers older than 10 years it increases by 0.1218 (relative to smokers younger than 5 years).
Since part of the study was conducted according to other criteria (under different conditions) the obtained results of both models were corrected for different conditions of the study.

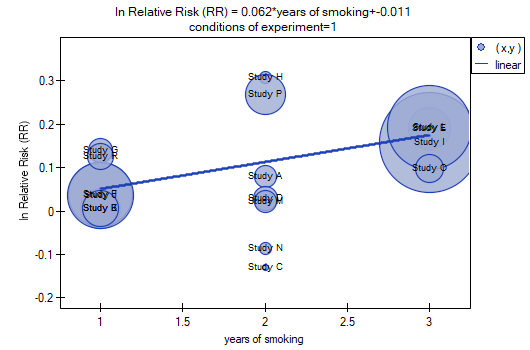
The correction performed did not change the underlying trend, and thus it can be concluded that the risk of disease X increases with years of smoking regardless of what methodology (inclusion/exclusion criteria of subjects) was used to conduct the study. The resulting relation for the first model, assuming that the study was conducted under condition „a” (indicated as first conditions) is shown in the graph.
en/statpqpl/metapl/regresja.txt · ostatnio zmienione: 2022/03/19 13:01 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
