Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:redpl:pcapl
Spis treści
Analiza składowych głównych
Okno z ustawieniami opcji Analizy składowych głównych wywołujemy poprzez menu Statystyki → Modele wielowymiarowe → Analiza składowych głównych.
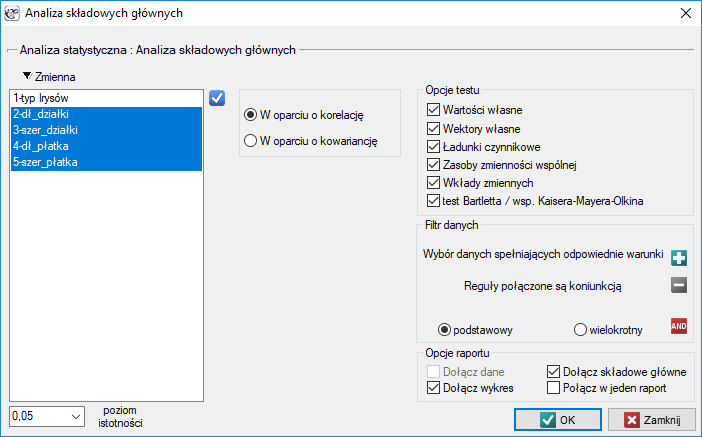
Analiza składowych głównych polega na wyznaczeniu zupełnie nowych zmiennych (składowych głównych) będących kombinacją liniową zmiennych obserwowanych (pierwotnych). Dokładna analiza składowych głównych umożliwia wskazanie tych zmiennych pierwotnych, które mają duży wpływ na wygląd poszczególnych składowych głównych czyli tych, które tworzą grupę jednorodną. Składowa główna jest wówczas reprezentantem tej grupy. Kolejne składowe są wzajemnie ortogonalne (nieskorelowane) a ich liczba ( ) jest mniejsza lub równa liczbie zmiennych pierwotnych (
) jest mniejsza lub równa liczbie zmiennych pierwotnych ( ).
).
Poszczególne składowe główne są kombinacją liniową zmiennych pierwotnych:
 gdzie:
gdzie:
 – zmienne pierwotne,
– zmienne pierwotne,
 – współczynniki
– współczynniki  -tej składowej głównej
-tej składowej głównej
Każda składowa główna wyjaśnia pewną część zmienności zmiennych pierwotnych. W naturalny sposób opiera się więc na takich miarach zmienności jak kowariancja (gdy zmienne pierwotne są podobnej wielkości i są wyrażone w tych samych jednostkach) lub korelacja (gdy założenia potrzebne do stosowana kowariancji nie są spełnione).
Obliczenia matematyczne pozwalające wyodrębnić składowe główne sprowadzają się do wyznaczenia wartości własnych i odpowiadających im wektorów własnych z równania macierzowego postaci:
 gdzie:
gdzie:
 – wartości własne,
– wartości własne,
 – wektor własny odpowiadający -tej wartości własnej,
– wektor własny odpowiadający -tej wartości własnej,
 – macierz wariancji lub kowariancji zmiennych pierwotnych ,
– macierz wariancji lub kowariancji zmiennych pierwotnych ,
 – macierz identycznościowa (1 na głównej przekątnej, 0 poza nią).
– macierz identycznościowa (1 na głównej przekątnej, 0 poza nią).
Przykład c.d. (plik: iris.pqs)
Interpretacja współczynników związanych z analizą
Każda składowa główna opisana jest poprzez:
Wartość własną
Wartość własna daje informacje o tym, jaka część całkowitej zmienności jest tłumaczona przez daną składową główną. Pierwsza składowa główna tłumaczy największą część wariancji, druga składowa tłumaczy największą część tej wariancji, która nie została wytłumaczona przez poprzednią składową, kolejna składowa tłumaczy największą część tej wariancji, która nie została wytłumaczona przez poprzednie składowe. W rezultacie każda kolejna składowa główna tłumaczy coraz mniejszą część wariancji, czyli kolejne wartości własne są coraz mniejsze.
Całkowita wariancja jest sumą wartości własnych, co pozwala, dla każdej składowej wyliczyć procent zmienności przez nią definiowany

W rezultacie dla kolejnych składowych można wyliczyć również, skumulowaną zmienność i skumulowany procent zmienności.
