Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
en:statpqpl:wielowympl:logistpl:przykl
Examples for logistic regression
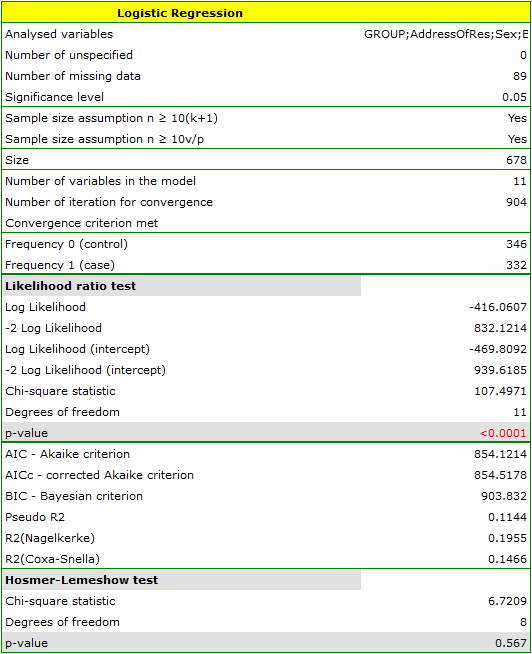
Studies have been conducted for the purpose of identifying the risk factors for a certain rare congenital anomaly in children. 395 mothers of children with that anomaly and 375 of healthy children have participated in that study. The gathered data are: address of residence, child's sex, child's weight at birth, mother's age, number of pregnancy, previous spontaneous abortions, respiratory tract infections, smoking, mother's education.
We construct a logistic regression model to check which variables may have a significant influence on the occurrence of the anomaly. The dependent variable is the column GROUP, the distinguished values in that variable as  are the
are the cases, that are mothers of children with anomaly. The following  variables are independent variables:
variables are independent variables:
AddressOfRes (2=city/1=village),
Sex (1=male/0=female),
BirthWeight (in kilograms, with an accuracy of 0.5 kg),
MAge (in years),
PregNo (which pregnancy is the child from),
SponAbort (1=yes/0=no),
RespTInf (1=yes/0=no),
Smoking (1=yes/0=no),
MEdu (1=primary or lower/2=vocational/3=secondary/4=tertiary).
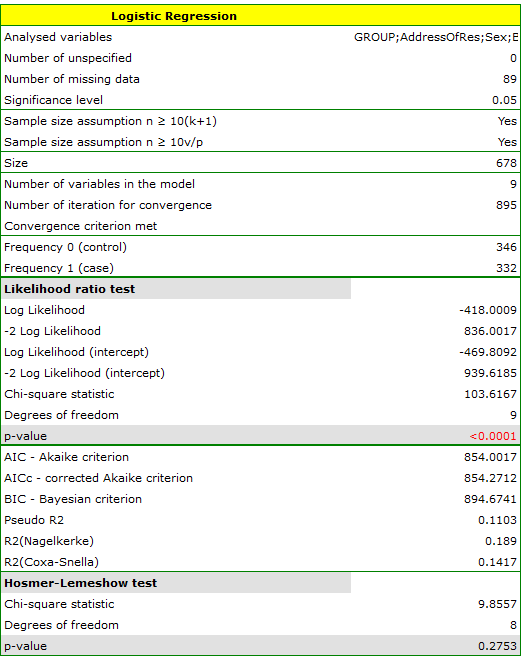
The quality of model goodness of fit is not high ( ,
,  i
i  ). At the same time the model is statistically significant (value
). At the same time the model is statistically significant (value  of the Likelihood Ratio test), which means that a part of the independent variables in the model is statistically significant. The result of the Hosmer-Lemeshow test points to a lack of significance (
of the Likelihood Ratio test), which means that a part of the independent variables in the model is statistically significant. The result of the Hosmer-Lemeshow test points to a lack of significance ( ). However, in the case of the Hosmer-Lemeshow test we ought to remember that a lack of significance is desired as it indicates a similarity of the observed sizes and of predicted probability.
). However, in the case of the Hosmer-Lemeshow test we ought to remember that a lack of significance is desired as it indicates a similarity of the observed sizes and of predicted probability.
