Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:porown3grpl:parpl:anova_one_waypl
ANOVA dla grup niezależnych
 Jednoczynnikowa analiza wariancji (ANOVA) dla grup niezależnych (ang. one-way analysis of variance) zaproponowana przez Ronalda Fishera, służy do weryfikacji hipotezy o równości średnich badanej zmiennej w kilku (
Jednoczynnikowa analiza wariancji (ANOVA) dla grup niezależnych (ang. one-way analysis of variance) zaproponowana przez Ronalda Fishera, służy do weryfikacji hipotezy o równości średnich badanej zmiennej w kilku ( ) populacjach.
) populacjach.
Podstawowe warunki stosowania:
- pomiar na skali interwałowej,
- normalność rozkładu badanej zmiennej w każdej populacji,
- równość wariancji badanej zmiennej wszystkich populacji.
Hipotezy:

gdzie:
 ,
, ,…,
,…,
 średnie badanej zmiennej w populacjach, z których pobrano próby.
średnie badanej zmiennej w populacjach, z których pobrano próby.
Statystyka testowa ma postać:

gdzie:
 - średnia kwadratów między grupami,
- średnia kwadratów między grupami,
 - średnia kwadratów wewnątrz grup,
- średnia kwadratów wewnątrz grup,
 - suma kwadratów między grupami,
- suma kwadratów między grupami,
 - suma kwadratów wewnątrz grup,
- suma kwadratów wewnątrz grup,
 - całkowita suma kwadratów,
- całkowita suma kwadratów,
 - stopnie swobody (między grupami),
- stopnie swobody (między grupami),
 - stopnie swobody (wewnątrz grup),
- stopnie swobody (wewnątrz grup),
 - całkowite stopnie swobody,
- całkowite stopnie swobody,
 ,
,
 - liczności prób dla
- liczności prób dla  ,
,
 - wartości zmiennej w próbach dla
- wartości zmiennej w próbach dla  , .
, .
Statystyka ta podlega rozkładowi F Snedecora z  i
i  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość  porównujemy z poziomem istotności
porównujemy z poziomem istotności  :
:

Wielkość efektu - cząstkowa 
Wielkość ta określa proporcję wariancji wyjaśnionej do wariancji całkowitej związanej z danym czynnikiem. Zatem w modelu jednoczynnikowej ANOVA dla grup niezależnych wskazuje jaka część wewnątrzosobowej zmienności wyników może być przypisana badanemu czynnikowi wyznaczającemu grupy niezależne.