Wektor własny
Wektor własny odzwierciedla wpływ poszczególnych zmiennych pierwotnych na daną składową główną. Zawiera współczynniki kombinacji liniowej wyznaczającej składową. Przy czym znak tych współczynników wskazuje kierunek wpływu i jest przypadkowy co nie zmienia wartości niesionej informacji.
Ładunki czynnikowe
Ładunki czynnikowe, podobnie jak współczynniki zawarte w wektorze własnym, odzwierciedlają wpływ poszczególnych zmiennych na daną składową główną. Są to wartości obrazujące jaką część wariancji danej składowej stanowi zmienne pierwotne. Gdy analiza oparta jest na macierzy korelacji wartości te interpretujemy jako współczynniki korelacji pomiędzy zmiennymi pierwotnymi a daną składową główną.
Wkłady zmiennych
Bazują na współczynnikach determinacji pomiędzy zmiennymi pierwotnymi a daną składową główną. Wskazują jaki procent zmienności danej składowej głównej może być tłumaczony zmiennością poszczególnych zmiennych pierwotnych.
Zasoby zmienności wspólnej
Bazują na współczynnikach determinacji pomiędzy zmiennymi pierwotnymi a daną składową główną. Wskazują jaki procent zmienności danej zmiennej pierwotnej może być tłumaczony zmiennością pierwszych kilku składowych głównych. Na przykład: wynik dotyczący drugiej zmiennej zawarty w kolumnie dotyczącej czwartej składowej głównej mówi o tym, jaki procent zmienności drugiej zmiennej może być tłumaczony zmiennością pierwszych czterech składowych głównych.
Przykład c.d. (plik: iris.pqs)
Interpretacja graficzna
Wiele informacji, które niosą współczynniki zwracane w tabelach można przedstawić na jednym wykresie. Umiejętność czytania wykresów pozwala na szybką interpretację wielu aspektów przeprowadzonej analizy. Wykresy zbierają w jednym miejscu informację dotyczącą wzajemnych relacji pomiędzy składowymi, zmiennymi pierwotnymi i przypadkami. Dają całościowy obraz analizy składowych głównych, przez co są bardzo dobrym jej podsumowaniem.
Wykres ładunków czynnikowych
Wykres przedstawia wektory połączone z początkiem układu współrzędnych, które to reprezentują zmienne pierwotne. Wektory te są umieszczone na płaszczyźnie wyznaczonej przez dwie wybrane składowe główne.
{3}
\psline{->}(0,0)(2.5,1)
\rput(2.5,0.8){A}
\psline{->}(0,0)(2.7,1.3)
\rput(2.4,1.43){B}
\psline{->}(0,0)(1,1)
\rput(0.7,1){C}
\psline{->}(0,0)(-1.5,0.3)
\rput(-1.4,0.5){D}
\psline{->}(0,0)(-2,-2)
\rput(-2,-1.7){E}
\end{pspicture}](/lib/exe/fetch.php?media=wiki:latex:/imga791b18820caf03e86415963084a97c1.png "LaTeX")
- Współrzędne końca wektora to odpowiadające im ładunki czynnikowe zmiennych.
- Długość wektora reprezentuje zasób informacyjny zmiennej pierwotnej, jaki niosą składowe główne wyznaczające układ współrzędnych. Im dłuższy wektor, tym wkład zmiennej pierwotnej w budowę składowych większy. W przypadku analizy opartej na macierzy korelacji ładunki są korelacjami pomiędzy zmiennymi pierwotnymi a składowymi, wówczas punkty wpadają do koła jednostkowego. Dzieje się tak dlatego, że współczynnik korelacji nie może przekroczyć jedynki. W rezultacie, im dana zmienna pierwotna leży bliżej brzegu tego koła, tym lepsza jest jej reprezentacja przez przedstawione główne składowe.
- Znak współrzędnych końca wektora czyli znak ładunku czynnikowego - wskazuje na dodatnią lub ujemną korelację zmiennej pierwotnej i składowych głównych tworzących układ współrzędnych. Jeżeli rozpatrujemy łącznie obie osie (2 składowe), wówczas zmienne pierwotne mogą być kwalifikowane do jednej z czterech kategorii, zależnie od kombinacji znaków (
 ) ich ładunków czynnikowych.
