Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:porown2grpl:nparpl:trendpl
The Chi-square test for trend
The  test for trend (also called the Cochran-Armitage trend test 1)2))is used to determine whether there is a trend in proportion for particular categories of an analysed variables (features). It is based on the data gathered in the contingency tables of 2 features. The first feature has the possible
test for trend (also called the Cochran-Armitage trend test 1)2))is used to determine whether there is a trend in proportion for particular categories of an analysed variables (features). It is based on the data gathered in the contingency tables of 2 features. The first feature has the possible  ordered categories:
ordered categories:  and the second one has 2 categories:
and the second one has 2 categories:  ,
,  .
The contingency table of
.
The contingency table of  observed frequencies
observed frequencies

Basic assumptions:
- measurement on an ordinal scale or on an interval scale,
- an independent model (the second feature - 2 independent groups).
Hypotheses:

where:
 are the proportions
are the proportions  ,
,  ,…,
,…,  .
.
The test statistic is defined by:
![\begin{displaymath}
\chi^2=\frac{\left[\left(\sum_{i=1}^r i\cdot O_{i1}\right) -C_1\left(\sum_{i=1}^r\frac{i\cdot W_i}{n}\right)\right]^2}{\frac{C_1}{n}\left(1-\frac{C_1}{n}\right)\left[\left(\sum_{i=1}^n i^2 W_i\right)-n\left(\sum_{i=1}^n\frac{i \cdot W_i}{n}\right)^2\right]}.
\end{displaymath}](/lib/exe/fetch.php?media=wiki:latex:/imgd32bd126527cf05771f082e9a0735129.png "LaTeX")
This statistic asymptotically (for large expected frequencies) has the Chi-square distribution with 1 degree of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

The settings window with the Chi-square test for trend can be opened in Statistics menu → NonParametric tests → Chi-square, Fisher, OR/RR → Chi-square for trend.
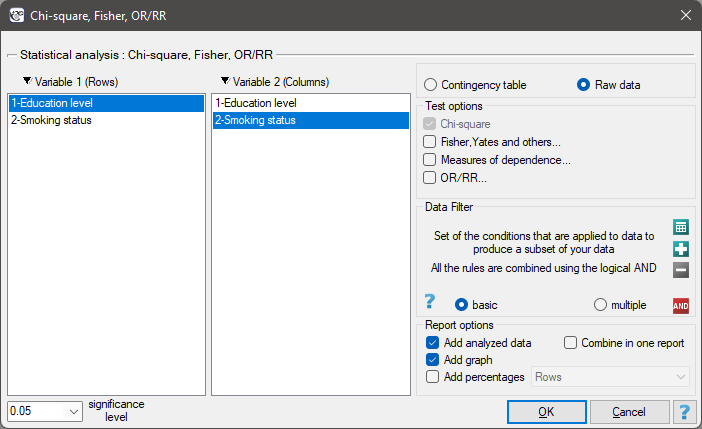
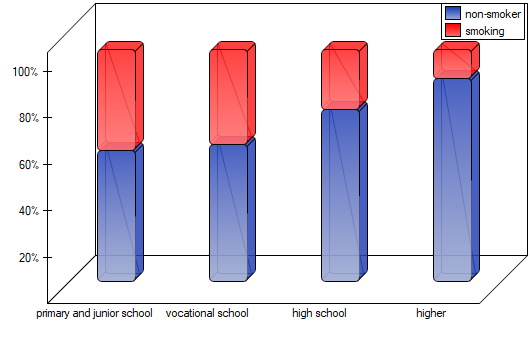
EXAMPLE (smoking-education.pqs file)
We examine whether cigarette smoking is related to the education of residents of a village. A sample of 122 people was drawn. The data were recorded in a file. }
We assume that the relationship can be of two types i.e. the more educated people, the more often they smoke or the more educated people, the less often they smoke. Thus, we are looking for an increasing or decreasing trend.
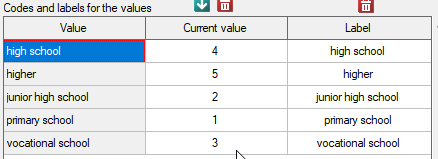
Before proceeding with the analysis, we need to prepare the data, i.e., we need to indicate the order in which the education categories should appear. To do this, from the properties of the Education variable, we select Codes/Labels/Format… and assign the order by specifying consecutive natural numbers. We also assign labels.
Hypotheses:


