Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:metapl:wpr
Wprowadzenie

Najbardziej znanym obrazem związanym z meta-analizą jest wykres leśny przedstawiający wyniki poszczególnych badań wraz z ich podsumowaniem.
(2.6,4)
\rput(-0.8,0.8){\scriptsize Podsumowanie}
\psdiamond[framearc=.3,fillstyle=solid, fillcolor=lightgray](2.6,0.8)(0.4,0.15)
\rput(-0.6,1.575){\scriptsize Badanie 5}
\psline[linewidth=0.2pt](2.3,1.575)(2.9,1.575)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](2.5,1.5)(2.65,1.65)
\rput(-0.6,2.1){\scriptsize Badanie 4}
\psline[linewidth=0.2pt](2.53,2.1)(3.1,2.1)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](2.7,2)(2.9,2.2)
\rput(-0.6,2.54){\scriptsize Badanie 3}
\psline[linewidth=0.2pt](1,2.54)(3.35,2.54)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](2,2.5)(2.08,2.58)
\rput(-0.6,3.04){\scriptsize Badanie 2}
\psline[linewidth=0.2pt](1.25,3.04)(3.25,3.04)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](2.1,3)(2.18,3.08)
\rput(-0.6,3.55){\scriptsize Badanie 1}
\psline[linewidth=0.2pt](0.85,3.55)(2.5,3.55)
\psframe[linewidth=0.1pt,framearc=.1,fillstyle=solid, fillcolor=lightgray](1.5,3.5)(1.6,3.6)
\rput(2.4,-0.3){\scriptsize Wielkość efektu}
\end{pspicture}](/lib/exe/fetch.php?media=wiki:latex:/imgcefa9473f83c5b0ad44d1798ab1d101b.png "LaTeX")
Aby można było dokonać wspólnego podsumowania wybranej literatury musi być ona spójna w opisie, a podane tam miary muszą być tożsame.
By dana praca naukowa mogła być wykorzystana w meta-analizie powinna opisywać: Efekt końcowy czyli pewnego rodzaju miarę statystyczną wskazującą na uzyskany w pracy wynik (efekt). W rzeczywistości mogą to być różnego rodzaju wielkości np. różnica pomiędzy wartościami średnimi, iloraz szans, relatywne ryzyko itp.
Błąd efektu czyli SE (ang. Standard Error) pozwalający określić precyzję przeprowadzonego badania. Owa precyzja nadaje wagę badania. Im mniejszy jest błąd (SE), tym większa jest precyzja danego badania i tym przypisana waga będzie wyższa, przez co dane badanie będzie miało większy wpływ na wyniki meta-analizy.
Liczność jest to liczba obiektów na jakiej przeprowadzone zostało badanie.
Uwaga! Często zdarza się, że praca naukowa nie zawiera wszystkich wymienionych wyżej elementów, wówczas należy szukać w niej danych, na podstawie których wyliczenie tych miar będzie możliwe.
Uwaga! Program PQstat obliczenia związane z meta-analizą wykonuje na danych zawierających: Efekt końcowy, Błąd efektu i w niektórych sytuacjach Liczność. Zaleca się, aby przed przystąpieniem do meta-analizy wprowadzić dane dotyczące każdej publikacji w oknie przygotowania danych. Jest to szczególnie przydatne w przypadku kiedy w danej pracy nie podano wprost tych trzech miar.
Okno przygotowania danych wywołujemy poprzez menu:
Statystyki zaawansowane→Meta-analiza→Przygotowanie danych.