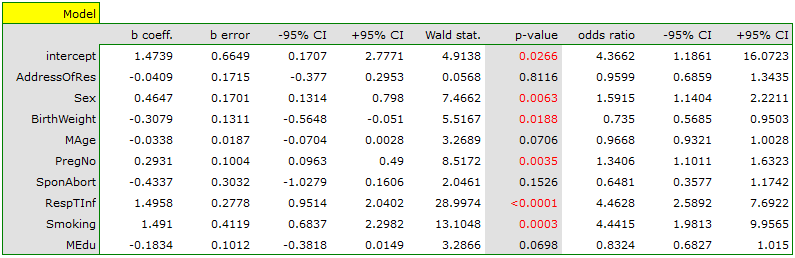
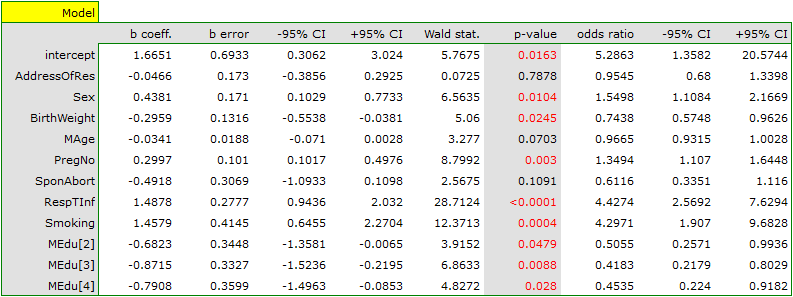
An interpretation of particular variables in the model starts from checking their significance. In this case the variables which are significantly related to the occurrence of the anomaly are:
Sex:  ,
,
BirthWeight:  ,
,
PregNo:  ,
,
RespTInf: ,
Smoking:  .
.
The studied congenital anomaly is a rare anomaly but the odds of its occurrence depend on the variables listed above in the manner described by the odds ratio:
- variable Sex:
![$OR[95%CI]=1.60[1.14;2.22]$](/lib/exe/fetch.php?media=wiki:latex:/img556edd84df29ad873b3475516b07df53.png "LaTeX") \textendash the odds of the occurrence of the anomaly in a boy is
\textendash the odds of the occurrence of the anomaly in a boy is  times greater than in a girl;
times greater than in a girl; - variable BirthWeight:
![$OR[95%CI]=0.74[0.57;0.95]$](/lib/exe/fetch.php?media=wiki:latex:/imgacc7a9f93e80a79bceacfa24fbda991d.png "LaTeX") \textendash the higher the birth weight the smaller the odds of the occurrence of the anomaly in a child;
\textendash the higher the birth weight the smaller the odds of the occurrence of the anomaly in a child; - variable PregNo:
![$OR[95%CI]=1.34[1.10;1.63]$](/lib/exe/fetch.php?media=wiki:latex:/img83adba96df6a3f8da91ac10f938c5dce.png "LaTeX") \textendash the odds of the occurrence of the anomaly in a child is
\textendash the odds of the occurrence of the anomaly in a child is  times greater with each subsequent pregnancy;
times greater with each subsequent pregnancy; - variable RespTInf:
![$OR[95%CI]=4.46[2.59;7.69]$](/lib/exe/fetch.php?media=wiki:latex:/img0ece5680df7d3ce3410abedb725c74ff.png "LaTeX") \textendash the odds of the occurrence of the anomaly in a child if the mother had a respiratory tract infection during the pregnancy is
\textendash the odds of the occurrence of the anomaly in a child if the mother had a respiratory tract infection during the pregnancy is  times greater than in a mother who did not have such an infection during the pregnancy;
times greater than in a mother who did not have such an infection during the pregnancy; - variable Smoking:
![$OR[95%CI]=4.44[1.98;9.96]$](/lib/exe/fetch.php?media=wiki:latex:/imgb2af8005ea89d6bb232f3d9cc48f96f9.png "LaTeX") \textendash a mother who smokes when pregnant increases the risk of the occurrence of the anomaly in her child
\textendash a mother who smokes when pregnant increases the risk of the occurrence of the anomaly in her child  times.
times.
In the case of statistically insignificant variables the confidence interval for the Odds Ratio contains 1 which means that the variables neither increase nor decrease the odds of the occurrence of the studied anomaly. Therefore, we cannot interpret the obtained ratio in a manner similar to the case of statistically significant variables.