) ich ładunków czynnikowych.
- Kąt między wektorami wskazuje na skorelowanie zmiennych pierwotnych:
 : im kąt pomiędzy wektorami reprezentującymi zmienne pierwotne jest mniejszy tym silniejsza jest dodatnia korelacja pomiędzy tymi zmiennymi.
: im kąt pomiędzy wektorami reprezentującymi zmienne pierwotne jest mniejszy tym silniejsza jest dodatnia korelacja pomiędzy tymi zmiennymi.
 - wektory te są prostopadłe, czyli zmienne pierwotne nie są skorelowane.
- wektory te są prostopadłe, czyli zmienne pierwotne nie są skorelowane.
 - im kąt pomiędzy wektorami reprezentującymi zmienne pierwotne jest większy, tym silniejsza jest ujemna korelacja pomiędzy tymi zmiennymi.
- im kąt pomiędzy wektorami reprezentującymi zmienne pierwotne jest większy, tym silniejsza jest ujemna korelacja pomiędzy tymi zmiennymi.
Biplot
Wykres przedstawia 2 serie danych umieszczone w układzie współrzędnych wyznaczonych przez 2 składowe główne. Serię pierwszą na wykresie stanowią dane z wykresu pierwszego (czyli wektory zmiennych pierwotnych) a serię drugą punkty przedstawiające poszczególne przypadki.

\psdot[dotsize=3pt](0.8,0)
\psdot[dotsize=3pt](1.1,0.2)
\psdot[dotsize=3pt](2,-1.6)
\psdot[dotsize=3pt](1.3,0)
\psdot[dotsize=3pt](-1.6,1.9)
\psdot[dotsize=3pt](-1.2,-1)
\psdot[dotsize=3pt](1.3,0.5)
\psdot[dotsize=3pt](1,0.6)
\psdot[dotsize=3pt](0.2,-1.6)
\psdot[dotsize=3pt](-0.6,0.2)
\psdot[dotsize=3pt](-0.8,-1)
\psdot[dotsize=3pt](1.9,0.7)
\psdot[dotsize=3pt](1.8,-1.2)
\psdot[dotsize=3pt](-1.8,-1)
\psdot[dotsize=3pt](1.4,0.8)
\psdot[dotsize=3pt](-0.6,-1.8)
\psdot[dotsize=3pt](1.1,0.3)
\psdot[dotsize=3pt](0.1,-1)
\psdot[dotsize=3pt](-1.7,-1)
\psdot[dotsize=3pt](1,-0.2)
\psdot[dotsize=3pt](-0.4,-1.3)
\psdot[dotsize=3pt](-1.1,-0.2)
\psdot[dotsize=3pt](-0.1,-0.3)
\psdot[dotsize=3pt](0.9,-0.9)
\psdot[dotsize=3pt](-0.1,0.5)
\psdot[dotsize=3pt](2,1.9)
\psdot[dotsize=3pt](-1.5,-1)
\psdot[dotsize=3pt](-1.5,1.1)
\psdot[dotsize=3pt](0.6,-0.6)
\psline{->}(0,0)(2.5,1)
\rput(2.5,0.8){A}
\psline{->}(0,0)(2.7,1.3)
\rput(2.4,1.43){B}
\psline{->}(0,0)(1,1)
\rput(0.7,1){C}
\psline{->}(0,0)(-1.5,0.3)
\rput(-1.4,0.5){D}
\psline{->}(0,0)(-2,-2)
\rput(-2,-1.7){E}
\end{pspicture}](/lib/exe/fetch.php?media=wiki:latex:/img2b39b527c98bf4a4b17471e1b7b9c745.png "LaTeX")
- Współrzędne punktów powinny być interpretowane jak wartości zestandaryzowane, tzn. współrzędne dodatnie wskazują na wartość wyższą od średniej wartości składowej głównej, ujemne na wartość niższą a im wyższa wartość bezwzględna tym dalej punkty znajdują się od średniej. Przy czym, jeśli na wykresie znajdują się obserwacje nietypowe - odstające, to mogą one zaburzać analizę i powinny być usunięte a analiza przeprowadzona ponownie.