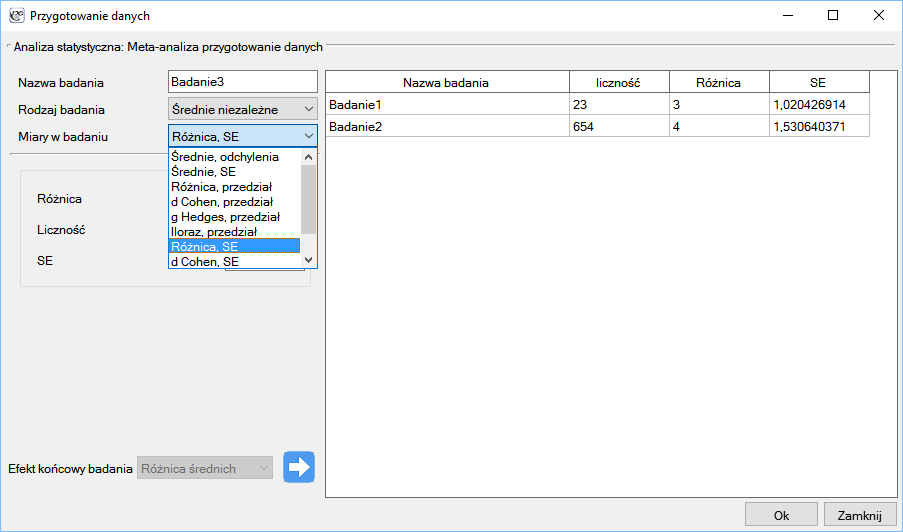
W oknie przygotowania danych do meta-analizy badacz najpierw podaje nazwę wprowadzanego badania. Nazwa ta powinna jednoznacznie identyfikować badanie, ponieważ będzie je opisywać we wszystkich wynikach meta-analizy, w tym również na wykresach. Pożądany Efekt końcowy badania Błąd efektu i Liczność zostają wyliczone w oparciu o miary pozyskane z odpowiedniej pracy naukowej. Miary zawarte w badaniach na podstawie których mogą być wyliczone efekty końcowe, przedstawia poniższa tabela:

gdzie poszczególne efekty końcowe, to:
a - Różnica średnich
b - d Cohen
c - g Hadges
d - Średnia
e - Iloraz średnich
f - Iloraz szans (OR)
g - Relatywne ryzyko (RR)
h - Różnica ryzyka (RD)
i - Współczynnik Pearsona
j - AUC (krzywa ROC)
k - Proporcja
Uwaga! Przy wyznaczaniu błędu współczynników takich jak OR lub RR i innych opartych na tabelach, gdy występują zerowe wartości w tabelach lub przy wyznaczaniu błędu proporcji, gdy proporcja wynosi 0 lub 1, stosowana jest korekta na ciągłość wykorzystująca współczynnik zwiększenia równy 0,5. Przedział ufności dla proporcji wyznaczany jest zgodnie z dokładną metodą Cloppera-Pearsona1).
Jesteśmy zainteresowani wpływem palenia papierosów na ryzyko wystąpienia choroby X. Chcemy przeprowadzić meta-analizę, dla której efektem końcowym będzie relatywne ryzyko (RR). Przy takim założeniu, prace wytypowane do meta-analizy muszą mieć możliwość wyliczenia RR i jego błędu.
Krok 1. Na podstawie opisu efektu końcowego (patrz powyższa tabela) ustalono, że relatywne ryzyko (opisane jako wynik g) jest możliwe do wyznaczenia w programie PQStat w trzech sytuacjach tzn. jeżeli w danej pracy naukowej podano: RR i przedział ufności dla niego lub RR wraz z błędem, lub gdy podane są odpowiednie liczności w czterech kategoriach tzn. tabela 2×2.
