Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:wielowympl:wielorpl:predpl
Predykcja na podstawie modelu i walidacja zbioru testowego
Walidacja
Walidacja modelu to sprawdzenie jego jakości. W pierwszej kolejności wykonywana jest na danych, na których model był zbudowany (tzw. zbiór uczący), czyli zwracana jest w raporcie opisującym uzyskany model. By można było z większą pewnością osądzić na ile model nadaje się do prognozy nowych danych, ważnym elementem walidacji jest zostanie modelu do danych, które nie były wykorzystywane w estymacji modelu. Jeśli podsumowanie w oparciu o dane uczące będzie satysfakcjonujące tzn. wyznaczane błędy, współczynniki  i kryteria informacyjne będą na zadowalającym nas poziomie, a podsumowanie w oparciu o nowe dane (tzw. zbiór testowy) będzie równie korzystne, wówczas z dużym prawdopodobieństwem można uznać, że taki model nadaje się do predykcji. Dane testujące powinny pochodzić z tej samej populacji, z której były wybrane dane uczące. Często jest tak, że przed przystąpieniem do budowy modelu zbieramy dane, a następnie w sposób losowy dzielimy je na zbiór uczący, czyli dane które posłużą do budowy modelu i zbiór testowy, czyli dane które posłużą do dodatkowej walidacji modelu.
i kryteria informacyjne będą na zadowalającym nas poziomie, a podsumowanie w oparciu o nowe dane (tzw. zbiór testowy) będzie równie korzystne, wówczas z dużym prawdopodobieństwem można uznać, że taki model nadaje się do predykcji. Dane testujące powinny pochodzić z tej samej populacji, z której były wybrane dane uczące. Często jest tak, że przed przystąpieniem do budowy modelu zbieramy dane, a następnie w sposób losowy dzielimy je na zbiór uczący, czyli dane które posłużą do budowy modelu i zbiór testowy, czyli dane które posłużą do dodatkowej walidacji modelu.
Okno z ustawieniami opcji walidacji wywołujemy poprzez menu Statystyki zaawansowane→Modele wielowymiarowe→Regresja wieloraka - predykcja/walidacja.
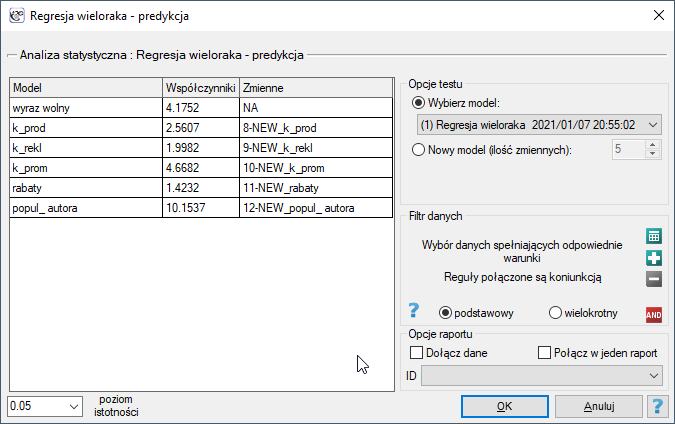
By dokonać walidacji należy wskazać model, na podstawie którego chcemy jej dokonać. Walidacji możemy dokonać na bazie:
- zbudowanego w PQStat modelu regresji wielorakiej - wystarczy wybrać model spośród modeli przypisanych do danego arkusza, a liczba zmiennych i współczynniki modelu zostaną ustawione automatycznie; zbiór testowy powinien się znaleźć w tym samym arkuszu co zbiór uczący;
- modelu niezbudowanego w programie PQStat ale uzyskanego z innego źródła (np. opisanego w przeczytanej przez nas pracy naukowej) - w oknie analizy należy podać liczbę zmiennych oraz wpisać współczynniki dotyczące każdej z nich.
W oknie analizy należy wskazać te nowe zmienne, które powinny zostać wykorzystane do walidacji.