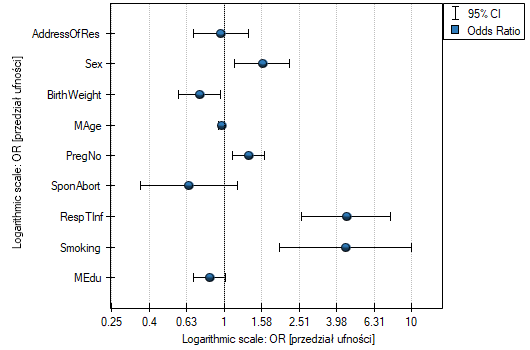
The influence of particular independent variables on the occurrence of the anomaly can also be described with the help of a chart concerning the odds ratio:
EXAMPLE continued (anomaly.pqs file)
Let us once more construct a logistic regression model, however, this time let us divide the variable mother's education into dummy variables (with dummy coding). With this operation we lose the information about the ordering of the category of education but we gain the possibility of a more in-depth analysis of particular categories. The breakdown into dummy variables is done by selecting Dummy var. in the analysis window.:
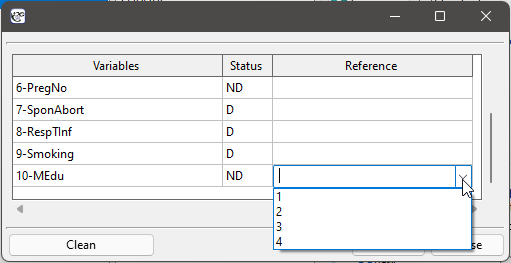
The primary education variable is missing as it will constitute the reference category.
As a result the variables which describe education become statistically significant. The goodness of fit of the model does not change much but the manner of interpretation of the the odds ratio for education does change:
![\begin{tabular}{|l|l|}
\hline
\textbf{Variable}& $OR[95\%CI]$ \\\hline
Primary education& reference category\\
Vocational education& $0.51[0.26;0.99]$\\
Secondary education& $0.42[0.22;0.80]$\\
Tertiary education& $0.45[0.22;0.92]$\\\hline
\end{tabular}](/lib/exe/fetch.php?media=wiki:latex:/img3aecf193332d77c30fecbe6a72e105bf.png "LaTeX")
The odds of the occurrence of the studied anomaly in each education category is always compared with the odds of the occurrence of the anomaly in the case of primary education. We can see that for more educated the mother, the odds is lower. For a mother with:
- vocational education the odds of the occurrence of the anomaly in a child is 0.51 of the odds for a mother with primary education;
- secondary education the odds of the occurrence of the anomaly in a child is 0.42 of the odds for a mother with primary education;
- tertiary education the odds of the occurrence of the anomaly in a child is 0.45 of the odds for a mother with primary education;
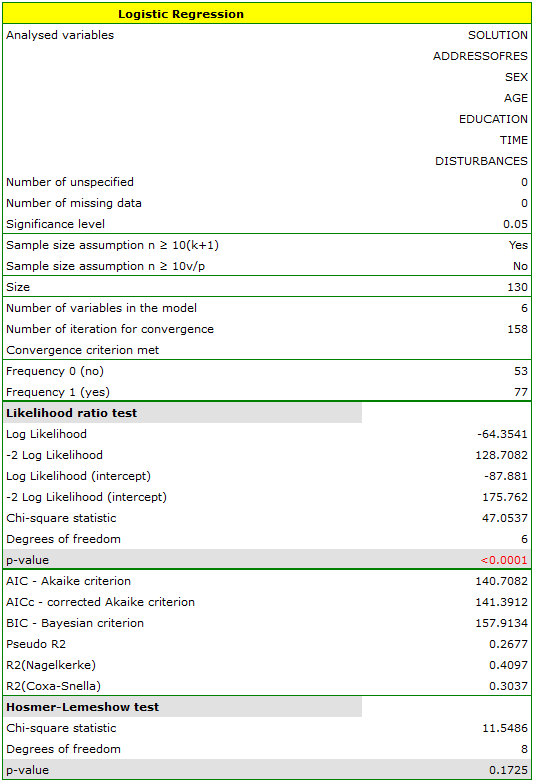
An experiment has been made with the purpose of studying the ability to concentrate of a group of adults in an uncomfortable situation. 190 people have taken part in the experiment (130 people are the teaching set, 40 people are the test set). Each person was assigned a certain task the completion of which requried concentration. During the experiment some people were subject to a disturbing agent in the form of temperature increase to 32 degrees Celsius. The participants were also asked about their address of residence, sex, age, and education. The time for the completion of the task was limited to 45 minutes. In the case of participants who completed the task before the deadline, the actual time devoted to the completion of the task was recorded. We will perform all our calculations only for those belonging to the teaching set. }
Variable SOLUTION (yes/no) contains the result of the experiment, i.e. the information about whether the task was solved correctly or not. The remaining variables which could have influenced the result of the experiment are:
ADDRESSOFRES (1=city/0=village),
SEX (1=female/0=male),
AGE (in years),
EDUCATION (1=primary, 2=vocational, 3=secondary, 4=tertiary),
TIME needed for the completion of the task (in minutes),
DISTURBANCES (1=yes/0=no).