- Odległości między punktami wskazują na podobieństwo przypadków - im bliżej (w znaczeniu odległości euklidesowej) zlokalizowane są względem siebie punkty, tym bardziej podobne informacje niosą porównywane przypadki.
- Rzuty prostopadłe punktów na wektory interpretujemy tak samo jak współrzędne punktów, czyli rzuty na osie z tym, że interpretacja dotyczy nie składowych głównych a zmiennych pierwotnych. Wartości umieszczone po stronie końca wektora są większe od średniej wartości zmiennej pierwotnej a wartości umieszczone na przedłużeniu wektora ale w kierunku przeciwnym są wartościami mniejszymi od średniej.
Przykład c.d. (plik: iris.pqs)
Kryteria redukcji wymiarów
Nie istnieje jedno uniwersalne kryterium wyboru ilości składowych głównych. Dobrze jest wiec, aby przy wyborze kierować się kilkoma metodami. Procent wyjaśnionej wariancji
Liczba składowych głównych, jaką badacz powinien przyjąć zależy od tego, w jaki stopniu reprezentują one zmienne pierwotne, czyli zawartej w nich wariancji zmiennych pierwotnych. Wszystkie składowe główne niosą 100\% wariancji zmiennych pierwotnych. Jeśli suma wariancji dla kilku pierwszych składowych stanowi znaczną część całkowitej wariancji zmiennych pierwotnych, wówczas te składowe główne mogą w zadowalającym stopniu zastąpić zmienne pierwotne. Przyjmuje się, że wariancja ta powinna zostać odzwierciedlona w składowych głównych w ponad 80 procentach.
Kryterium Kaisera
Kryterium Kaisera mówi o tym, że składowe główne, które chcemy pozostawić do interpretacji powinny mieć przynajmniej taką samą wariancję jak dowolna wystandaryzowana zmienna pierwotna. W związku z tym, że wariancja każdej wystandaryzowanej zmiennej pierwotnej wynosi 1, to według kryterium Kaisera ważne są tylko składowe główne, których wartość własna przekracza lub jest bliska wartości 1.
Wykres osypiska
Na wykresie tym przedstawione jest tempo spadku wartości własnych, czyli procentu wyjaśnionej wariancji.

\psline{-}(1,3.4)(2,1.9)
\psdot[dotsize=3pt](2,1.9)
\psline{-}(2,1.9)(3,1.7)
\psdot[dotsize=3pt](3,1.7)
\psline{-}(3,1.7)(4,0.5)
\psdot[dotsize=3pt](4,0.5)
\psline{-}(4,0.5)(5,0.4)
\psdot[dotsize=3pt](5,0.4)
\psline{-}(5,0.4)(6,0.3)
\psdot[dotsize=3pt](6,0.3)
\psline{-}(6,0.3)(7,0.22)
\psdot[dotsize=3pt](7,0.22)
\psline{-}(7,0.22)(8,0.15)
\psdot[dotsize=3pt](8,0.15)
\psline{-}(8,0.15)(9,0.11)
\psdot[dotsize=3pt](9,0.11)
\pscircle(4,0.5){0.15}
\psline[linestyle=dotted]{->}(6,2)(4.1,0.7)
\end{pspicture}](/lib/exe/fetch.php?media=wiki:latex:/img18bff880d255fad7296e139e6e4e08a9.png "LaTeX")
Moment na wykresie, w którym proces ten stabilizuje się i linia malejąca przechodzi w poziomą to tzw. koniec osypiska (koniec osypywania się informacji o zmiennych pierwotnych, jaką niosą składowe główne). Składowe znajdujące się na prawo od punktu kończącego osypisko reprezentują znikomą wariancję i przedstawiają w większości losowy szum.
Przykład c.d. (plik: iris.pqs)
Wyznaczenie składowych głównych
Gdy zdecydujemy ilu składowych głównych będziemy potrzebować, możemy przystąpić do ich wygenerowania. W przypadku składowych głównych powstałych w oparciu o macierz korelacji składowe główne są wyliczane jako kombinacja liniowa wystandaryzowanych zmiennych pierwotnych. Jeśli natomiast składowe główne powstały w oparciu o macierz kowariancji, wówczas są wyliczane jako kombinacja liniowa wycentrowanych względem średniej zmiennych pierwotnych.