Predykcja
Najczęściej ostatnim etapem analizy regresji jest wykorzystanie zbudowanego i uprzednio zweryfikowanego modelu do predykcji.
- Predykcja dla jednego obiektu może być wykonywana wraz z budową modelu, czyli w oknie analizy
Statystyki zaawansowane→Modele wielowymiarowe→Regresja wieloraka, - Predykcja dla większej grupy nowych danych jest wykonywana poprzez menu
Statystyki zaawansowane→Modele wielowymiarowe→Regresja wieloraka - predykcja/walidacja.
By dokonać predykcji należy wskazać model, na podstawie którego chcemy jej dokonać. Predykcji możemy dokonać na bazie:
- zbudowanego w PQStat modelu regresji wielorakiej - wystarczy wybrać model spośród modeli przypisanych do danego arkusza, a liczba zmiennych i współczynniki modelu zostaną ustawione automatycznie; zbiór testowy powinien się znaleźć w tym samym arkuszu co zbiór uczący;
- modelu niezbudowanego w programie PQStat ale uzyskanego z innego źródła (np. opisanego w przeczytanej przez nas pracy naukowej) - w oknie analizy należy podać liczbę zmiennych oraz wpisać współczynniki dotyczące każdej z nich.
W oknie analizy należy wskazać te nowe zmienne, które powinny zostać wykorzystane do predykcji. Oszacowana wartość wyliczana jest z pewnym błędem. Dlatego też dodatkowo dla przewidzianej przez model wartości wyznaczane są granice wynikające z błędu:
- dla wartości oczekiwanej wyznaczane są granice ufności,
- dla pojedynczego punktu wyznaczane są granice predykcji.
Przykład c.d. (plik wydawca.pqs)
Do przewidywania zysku brutto ze sprzedaży książek wydawca zbudował model regresji w oparciu o zbiór uczący pozbawiony pozycji 16 (czyli 39 książek). W modelu znalazły się: koszty produkcji, koszty reklamy i popularność autora (1=autor popularny, 0=nie). Zbudujemy raz jeszcze ten model w oparciu zbiór uczący a następnie, by się upewnić, że model będzie działał poprawnie, zwalidujemy go na testowym zbierze danych. Jeśli model przejdzie tę próbę, to będziemy go stosować do predykcji dla pozycji książkowych. By korzystać z odpowiednich zbiorów ustawiamy każdorazowo filtr danych.
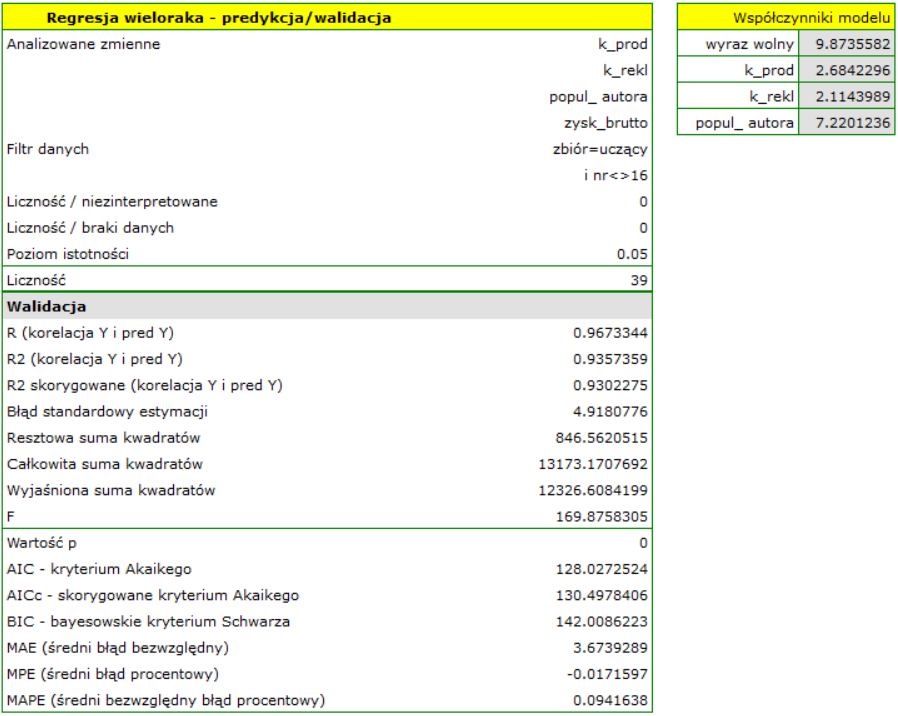
Dla zbioru uczącego wartości opisujące jakość dopasowania modelu są bardzo wysokie: skorygowane = 0.93 a średni błąd prognozy (MAE) wynosi 3.8 tys. dolarów.
