Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:diagnpl:rocpl
The ROC Curve
The diagnostic test is used for differentiating objects with a given feature (marked as (+), e.g. ill people) from objects without the feature (marked as (–), e.g. healthy people). For the diagnostic test to be considered valuable, it should yield a relatively small number of wrong classifications. If the test is based on a dichotomous variable then the proper tool for the evaluation of the quality of the test is the analysis of a  contingency table of true positive (TP), true negative (TN), false positive (FP), and false negative (FN) values. Most frequently, though, diagnostic tests are based on continuous variables or ordered categorical variables. In such a situation the proper means of evaluating the capability of the test for differentiating (+) and (–) are ROC (Receiver Operating Characteristic) curves.
contingency table of true positive (TP), true negative (TN), false positive (FP), and false negative (FN) values. Most frequently, though, diagnostic tests are based on continuous variables or ordered categorical variables. In such a situation the proper means of evaluating the capability of the test for differentiating (+) and (–) are ROC (Receiver Operating Characteristic) curves.
It is frequently observed that the greater the value of the diagnostic variable, the greater the odds of occurrence of the studied phenomenon, or the other way round: the smaller the value of the diagnostic variable, the smaller the odds of occurrence of the studied phenomenon. Then, with the use of ROC curves, the choice of the optimum cut-off is made, i.e. the choice of a certain value of the diagnostic variable which best separates the studied statistical population into two groups: (+) in which the given phenomenon occurs and (–) in which the given phenomenon does not occur.
When, on the basis of the studies of the same objects, two or more ROC curves are constructed, one can compare the curves with regard to the quality of classification.
Let us assume that we have at our disposal a sample of  elements, in which each object has one of the
elements, in which each object has one of the  values of the diagnostic variable. Each of the received values of the diagnostic variable
values of the diagnostic variable. Each of the received values of the diagnostic variable  becomes the cut-off
becomes the cut-off  .
.
If the diagnostic variable is:
- stimulant (the growth of its value makes the odds of occurrence of the studied phenomenon greater), then values greater than or equal to the cut-off (
 ) are classified in group (+);
) are classified in group (+); - destimulant (the growth of its value makes the odds of occurrence of the studied phenomenon smaller), then values smaller than or equal to the cut-off () are classified in group (+);
For each of the cut-offs we define true positive (TP), true negative (TN), false positive (FP), and false negative (FN) values.


On the basis of those values each cut-off can be further described by means of sensitivity and specificity, positive predictive values(PPV), negative predictive values (NPV), positive result likelihood ratio (LR+), negative result likelihood ratio (LR-), and accuracy (Acc).
Note
The PQStat program computes the prevalence coefficient on the basis of the sample. The computed prevalence coefficient will reflect the occurrence of the studied phenomenon (illness) in the population in the case of screening of a large sample representing the population. If only people with suspected illness are directed to medical examinations, then the computed prevalence coefficient for them can be much higher than the prevalence coefficient for the population.
Because both the positive and negative predictive value depend on the prevalence coefficient, when the coefficient for the population is known a priori, we can use it to compute, for each cut-off , corrected predictive values according to Bayes's formulas:


where:
 - the prevalence coefficient put in by the user, the so-called pre-test probability of disease
- the prevalence coefficient put in by the user, the so-called pre-test probability of disease

The ROC curve is created on the basis of the calculated values of sensitivity and specificity. On the abscissa axis the  =1-specificity is placed, and on the ordinate axis
=1-specificity is placed, and on the ordinate axis  =sensitivity. The points obtained in that manner are linked. The constructed curve, especially the area under the curve, presents the classification quality of the analyzed diagnostic variable. When the ROC curve coincides with the diagonal
=sensitivity. The points obtained in that manner are linked. The constructed curve, especially the area under the curve, presents the classification quality of the analyzed diagnostic variable. When the ROC curve coincides with the diagonal  , then the decision made on the basis of the diagnostic variable is as good as the random distribution of studied objects into group (+) and group (–).
, then the decision made on the basis of the diagnostic variable is as good as the random distribution of studied objects into group (+) and group (–).
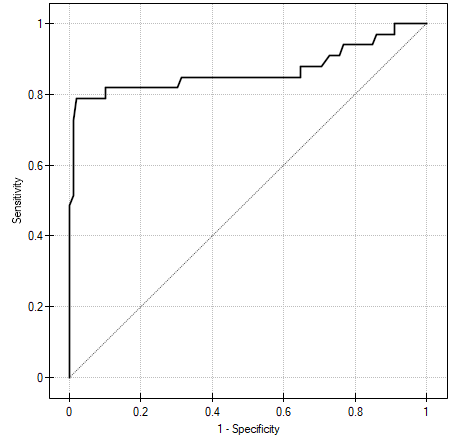
AUC (area under curve) – the size of the area under the ROC curve falls within  . The greater the field the more exact the classification of the objects in group (+) and group (–) on the basis of the analyzed diagnostic variable. Therefore, that diagnostic variable can be even more useful as a classifier. The area
. The greater the field the more exact the classification of the objects in group (+) and group (–) on the basis of the analyzed diagnostic variable. Therefore, that diagnostic variable can be even more useful as a classifier. The area  , error
, error  and confidence interval for AUC are calculated on the basis of:
and confidence interval for AUC are calculated on the basis of:
- nonparametric Hanley-McNeil method (Hanley J.A. i McNeil M.D. 19823)),
- Hanley-McNeil method which presumes double negative exponential distribution (Hanley J.A. i McNeil M.D. 19824)) - computed only when groups (+) and (–) are equinumerous.
For the classification to be better than random distribution of objects into to classes, the area under the ROC curve should be significantly larger than the area under the line , i.e. than 0.5.
Hypotheses:

The test statistics has the form presented below:

where:
 ,
,
 – size of the sample (+) in which the given phenomenon occurs,
– size of the sample (+) in which the given phenomenon occurs,
 – size of the sample (–), in which the given phenomenon does not occur.
– size of the sample (–), in which the given phenomenon does not occur.
The  statistic asymptotically (for large sample sizes) has the normal distribution.
statistic asymptotically (for large sample sizes) has the normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

In addition, when we assume that the diagnostic parameter forms a high field (AUC), we can select the optimal cut-off point.
EXAMPLE (acteriemia.pqs file)
1)
DeLong E.R., DeLong D.M., Clarke-Pearson D.L., (1988), Comparing the areas under two or more correlated receiver operating curves: A nonparametric approach. Biometrics 44:837-845
2)
Hanley J.A. i Hajian-Tilaki K.O. (1997), Sampling variability of nonparametric estimates of the areas under receiver operating characteristic curves: an update. Academic radiology 4(1):49-58
en/statpqpl/diagnpl/rocpl.txt · ostatnio zmienione: 2022/02/15 16:16 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