Otrzymane w ten sposób składowe główne stanowią nowe zmienne o pewnych zaletach. Przede wszystkim zmienne te nie są współliniowe. Zwykle jest ich mniej niż zmiennych pierwotnych, czasem znacznie mniej, a niosą one tyle samo lub nieznacznie mniej informacji niż zmienne pierwotne. Są więc zmiennymi, które z powodzeniem mogą być wykorzystane w większości analiz wielowymiarowych.
Przykład c.d. (plik: iris.pqs)
Zasadność stosowania Analizy składowych głównych
Jeśli zmienne nie są skorelowane (współczynnik korelacji Pearsona jest bliski 0), to wówczas przeprowadzanie analizy składowych głównych nie ma sensu. W takiej sytuacji bowiem każda zmienna stanowi już odrębną składową.
Test Bartletta
Test ten wykorzystywany jest do weryfikacji hipotezy o tym, że współczynniki korelacji pomiędzy zmiennymi są zerowe (czyli macierz korelacji jest macierzą jednostkową).
Hipotezy:

gdzie:
– macierz wariancji lub kowariancji zmiennych pierwotnych ,
– macierz jednostkowa (1 na głównej przekątnej, 0 poza nią).
Statystyka testowa ma postać:

gdzie:
– liczba zmiennych pierwotnych,
 – liczność (liczba przypadków),
– liczność (liczba przypadków),
 – -ta wartość własna.
– -ta wartość własna.
Statystyka ta ma asymptotycznie (dla dużych liczności oczekiwanych) rozkład chi-kwadrat z  stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności  :
:

Współczynnik Kaisera-Mayera-Olkina
Współczynnik ten wykorzystywany jest do sprawdzania stopnia skorelowania zmiennych pierwotnych, czyli siły dowodów świadczących na rzecz sensowności przeprowadzania analizy składowych głównych.

 – współczynnik korelacji pomiędzy -tą a
– współczynnik korelacji pomiędzy -tą a  -tą zmienną,
-tą zmienną,
 – współczynnik korelacji cząstkowej pomiędzy -tą a -tą zmienną.
– współczynnik korelacji cząstkowej pomiędzy -tą a -tą zmienną.
Wartość współczynnika Kaisera należy do przedziału  , gdzie wartości niskie świadczą o braku podstaw do przeprowadzania analizy składowych głównych, a wartości wysokie są przesłanką do przeprowadzania tej analizy.
, gdzie wartości niskie świadczą o braku podstaw do przeprowadzania analizy składowych głównych, a wartości wysokie są przesłanką do przeprowadzania tej analizy.
Ten klasyczny zestaw danych pierwotnie ukazał się w pracy R.A. Fishera 19361), gdzie przedstawiona została analiza dyskryminacyjna. Plik zawiera pomiary (w centymetrach) długości i szerokości płatków i działek kielicha dla 3 odmian kwiatu irysa. Poddane badaniu gatunki to setosa, versicolor i virginica. Interesujące jest określenie sposobu rozróżniania tych gatunków na bazie uzyskanych pomiarów.

Rycina pochodzi z pracy Lee i innych (2006r): „Application of a noisy data classification technique to determine the occurrence of flashover in compartment fires”
Analiza składowych głównych pozwoli na wskazanie tych pomiarów (długości i szerokości płatków i działek kielicha), które dają badaczowi najwięcej informacji o obserwowanych kwiatach.
Pierwszym etapem wykonywanym jeszcze przed przystąpieniem do wyznaczania i analizowania składowych, jest sprawdzenie celowości przeprowadzenia tej analizy. Zaczynamy więc od wyznaczenia macierzy korelacji zmiennych oraz przeanalizowania uzyskanych korelacji przy wykorzystaniu testu Bartletta i współczynnika KMO.