Krok 2. Wytypowano do meta-analizy 10 prac, które spełniały kryteria włączenia do badań oraz miały możliwość wyznaczenia relatywnego ryzyka (patrz krok 1). Potrzebne dane zawarte w wytypowanych pracach to:
Badanie 1: liczności: (palący i chorujący)=100, (palący i niechorujący)=73, (niepalący i chorujący)=80, (niepalący i niechorujący)=70,
Badanie 2: liczności: (palący i chorujący)=182, (palący i niechorujący)=172, (niepalący i chorujący)=180, (niepalący i niechorujący)=172,
Badanie 3: liczności: (palący i chorujący)=157, (palący i niechorujący)=132, (niepalący i chorujący)=125, (niepalący i niechorujący)=201,
Badanie 4: liczności: (palący i chorujący)=19, (palący i niechorujący)=15, (niepalący i chorujący)=35, (niepalący i niechorujący)=20,
Badanie 5: liczność: 278, RR[95%CI]=1.03[0.85-1.25],
Badanie 6: liczność: 560, RR[95%CI]=1.21[1.05-1.40],
Badanie 7: liczność: 1207, RR[95%CI]=1.04[0.93-1.15],
Badanie 8: liczność: 214, RR[95%CI]=1.15[0.95-1.40],
Badanie 9: liczność: 285, RR[95%CI]=1.36[1.03-1.79],
Badanie 10: liczność: 1968, RR=1.17, SE(lnRR)=0.0437,
Krok 3. Korzystając z okna przygotowania badań do meta-analizy wprowadzono dane do arkusza. Pierwsze cztery badania wprowadzamy wybierając tabele, badania od piątego do dziewiątego wprowadzamy wybierając RR i przedział, ostatnie badanie podaje wszystkie niezbędne dane tzn. RR i SE. Jeko Efekt końcowy badania ustawiamy Relatywne ryzyko (RR):
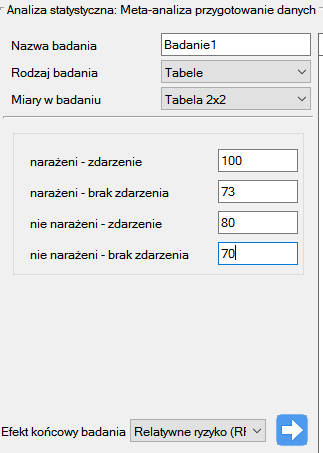
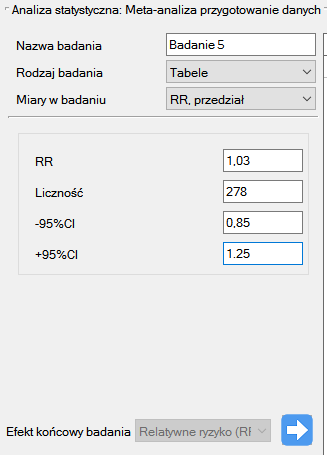
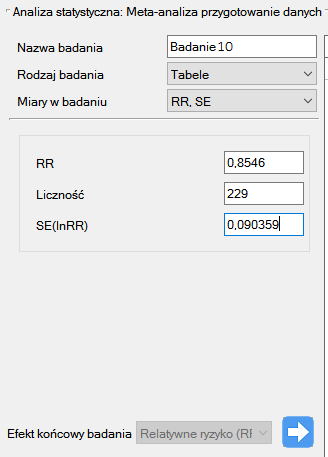
Każde wprowadzone badanie przenosimy do okna po prawej stronie  . Przyciskiem
. Przyciskiem OK przenosimy przygotowane badania do arkusza danych. Na podstawie zawartych w arkuszu informacji o poszczególnych badaniach można przystąpić do wykonywania meta-analizy.}
Wartość p, a więc istotność statystyczna nie jest bezpośrednio wykorzystywana w meta-analizie. Ta sama wielkość efektu może być istotna statystycznie w badaniu dużym, a nieistotna w badaniu opartym na małej liczności. Co więcej, zupełnie mała wielkość efektu może być istotna statystycznie w badaniu dużym, a całkiem duża wielkość efektu może być nieistotna w badaniu małym. Fakt ten związany jest z mocą testów statystycznych. Badając istotność statystyczną sprawdzamy czy efekt w ogóle istnieje, tzn. czy jest różny od zera, a nie czy jest on na tyle duży by miał przełożenie na pożądane skutki. Na przykład fakt, że lek obniża ciśnienie istotnie statystycznie o 1mmHg nie spowoduje że będzie stosowany, gdyż z klinicznego punktu widzenia 1 mmHg jest zbyt małą wielkością. Meta-analiza skupia swoje działanie na wielkości poszczególnych efektów a nie na ich istotności statystycznej. W rezultacie nie ma większego znaczenia, czy prace wykorzystywane w meta-analizie wskazują na istotność statystyczną danego efektu czy też nie.
W programie PQStat, dla każdego badania wyliczana jest istotność statystyczna podana dla stosunku efektu i błędu tego efektu. Jest to podejście asymptotyczne, oparte na rozkładzie normalnym i dedykowane dla licznych grup. Jeśli w cytowanym badaniu do sprawdzenia istotności statystycznej użyto innego testu, uzyskane wyniki mogą się nieco różnić.
1)
Clopper C. and Pearson S. (1934), The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika 26: 404-413
statpqpl/metapl/wpr.txt · ostatnio zmienione: 2019/03/17 21:15 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
