Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:usepl:arkpl:misspl
Braki danych

 W badaniach bardzo często napotykamy na braki danych, jest to naturalne szczególnie dla danych ankietowych. Bywają sytuacje, w których braki danych wnoszą wartościową informację. Przykładowo: ilość braków danych w odpowiedzi na pytanie dotyczące sympatii do partii politycznych daje pogląd o ilości niezdecydowanych osób, które nie darzą sympatią (lub nie przyznają się że darzą sympatią) określonych ugrupowań politycznych. Niewielkie liczności braków danych nie stanowią problemu w analizach statystycznych. Duża ich ilość może jednak poddawać pod wątpliwość rzetelność przeprowadzonych badań. Warto już na początku pracy zadbać by było ich jak najmniej. Oczywiście najlepiej jest dotrzeć do informacji o rzeczywistej wartości, która powinna być wpisana w miejsce braku danych, jednak nie zawsze jest to możliwe.
W badaniach bardzo często napotykamy na braki danych, jest to naturalne szczególnie dla danych ankietowych. Bywają sytuacje, w których braki danych wnoszą wartościową informację. Przykładowo: ilość braków danych w odpowiedzi na pytanie dotyczące sympatii do partii politycznych daje pogląd o ilości niezdecydowanych osób, które nie darzą sympatią (lub nie przyznają się że darzą sympatią) określonych ugrupowań politycznych. Niewielkie liczności braków danych nie stanowią problemu w analizach statystycznych. Duża ich ilość może jednak poddawać pod wątpliwość rzetelność przeprowadzonych badań. Warto już na początku pracy zadbać by było ich jak najmniej. Oczywiście najlepiej jest dotrzeć do informacji o rzeczywistej wartości, która powinna być wpisana w miejsce braku danych, jednak nie zawsze jest to możliwe.
Sposób w jaki szacowane są brakujące dane zależy przede wszystkim od charakteru danych. W programie zaproponowano kilka sposobów imputacji braków danych dla poszczególnych zmiennych.
Okno z ustawieniami opcji zastępowania braków danych wywołujemy poprzez menu Dane→Braki danych…
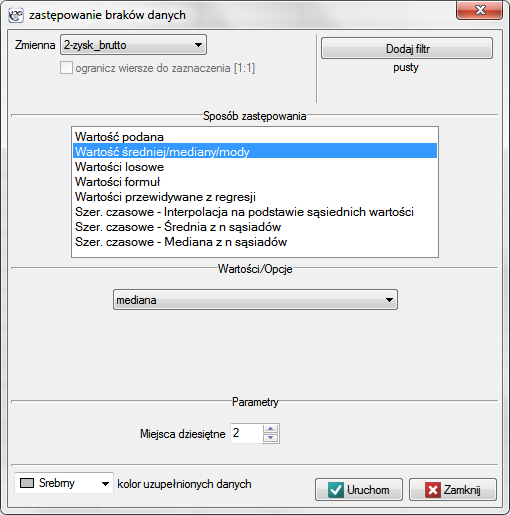
- Wypełnianie jedną wartością
Wybranie jednej z poniższych opcji spowoduje zastąpienie w wybranej kolumnie wszystkich występujących tam braków tą samą wartością:- podaną przez użytkownika,
- średnią arytmetyczną wyliczoną z danych,
- średnią geometryczną wyliczoną z danych,
- średnią harmoniczną wyliczoną z danych,
- medianą,
- modą (o ile nie jest wielokrotna).