On the basis of all those variables a logistic regression model was built in which the distinguished state of the variable SOLUTION was set to „yes”.
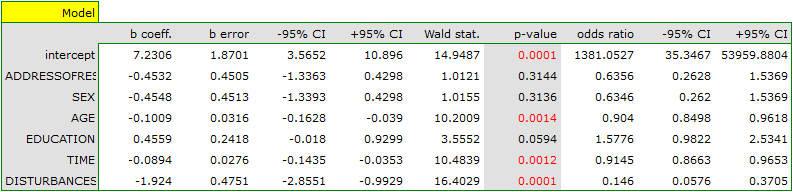
The adequacy quality is described by the coefficients:  ,
,  i
i  . The sufficient adequacy is also indicated by the result of the Hosmer-Lemeshow test
. The sufficient adequacy is also indicated by the result of the Hosmer-Lemeshow test  . The whole model is statistically significant, which is indicated by the result of the Likelihood Ratio test
. The whole model is statistically significant, which is indicated by the result of the Likelihood Ratio test  .
.
The observed values and predicted probability can be observed on the chart:
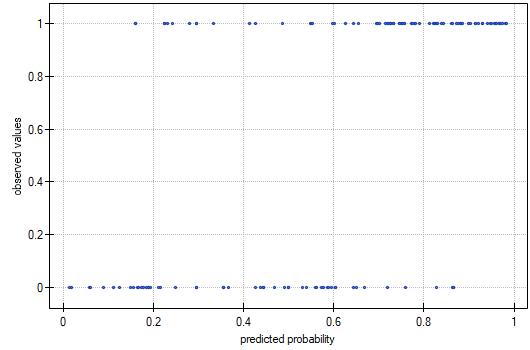
In the model the variables which have a significant influence on the result are:
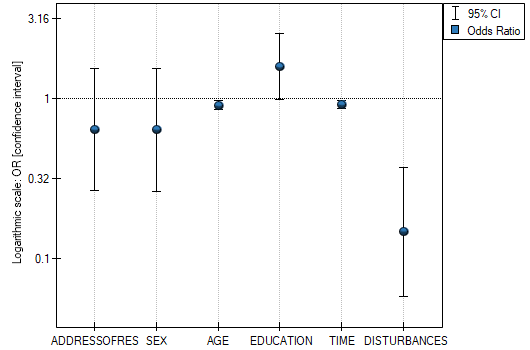
AGE: p=0.0014,
TIME: p=0.0012,
DISTURBANCES: <p=0.0001.
What is more, the younger the person who solves the task the shorter the time needed for the completion of the task, and if there is no disturbing agent, the probability of correct solution is greater:
AGE: ![$OR[95%CI]=0.90[0.85;0.96]$](/lib/exe/fetch.php?media=wiki:latex:/img226dfd2925d31178fe8e1ae93587539b.png "LaTeX") ,
,
TIME: ![$OR[95%CI]=0.91[0.87;0.97]$](/lib/exe/fetch.php?media=wiki:latex:/imgececa7157451978d84f03e91ed3855bd.png "LaTeX") ,
,
DISTURBANCES: ![$OR[95%CI]=0.15[0.06;0.37]$](/lib/exe/fetch.php?media=wiki:latex:/imgd2076e4d8f8244a3103ec18dbc54049c.png "LaTeX") .
.
The obtained results of the Odds Ratio are presented on the chart below:
Should the model be used for prediction, one should pay attention to the quality of classification. For that purpose we calculate the ROC curves.