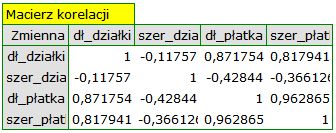
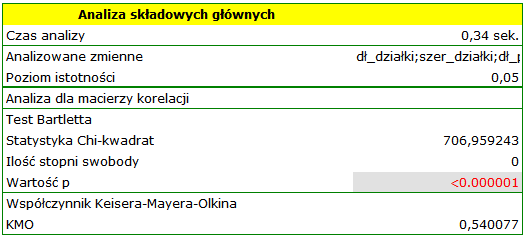
Wartość statystyki Bartletta wskazuje na prawdziwość hipotezy mówiącej o istotnej różnicy pomiędzy uzyskaną macierzą korelacji a macierzą jednostkową, czyli znacznym skorelowaniu zmiennych. Uzyskany współczynnik KMO jest natomiast przeciętny i wynosi 0.54. Wskazania do przeprowadzenia analizy składowych głównych uznajemy za wystarczające.
Pierwszym wynikiem tej analizy, na który należy zwrócić szczególną uwagę są wartości własne:
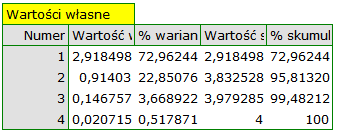
Uzyskane wartości własne wskazują, że dwie lub nawet jedna składowa główna w dobry sposób opiszą nasze dane. Wartość własna dla pierwszej składowej wynosi 2.92 a procent wyjaśnionej przez nią wariancji to 72.96. Druga składowa wyjaśnia już znacznie mniej wariancji, bo 22.85% a jej wartość własna to 0.91. Według kryterium Kaisera wystarczająca w interpretacji jest tylko jedna składowa główna, gdyż tylko dla pierwszej składowej wartość własna jest większa niż 1. Patrząc jednak na wykres osypiska można wysnuć wniosek, że linia spadkowa przechodzi w poziomą dopiero od 3 składowej głównej.
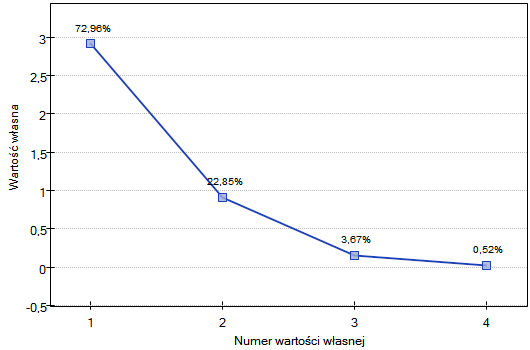
Zgodnie z tym wskazaniem dwie pierwsze składowe wnoszą istotną informację. Łącznie dwie pierwsze składowe wyjaśniają sporo bo aż 95.81% wariancji (patrz kolumna % skumulowany).
Zasoby zmienności wspólnej dla pierwszej składowej są wysokie dla wszystkich zmiennych pierwotnych za wyjątkiem zmiennej szerokość działki, dla której wynoszą 21,17%. Oznacza to, że gdybyśmy pozostali przy interpretacji tylko pierwszej składowej, to zmienna szerokość działki zostałaby odzwierciedlona w niewielkiej części.
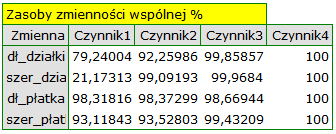
Dla dwóch pierwszych składowych zasoby zmienności wspólnej są już na podobnym, bardzo wysokim poziomie i dla każdej z analizowanych zmiennych przekraczają 90%, czyli wariancja każdej zmiennej jest reprezentowana przy użyciu tych składowych w ponad 90%.
Zebrawszy całą tą wiedzę zdecydowano się na wyodrębnienie i interpretację 2 składowych.
By przyjrzeć się dokładniej powiązaniu składowych głównych i zmiennych pierwotnych czyli długości i szerokości płatków i działek kielicha interpretujemy: wektory własne, ładunki czynnikowe oraz wkłady zmiennych.