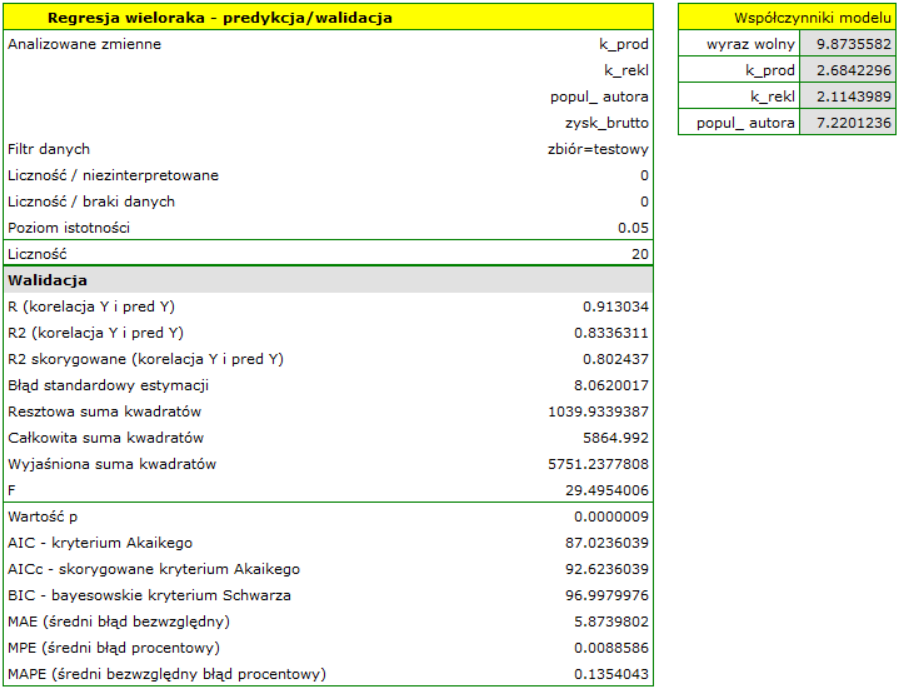
Dla zbioru testowego wartości opisujące jakość dopasowania modelu są nieco niższe niż dla zbioru uczącego: Skorygowane = 0.80 a średni błąd prognozy (MAE) wynosi 5.9 tys. dolarów. Ponieważ wynik walidacji na zbiorze testowym jest prawie tak dobry jak na zbiorze uczącym, użyjemy modelu do predykcji. W tym celu skorzystamy z danych trzech nowych pozycji książkowych dopisanych na końcu zbioru. Wybierzemy opcję Predykcja, ustawiany filtr na nowy zbiór danych i użyjemy naszego modelu do tego by przewidzieć zysk brutto dla tych książek.
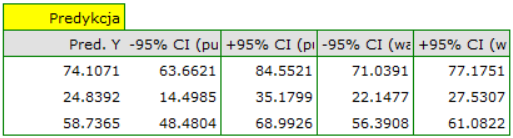
Okazuje się, że najwyższy zysk brutto (pomiędzy 64 a 85 tys. dolarów) jest prognozowany dla pierwszej, najbardziej reklamowanej i najdrożej wydanej książki popularnego autora.
statpqpl/wielowympl/wielorpl/predpl.txt · ostatnio zmienione: 2023/04/01 18:25 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