A p-value=0.0091, which compared to a significance level of =0.05 indicates that the alternative hypothesis that a trend exists is true.
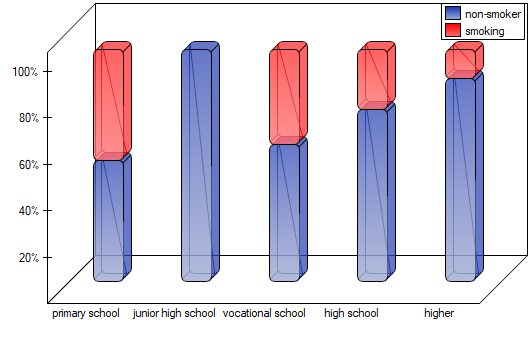
As the graph shows, the more educated people are, the less often they smoke. However, the result obtained by people with junior high school education deviates from this trend. Since there are only two people with lower secondary school education, it did not have much influence on the trend. Due to the very small size of this group, it was decided to repeat the analysis for the combined primary and lower secondary education categories.
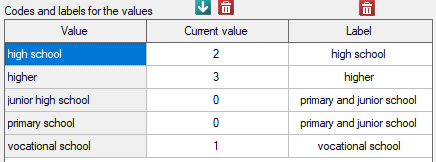
A small value was again obtained p=0.0078 and confirmation of a statistically significant trend.
Because of the decrease in people watching some particular soap opera there was carried out an opinion survey. 100 persons were asked, who has recently started watching this soap opera, and 300 persons were asked, who has watched it regularly from the beginning. They were asked about the level of preoccupation with the character's life. The results are written down in the table below:

The new viewers consist of 25\% of all the analysed viewers. This proportion is not the same for each level of commitment, but looks like this:

Hypotheses:

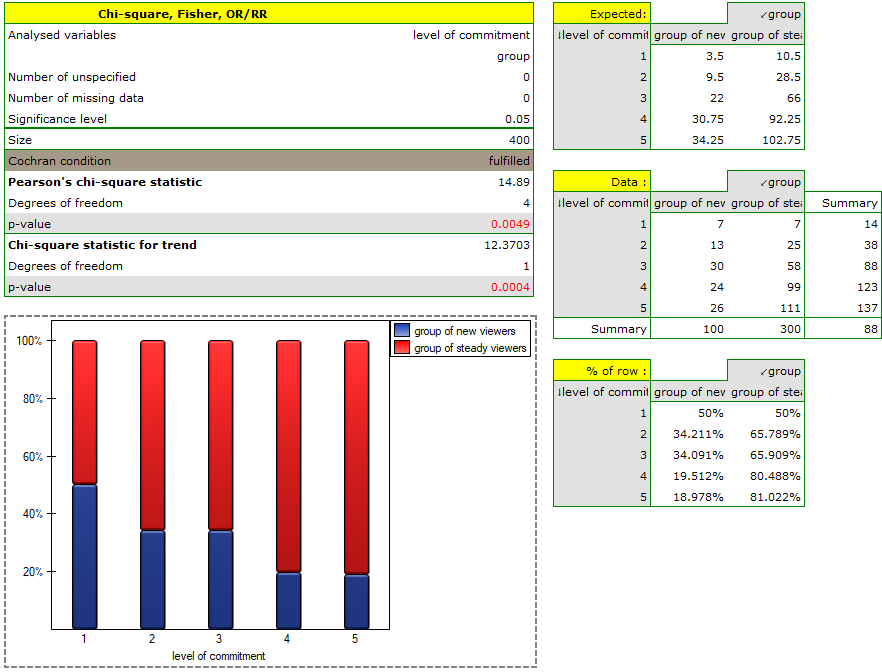
The p-value=0.0004 which, compared to the significance level =0.05, proves the truth of the alternative hypothesis that there is a trend in the proportions  . As can be seen from the contingency table of the percentages calculated from the sum of the columns, this is a decreasing trend (the more interested the group of viewers is in the fate of the characters of the series, the smaller part of it is made up of new viewers).
. As can be seen from the contingency table of the percentages calculated from the sum of the columns, this is a decreasing trend (the more interested the group of viewers is in the fate of the characters of the series, the smaller part of it is made up of new viewers).
en/statpqpl/porown2grpl/nparpl/trendpl.txt · ostatnio zmienione: 2022/02/12 13:17 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