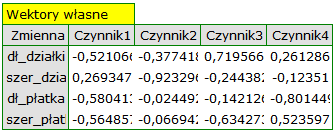
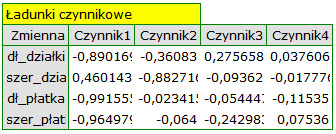
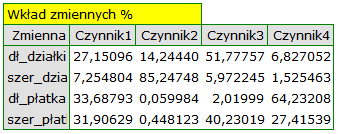
Poszczególne zmienne pierwotne w różny sposób oddziałują na pierwszą składową główną. Ułóżmy je kolejno według wielkości tego wpływu:
- Długość płatka jest ujemnie skorelowana z pierwszą składową, a zatem czym dłuższy płatek, tym niższe wartości tej składowej. Wektor własny dla długości płatka jest największy w tej składowej i wynosi -0.58. Jego ładunek czynnikowy informuje, że korelacja pomiędzy pierwszą składową główną a długością płatka jest bardzo wysoka i wynosi -0.99 co daje 33.69\% wkładu w pierwszą składową;
- Szerokość płatka ma nieco tylko mniejszy wpływ na pierwszą składową i jest z nią również ujemnie skorelowana;
- Długość działki interpretujemy podobnie jak poprzednie dwie zmienne ale jej wpływ na pierwszą składową jest mniejszy;
- Szerokość działki jest najsłabiej skorelowana z pierwszą składową i znak tej korelacji jest dodatni.
Druga składowa reprezentuje głównie zmienną pierwotną: szerokość działki; pozostałe zmienne pierwotne są w niej odzwierciedlone w niewielkim stopniu. Wektor własny, ładunek czynnikowy oraz wkład zmiennej szerokość działki jest w składowej drugiej najwyższy.
Każda składowa główna wyznacza homogeniczną grupę zmiennych pierwotnych. Pierwszą składową nazwiemy „rozmiar płatka”, gdyż najbardziej znaczącymi dla niej zmiennymi są te zmienne, które niosą informacje o płatku, choć trzeba zaznaczyć, że długość działki również wpływa znacznie na wartość tej składowej. W interpretacji pamiętamy, że czym większe są wartości tej składowej , tym mniejsze są płatki.
Drugą składową nazwiemy natomiast „szerokość działki” gdyż tylko szerokość działki w większym stopniu odzwierciedlona jest w drugiej składowej. Przy czym, im większe są wartości tej składowej, tym węższa jest działka.
Ostatecznie składowe wygenerujemy wybierając w oknie analizy opcję: Dołącz składowe główne. Fragment uzyskanego wyniku przedstawiamy poniżej:
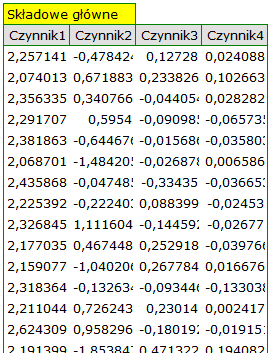
Aby dwie pierwsze składowe można było wykorzystać zamiast wcześniejszych czerech zmiennych pierwotnych, ostatecznie przeklejamy je do arkusza danych. Dalsze planowane przez siebie statystyki badacz może teraz przeprowadzić na dwóch nowych, nieskorelowanych zmiennych.
- [Analiza wykresów dwóch pierwszych składowych]
Analiza wykresów nie dość, że doprowadzi badacza do tych samych wniosków, co analiza tabel, to da możliwość wnikliwszej oceny uzyskanych wyników. - [Wykres ładunków czynnikowych]
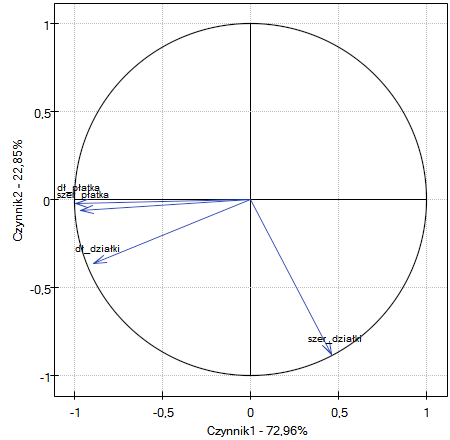
Wykres przedstawia dwie pierwsze składowe główne, które reprezentują 72.96% wariancji i 22.85% wariancji co daje łącznie 95.81% wariancji zmiennych pierwotnych
Wektory reprezentujące zmienne pierwotne nieomalże sięgają brzegów koła jednostkowego (koła o promieniu 1), a zatem wszystkie one są bardzo dobrze reprezentowane przez dwie pierwsze składowe główne tworzące układ współrzędnych.