- Wypełnianie wieloma wartościami
Wybranie jednej z poniższych opcji spowoduje zastąpienie braków w wybranej kolumnie wieloma (najczęściej różnymi) wartościami. Wartości te mogą być przewidywane na podstawie kolumny, dla której następuje wypełnienie braków danych ale mogą być również przewidywane na podstawie wartości innych kolumn (zmiennych). Zastąpić brak danych możemy wartościami:
- losowymi z danych;
- losowymi z rozkładu normalnego - rozkład normalny definiowany jest na podstawie średniej i odchylenia standardowego z występujących danych;
- losowymi z przedziału podanego przez użytkownika;
- wyliczanymi z funkcji użytkownika - opcja ta pozwala na wykorzystanie danych z innych zmiennych by móc przewidzieć brakującą wartość w wybranej kolumnie;
- wyliczanymi z modelu regresji - opcja ta pozwala na przewidywanie wartości braków danych na podstawie modelu regresji wielorakiej (zasada działania regresji wielorakiej opisana została w dziale ''Liniowa regresja wieloraka'');
- interpolacja na podstawie sąsiednich wartości - dotyczy szeregów czasowych - użytkownik musi więc wskazać zmienną czas mówiącą o uporządkowaniu danych; interpolacja polega na wyznaczeniu wartości dla braków danych w ten sposób by graficznie znalazły się na linii prostej łączącej wartości dla danych sąsiadujących z brakami;
- średnia z
 sąsiadów - dotyczy szeregów czasowych - użytkownik musi więc wskazać zmienną czas mówiącą o uporządkowaniu danych; interpolacja polega na wyznaczeniu średniej z wartości dla sąsiadów poprzedzających i sąsiadów następujących bezpośrednio po brakach danych;
sąsiadów - dotyczy szeregów czasowych - użytkownik musi więc wskazać zmienną czas mówiącą o uporządkowaniu danych; interpolacja polega na wyznaczeniu średniej z wartości dla sąsiadów poprzedzających i sąsiadów następujących bezpośrednio po brakach danych; - mediana z sąsiadów - dotyczy szeregów czasowych - użytkownik musi więc wskazać zmienną czas mówiącą o uporządkowaniu danych; interpolacja polega na wyznaczeniu mediany z wartości dla sąsiadów poprzedzających i z sąsiadów następujących bezpośrednio po brakach danych;
Uwaga!
By można było odróżnić dane, które zostały imputowane od danych rzeczywistych, miejsca zastąpione oznaczane są wybranym kolorem.
Przykład (plik: brakiDanychWydawca.pqs)
Analiza pliku wydawca.pqs nie zawierającego braków danych została omówiona w dziale ''Liniowa regresja wieloraka''. Tym razem zajmiemy się arkuszem w którym w kolumnie zawierającej zysk brutto ze sprzedaży książek występują braki danych. W przypadku tych braków znane są wartości rzeczywiste (arkusz: „RZECZYWISTE DANE”), można zatem odnieść wartości wygenerowane w programie dla braków danych do wartości rzeczywistych by porównać wyniki uzyskane różnymi technikami. W przykładzie wykorzystamy 2 sposoby zastępowania braków danych: zastąpienie wartością mediany i wartością wyznaczoną na podstawie modelu regresji. Pozostałe możliwości pozostawiamy do samodzielnej pracy.
Zastąpienie braków danych wartością mediany wykonujemy na arkuszu pierwszym nazwanym „Wstaw medianę”. Ustawiamy w oknie Braków danych zmienną uzupełnianą jako zysk brutto i wybieramy sposób zastępowania jako wartość mediany. W rezultacie w miejsce braków danych wpisana zostanie wartość 46,85 tysięcy dolarów.
Podejrzewamy, że zyski są większe, gdy dotyczą książek znanych autorów (kodowanych jako 1) a mniejsze, gdy dotyczą tych nieznanych (kodowanych jako 0). Wyliczymy więc medianę zysku brutto oddzielnie dla książek autorów znanych i nieznanych. Imputację wykonujemy na arkuszu danych o nazwie „Wstaw dwie mediany”. Ustawiamy dwukrotnie filtr dla zmiennej definiującej popularność autora (zmienna 7) - raz podając wartość 1, a raz 0. Uzyskana mediana zysku brutto w grupie książek autorów popularnych to ok. 51 tysięcy dolarów, a wśród tych mniej znanych to ok. 34 tysiące dolarów.
Innym sposobem zastępowania braków jest np. skorzystanie z modelu regresji. Wybieramy arkusz danych „Wstaw z regresji” i ponownie wybieramy w oknie Braków danych zmienną dotyczącą zysku brutto jako zmienną, którą należy uzupełnić, jako sposób zastępowania wybieramy natomiast Wartości przewidywane z regresji. Zmiennych dzięki którym będziemy przewidywać wartość zysku brutto będzie tym razem więcej - będą to: koszty produkcji (zmienna 3), koszty reklamy (zmienna 4) i popularność autora (zmienna 7). Tym razem wyniki wydają się mniej odbiegać od rzeczywistych wartości, niestety brakuje wyniku dla pozycji o numerze 35. Dla tej książki nie mieliśmy bowiem informacji o koszcie produkcji na którym to między innymi chcieliśmy oprzeć przewidywanie.
statpqpl/usepl/arkpl/misspl.txt · ostatnio zmienione: 2015/11/17 22:58 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
