Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:przestrzenpl:losdotpl:nnipl
Nearest Neighbor Analysis
In the Nearest Neighbor Analysis the boundaries of the area in which the analysed points are enclosed have the crucial influence on the result. The example below illustrates regularly distributed points and their clustered distribution when bounded by a large rectangle.
(5,2.5)
\psline[linestyle=dashed](5,0)(8,0)
\psline[linestyle=dashed](5,2.5)(8,2.5)
\psline[linestyle=dashed](8,0)(8,2.5)
\psline{-}(5.7,0.5)(5.7,2)
\psline{-}(5.7,0.5)(7.3,0.5)
\psline{-}(5.7,2)(7.3,2)
\psline{-}(7.3,0.5)(7.3,2)
\rput(6.2,1){$\circ$}
\rput(6.8,1.5){$\circ$}
\rput(6.2,1.5){$\circ$}
\rput(6.8,1){$\circ$}
\end{pspicture}](/lib/exe/fetch.php?media=wiki:latex:/imgaeab4b2d3483753a4db8950ca4951980.png "LaTeX")
Depending on the needs, the bounding can be defined with the help of: a convex hull, the smallest rectangle, a rectangle from layer bounding, or the smallest circle. The studied area can also be defined only with the use of the size of its area.
The distance between the points is measured with the Euclidean metric.
The first stage of the nearest neighbor analysis is calculating the distance among all points. Next, for each point we search for the nearest point, i.e. for the nearest neighbor ( ).
).
Note
The distances between all points are defined by a spatial weight matrix. In Moran's analysis window we can choose matrix generated previously by using menu Spatial analysis → Tools → Spatial weights matrix or indicate the neighbor matrix according to contiguity – Queen, row standardized, that is proposed by the program.
The basic statistics for the analysis of the nearest neighbors are:
 – the distance of each point from its nearest neighbor,
– the distance of each point from its nearest neighbor, – the mean nearest neighbor distance:
– the mean nearest neighbor distance:

 – standard deviation of the nearest neighbors distance,
– standard deviation of the nearest neighbors distance, – mean random nearest neighbor distance:
– mean random nearest neighbor distance:

Nearest Neighbor Index
Nearest Neighbor Index ( NNI) is based on a method described by botanists: Clark and Evans (1954) 1).  compares distances observed between the nearest points, and distances which would appear for a random distribution of points.
compares distances observed between the nearest points, and distances which would appear for a random distribution of points.

When the compared distances are the same then  . When the observed distances between the nearest points are smaller than expected then the points are nearer to one another than in a random distribution, and
. When the observed distances between the nearest points are smaller than expected then the points are nearer to one another than in a random distribution, and  . In such a case, clusters occur. When the situation is reverse, then
. In such a case, clusters occur. When the situation is reverse, then  , which points to the occurrence of the effect of uniform distribution, i.e. points are distributed more regularly than in a case of random distribution.
, which points to the occurrence of the effect of uniform distribution, i.e. points are distributed more regularly than in a case of random distribution.
Significance of the Nearest Neighbor Index
The test for checking the significance of the Nearest Neighbor Index serves the purpose of verifying the hypothesis that the distances observed between the nearest points are the same as the expected distances which would appear in a random distribution of points.
Hypotheses:

The test statistic has the form presented below:

where:

Statistics  asymptotically (for a large sample size) has the normal distribution.
asymptotically (for a large sample size) has the normal distribution.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

Analysis of Subsequent Nearest Neighbors
To analyse subsequent nearest neighbors one takes into account the distance to the second nearest neighbor, the third nearest neighbor, and so on, to the  -order nearest neighbor. For the neighborhood of each order (from the nearest neighbor to the -order neighbor) subsequent Nearest Neighbor Indexes
-order nearest neighbor. For the neighborhood of each order (from the nearest neighbor to the -order neighbor) subsequent Nearest Neighbor Indexes  are calculated:
are calculated:

where:
 – mean distance from neighbors of -order,
– mean distance from neighbors of -order,
 – mean random distance from neighbors of -order.
– mean random distance from neighbors of -order.
The results of the point density analysis conducted for subsequent neighbors can be presented on a graph so as to illustrate the placement of in reference to the line which shows the random point structure and so as to check if a growing or falling trend has been achieved for the indexes.
Edge Effect
Objects placed near the bounding show a tendency to be further away from their nearest neighbors than other objects within the analysed area. The reason for it is the simple fact that the nearest neighbors of the objects near the border can be objects outside the studied area. In such a situation we can conduct an analysis with an adjustment for the edge effect.
In such a case the distance of a point from its nearest neighbor () is calculated as the minimum distance of the point from its neighbors and from the boundary. Thus, if the distance of the point from the boundary will be smaller than the distance from its neighbors, then the distance from the boundary is considered to be . However, such a calculation of the nearest neighbor requires an assumption that there will always be a neighboring point on the border.
The window with settings for Nearest Neighbor Analysis is accessed via the menu Spacial analysis → Spatial Statistics → Nearest Neighbor Analysis.
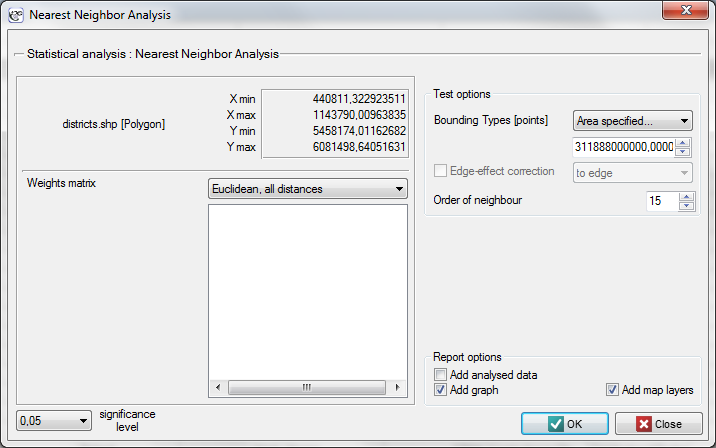
EXAMPLE (directory: districts, SHP files: districts)
The admistrative division of Poland into powiats should, by definition, be uniform. With the use of NNI we will check if that is the case.
The districts map contains information about locations of polygons (Polish powiats).
The nearest neighbor analysis will be based on centroids representing powiats. We can draw them (add the centroid layer to the map of powiats) with the use of the Map manager.
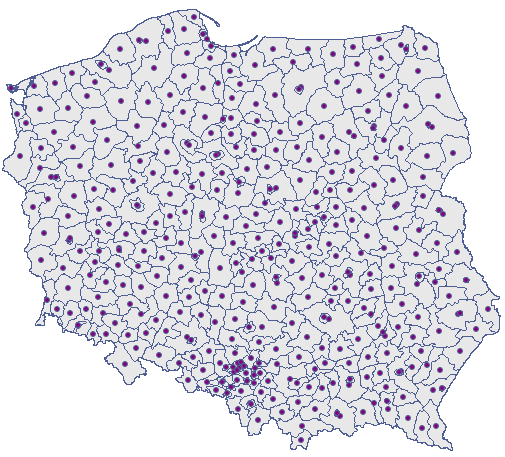
The nearest neighbor analysis will be made with the use of information about the size of the area of Poland – it is  . Apart from the nearest neighbor index we will also calculate the indices of subsequent neighbors, up to 15.
. Apart from the nearest neighbor index we will also calculate the indices of subsequent neighbors, up to 15.