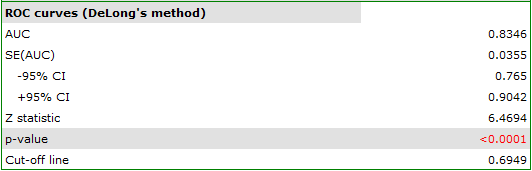
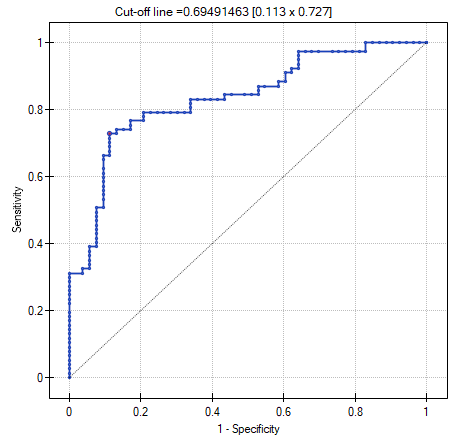
The result seems satisfactory. The area under the curve is  and is statistically greater than
and is statistically greater than 
 , so classification is possible on the basis of the constructed model. The suggested cut-off point for the ROC curve is
, so classification is possible on the basis of the constructed model. The suggested cut-off point for the ROC curve is  and is slightly higher than the standard level used in regression, i.e. . The classification determined from this cut-off point yields
and is slightly higher than the standard level used in regression, i.e. . The classification determined from this cut-off point yields  of cases classified correctly, of which correctly classified
of cases classified correctly, of which correctly classified yes values are  (sensitivity),
(sensitivity), no values are  (specificity). The classification derived from the standard value yields no less,
(specificity). The classification derived from the standard value yields no less,  of cases classified correctly, but it will yield more correctly classified
of cases classified correctly, but it will yield more correctly classified yes values are  , although less correctly classified
, although less correctly classified no values are  .
.
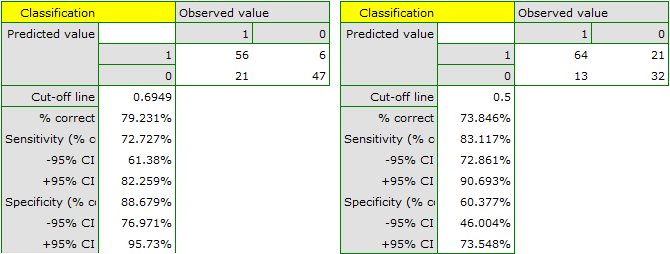
We can finish the analysis of classification at this stage or, if the result is not satisfactory, we can make a more detailed analysis of the ROC curve in module ROC curve.
As we have assumed that classification on the basis of that model is satisfactory we can calculate the predicted value of a dependent variable for any conditions. Let us check what odds of solving the task has a person whose:
ADDRESSOFRES (1=city),
SEX (1=female),
AGE (50 years),
EDUCATION (1=primary),
TIME needed for the completion of the task (20 minutes),
DISTURBANCES (1=yes).
For that purpose, on the basis of the value of coefficient  , we calculate the predicted probability (probability of receiving the answer „yes” on condition of defining the values of dependent variables):
, we calculate the predicted probability (probability of receiving the answer „yes” on condition of defining the values of dependent variables):
![\begin{displaymath}
\begin{array}{l}
P(Y=yes|ADDRESSOFRES,SEX,AGE,EDUCATION,TIME,DISTURBANCES)=\\[0.2cm]
=\frac{e^{7.23-0.45\textrm{\scriptsize \textit{ADDRESSOFRES}}-0.45\textrm{\scriptsize\textit{SEX}}-0.1\textrm{\scriptsize\textit{AGE}}+0.46\textrm{\scriptsize\textit{EDUCATION}}-0.09\textrm{\scriptsize\textit{TIME}}-1.92\textrm{\scriptsize\textit{DISTURBANCES}}}}{1+e^{7.23-0.45\textrm{\scriptsize\textit{ADDRESSOFRES}}-0.45\textrm{\scriptsize\textit{SEX}}-0.1\textrm{\scriptsize\textit{AGE}}+0.46\textrm{\scriptsize\textit{EDUCATION}}-0.09\textrm{\scriptsize\textit{TIME}}-1.92\textrm{\scriptsize\textit{DISTURBANCES}}}}=\\[0.2cm]
=\frac{e^{7.231-0.453\cdot1-0.455\cdot1-0.101\cdot50+0.456\cdot1-0.089\cdot20-1.924\cdot1}}{1+e^{7.231-0.453\cdot1-0.455\cdot1-0.101\cdot50+0.456\cdot1-0.089\cdot20-1.924\cdot1}}
\end{array}
\end{displaymath}](/lib/exe/fetch.php?media=wiki:latex:/img7fac5a4c8360eff8d003a2486f3e0589.png "LaTeX")
As a result of the calculation the program will return the result:
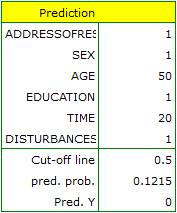
The obtained probability of solving the task is equal to  , so, on the basis of the cut-off
, so, on the basis of the cut-off  , the predicted result is
, the predicted result is  \textendash which means the task was not solved correctly.
\textendash which means the task was not solved correctly.
en/statpqpl/wielowympl/logistpl/przykl.txt · ostatnio zmienione: 2023/03/31 19:08 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