Kąt pomiędzy wektorami obrazującymi długość płatka, szerokość płatka i długość działki jest niewielki, co oznacza duże skorelowanie tych zmiennych. Skorelowanie zaś tych zmiennych ze składowymi tworzącymi układ jest negatywne - wektory znajdują się w III ćwiartce układu. Przy czym wyższe wartości współrzędnych końca wektora obserwowane są dla składowej pierwszej niż drugiej. Takie ułożenie wektorów świadczy o tym, że tworzą one grupę jednorodną, która jest reprezentowana głównie przez składową pierwszą.
Zupełnie inny kierunek wskazuje wektor dotyczący szerokości działki, który jest w niewielkim stopniu skorelowany z pozostałymi zmiennymi pierwotnymi o czym świadczy kąt nachylenia do pozostałych zmiennych pierwotnych, który jest bliski kątowi prostemu. Skorelowanie tego wektora z pierwszą składową jest pozytywne i niezbyt wysokie (niska wartość pierwszej współrzędnej końca wektora) a z drugą składową negatywne i wysokie (wysoka wartość drugiej współrzędnej końca wektora). Wnioskujemy z tego, że szerokość działki jako jedyna zmienna pierwotna reprezentowana jest dobrze przez drugą składową.
- [Biplot]
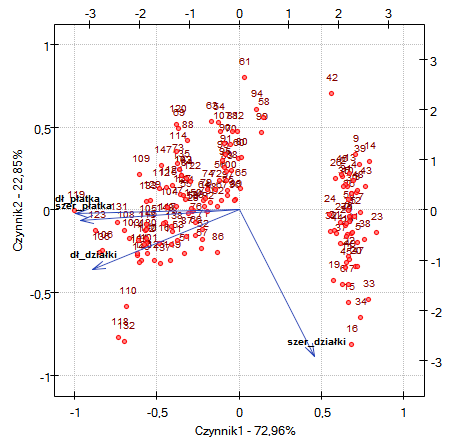
Biplot przedstawia dwie serie danych rozpięte na dwóch pierwszych składowych. Jedną serią są wektory zmiennych pierwotnych, które przedstawione były na poprzednim wykresie, a drugą serią są punkty niosące informacje o poszczególnych kwiatach. Przy czym wartości drugiej serii odczytujemy na górnej osi  i prawej osi
i prawej osi  . Sposób interpretacji wektorów, czyli pierwszej serii omówiliśmy przy poprzednim wykresie. By zrozumieć interpretację punktów skupimy się na kwiatach o numerze 33 i 34 oraz o numerze 109.
. Sposób interpretacji wektorów, czyli pierwszej serii omówiliśmy przy poprzednim wykresie. By zrozumieć interpretację punktów skupimy się na kwiatach o numerze 33 i 34 oraz o numerze 109.
Kwiaty o numerze 33 i 34 są do siebie podobne - odległość punktu 33 i 34 jest niewieka. Oba punkty mają sporo większą niż przeciętna wartość pierwszej i sporo mniejszą niż przeciętna wartość drugiej składowej. Wartość przeciętna, a zatem średnia arytmetyczna obu składowych wynosi 0, więc jest to środek układu współrzędnych. Pamiętając, że pierwsza składowa to głównie rozmiar płatków a druga to szerokość działki możemy powiedzieć, że kwiaty 33 i 34 mają niewielkie płatki i dużą szerokość działki. Natomiast kwiat 109 reprezentuje punkt znacznie oddalony od pozostałych dwóch punktów. Jest to kwiat o ujemnej pierwszej składowej i dodatniej lecz nie wysokiej drugiej składowej. Zatem jest to kwiat o stosunkowo dużych płatkach i szerokości działki nieco tylko mniejszej niż przeciętna.
Podobne informacje uzyskamy rzutując punkty na linie przedłużające wektory zmiennych pierwotnych. Przykładowo kwiat 33 wykazuje się dużą szerokością działki (wysokie i dodatnie wartości rzutowania na zmienną pierwotną szerokość działki) ale niskimi wartościami pozostałych zmiennych pierwotnych (ujemne wartości rzutowania na przedłużenie wektorów obrazujących pozostałe zmienne pierwotne).
1)
Fisher R.A. (1936), The use of multiple measurements in taxonomic problems. Annals of Eugenics 7 (2): 179–188
statpqpl/redpl/pcapl.txt · ostatnio zmienione: 2015/12/28 12:26 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