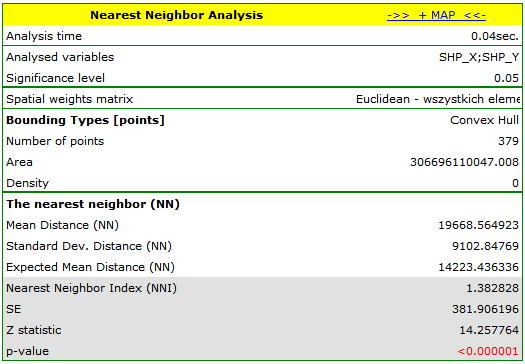
After entering the size of the area in the analysis window, a nearest neighbor index amounting to 1.37127 was received. Its statistical significance was ( ), greater than value 1. The mean distance between the nearest neighboring centroids is
), greater than value 1. The mean distance between the nearest neighboring centroids is  and the standard deviation is
and the standard deviation is  . We will receive a very similar result when we return to the analysis (the button
. We will receive a very similar result when we return to the analysis (the button  ) and choose the convex hull as the bounding (
) and choose the convex hull as the bounding ( , ).
, ).
We add the boundaries defined by the convex hull by pressing the button  and choosing the layer of bounding.
and choosing the layer of bounding.
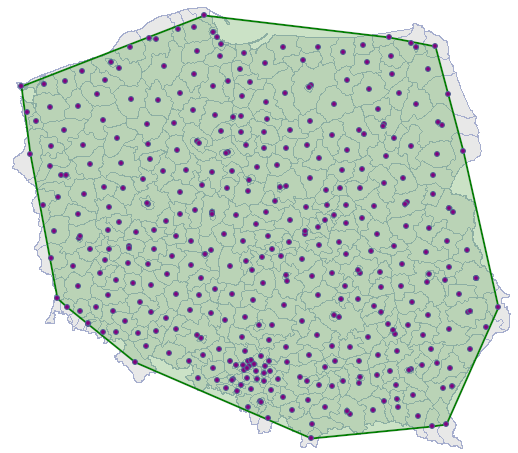
The correction of the effect of a boudary defined in this way lowers the value of to 1.340503 but leaves the general tendency of the subsequent nearest neighbor indices unchanged.
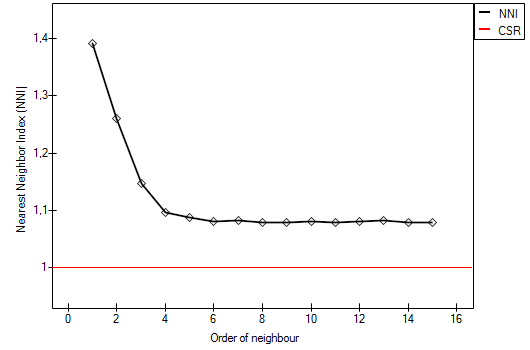
In each of the analysis described above the subsequent neighbor indices are greater than 1 and, although they initially approximate 1, from order 5 they stabilize at the level of about 1.1. The result, then, confirms the uniform distribution of Polish powiats.
EXAMPLE (directory: poplar, SHP files: T-poplar, S-poplar)
Competition among species has an influence on the changes in the distribution of particular species of plants and on their density. Competition within a species is usually stronger than that among different species as members of the same species have almost identical demands and compete for the same resources. The intensity of competition within a species increases with the growth of the population. To check the influence of the competition on a certain species of balsamic poplar, a wooded area not regulated by man was studied. Locations of young trees and of old ones were studied.
- Mapa
T-poplarcontains fictitious information about the locations of 121 points (old balsamic poplars) in a rectangular wooded area. - Mapa
S-poplarcontains fictitious information about the locations of 326 points (young balsamic poplars) in a rectangular wooded area.
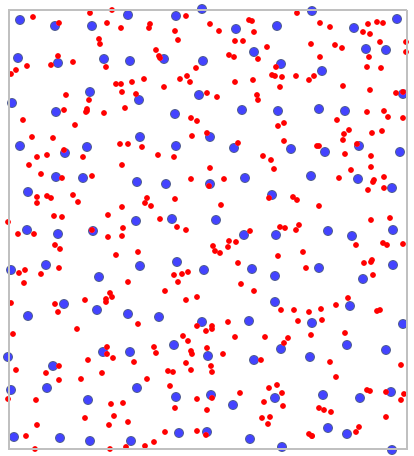
On the map young poplars were marked in red and old poplars were marked in blue.
On the basis of the nearest neighbor indices, the structure of poplar density was compared in the area defined by a rectangle of layer bounding.
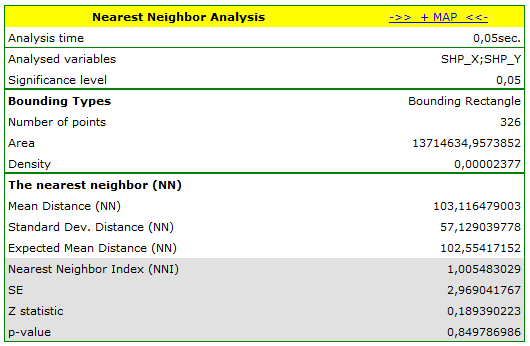
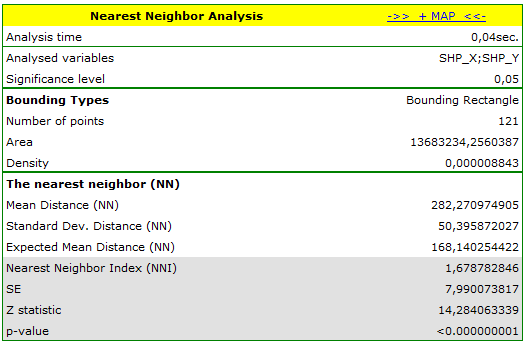
Young poplars have greater density than old ones. Their mean nearest neighbor distance is  whereas for old poplars the value is
whereas for old poplars the value is  .
Due to competition in the development of the structure of forest stand the spatial pattern for old trees is more regular (
.
Due to competition in the development of the structure of forest stand the spatial pattern for old trees is more regular ( , ) than the one for young poplars (
, ) than the one for young poplars ( ,
,  ).
).
1)
Clark P.J., Evans F.C. (1954), Distance to nearest neighbour as a measure of spatial relationships in populations. Ecology 35, 445-453
en/przestrzenpl/losdotpl/nnipl.txt · ostatnio zmienione: 2022/02/16 13:45 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
