Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:przestrzenpl:autocorpl:ggarypl
Global Geary's C statistic
Similarly to Moran's analysis, global Geary's statistic studies the degree of the intensity of a given feature in spatial objects.
Note
It is not recommended to conduct Geary's analysis for objects without a neighborhood (objects described in a weight matrix only with the value 0). Such objects can be excluded from the analysis by deactivating them (Chapter Limiting the workspace), or the analysis can be made with the use of a different manner of defining neighborhood (a different weight matrix).
Geary's autocorrelation coefficient – introduced by Geary in 1954 1).
It is one of the possible alternatives for the global Moran's statistic. Similarly to Moran's analysis, Geary's statistic studies the degree of intensity of a given  feature in spatial objects described with the use of a weight matrix with
feature in spatial objects described with the use of a weight matrix with  elements. This time, instead of computing the sum of quotients:
elements. This time, instead of computing the sum of quotients:

we compute the sum of the difference squares:

As a result, Geary's autocorrelation coefficient is expressed with the formula:

where:
 – the number of spatial objects (the number of points or polygons),
– the number of spatial objects (the number of points or polygons),
,  – are the values of the variable for the compared objects,
– are the values of the variable for the compared objects,
– elements of the spatial weights matrix (weights matrix row standardized),
 ,
,
 – variance,
– variance,
 – it is the mean value of the variable for all objects.
– it is the mean value of the variable for all objects.
The interpretation of Geary's coefficient:
 and
and  means the occurrence of clusters with similar values – a positive autocorrelation;
means the occurrence of clusters with similar values – a positive autocorrelation; means the occurrence of the so-called hot spots, i.e. distinctly different values in neighboring areas – a negative autocorrelation;
means the occurrence of the so-called hot spots, i.e. distinctly different values in neighboring areas – a negative autocorrelation; means a random spatial distribution of the studied variable – a lack of autocorrelation.
means a random spatial distribution of the studied variable – a lack of autocorrelation.
Note
When the values of a studied feature are characterized by a great variability of variance then it is desirable to stabilize that variability. The basic information about smoothing variables have been described in the Chapter \ref{wygladz_przestrz} SPATIAL SMOOTHING
Significance of Geary's autocorrelation coefficient
A test for checking the significance of Geary's autocorrelation coefficient serves the purpose of verifying the hypothesis about a lack of spatial autocorrelation
Hypotheses:

The test statistic has the form presented below:

where:
 – the expected value,
– the expected value,
 – variance.
– variance.
Depending on the assumption concerning the distribution of the population from which the sample has been taken, the manner of selecting variance is chosen (Cliff and Ord (1981)2), and Goodchild (1986)3)). If it is a normal distribution, then:

where:
 and
and  are defined as for Moran's analysis.
are defined as for Moran's analysis.
If it is a random distribution, then:

where:
 ,
,
 .
.
Statistics  has, asymptotically (for large sample sizes), normal distribution.
has, asymptotically (for large sample sizes), normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

The window with settings for Geary's analysis is accessed via the men Spacial analysis → Spacial statistics → Global Geary's C statistic.
EXAMPLE cont. (catalog: leukemia, file: leukemia)
We will analyze the data concerning leukemia.
- The map
leukemiacontains information about the location of 281 polygons (census tracts) in the northern part of the state of New York. - Data for the map
leukemia:- Column
CASES– the number of cases of leukemia in the years 1978-1982, ascribed to particular objects (census tracts). The value should be an integral number, however, in agreement with Waller's (1994) description, some cases which could not be objectively ascribed to a particular region have been divided proportionately. Hence, the numerousnesses of the cases ascribed to the 281 objects are not integral numbers. - Column
POP– population size in particular objects. - Column
prev– the frequency coefficient of leukemia per 100000 people, for each object in one year: prev=(CASES/POP)*100000/5
Global Moran's analysis has pointed to a lack of spatial autocorrelation. This time, in order to check if in the studied area of the northern part of the state of New York it is possible to localize clusters of leukemia we will compute the global Geary's C statistic.
We start from the presentation of the geographic distribution of the prevalence coefficient (prev) on the map, according to the values of the prev variable, dividing it into quartiles:
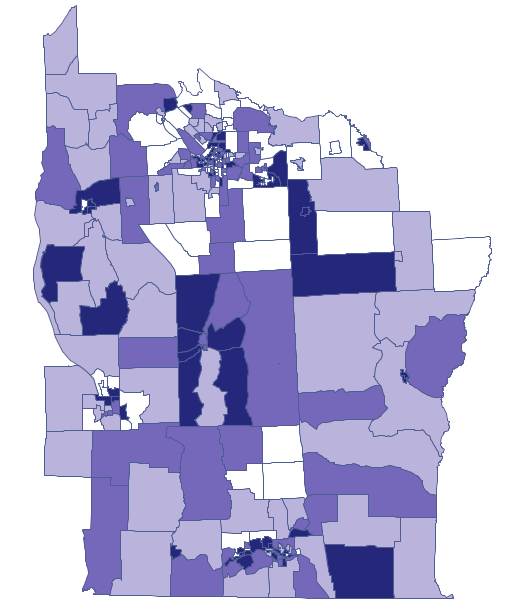
Dark colors on the map present the places with a higher prevalence of leukemia, whereas light places signify a lower prevalence. Geary's correlation coefficient obtained in the analysis equals: 0.884986.
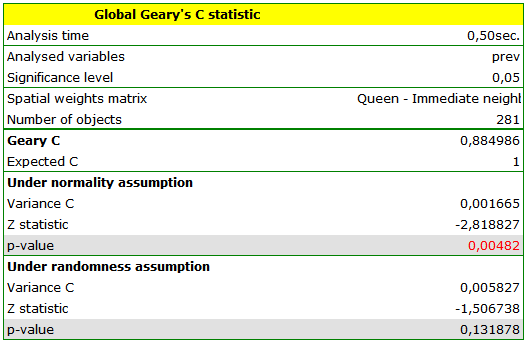
The obtained result, assuming a random distribution of data, is different from the result obtained with the assumption of a normal distribution. That can be indicative of an instability of the results and point to the need of further analyses based on smoothed variables.
en/przestrzenpl/autocorpl/ggarypl.txt · ostatnio zmienione: 2022/02/16 13:42 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