Testy POST-HOC
Wprowadzenie do kontrastów i testów POST-HOC
Okno z ustawieniami opcji jednoczynnikowej ANOVA dla grup niezależnych wywołujemy poprzez menu Statystyka→Testy parametryczne→ANOVA dla grup niezależnych lub poprzez Kreator.
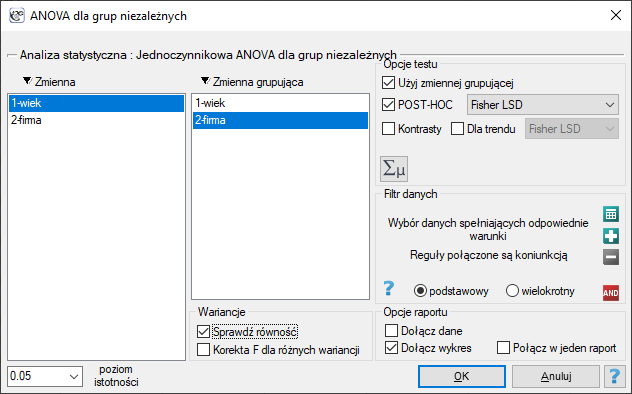
Przykład (plik wiek ANOVA.pqs)
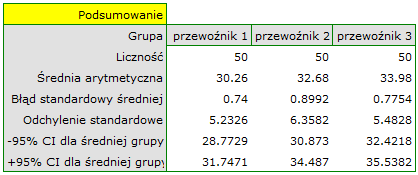
W pewnym doświadczeniu bierze udział 150 osób wybranych w sposób losowy z populacji pracowników 3 różnych firm przewozowych. Z każdej firmy do próby wybrano 50 osób. Przed przystąpieniem do eksperymentu należy sprawdzić czy średni wiek pracowników tych firm jest podobny, od tego bowiem zależeć będzie kolejny etap eksperymentu. Wiek każdego uczestnika eksperymentu zapisano w latach.
Wiek (przewoźnik 1): 27, 33, 25, 32, 34, 38, 31, 34, 20, 30, 30, 27, 34, 32, 33, 25, 40, 35, 29, 20, 18, 28, 26, 22, 24, 24, 25, 28, 32, 32, 33, 32, 34, 27, 34, 27, 35, 28, 35, 34, 28, 29, 38, 26, 36, 31, 25, 35, 41, 37
Wiek (przewoźnik 2): 38, 34, 33, 27, 36, 20, 37, 40, 27, 26, 40, 44, 36, 32, 26, 34, 27, 31, 36, 36, 25, 40, 27, 30, 36, 29, 32, 41, 49, 24, 36, 38, 18, 33, 30, 28, 27, 26, 42, 34, 24, 32, 36, 30, 37, 34, 33, 30, 44, 29
Wiek (przewoźnik 3): 34, 36, 31, 37, 45, 39, 36, 34, 39, 27, 35, 33, 36, 28, 38, 25, 29, 26, 45, 28, 27, 32, 33, 30, 39, 40, 36, 33, 28, 32, 36, 39, 32, 39, 37, 35, 44, 34, 21, 42, 40, 32, 30, 23, 32, 34, 27, 39, 37, 35
Przed przystąpieniem do analizy ANOVA potwierdzono normalność rozkładu danych.
W oknie analizy sprawdzono założenie równości wariancji, uzyskując w obydwu testach p>0.05.
Hipotezy:

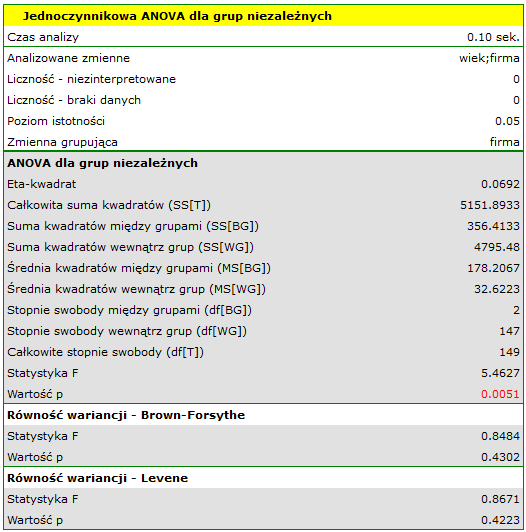
Porównując wartość  jednoczynnikowej analizy wariancji z poziomem istotności
jednoczynnikowej analizy wariancji z poziomem istotności  stwierdzamy, że średni wiek pracowników tych firm przewozowych jest różny. Na podstawie wyniku samej ANOVA nie możemy odpowiedzieć sobie na pytanie, które grupy różnią się pod względem wieku. By uzyskać taką wiedzę wykorzystany zostanie jeden z testów POST-HOC, np. test Tukeya. W tym celu {wznawiamy analizę} przyciskiem
stwierdzamy, że średni wiek pracowników tych firm przewozowych jest różny. Na podstawie wyniku samej ANOVA nie możemy odpowiedzieć sobie na pytanie, które grupy różnią się pod względem wieku. By uzyskać taką wiedzę wykorzystany zostanie jeden z testów POST-HOC, np. test Tukeya. W tym celu {wznawiamy analizę} przyciskiem  i w oknie opcji testu wybieramy
i w oknie opcji testu wybieramy Tukey HSD oraz dołączmy wykres.
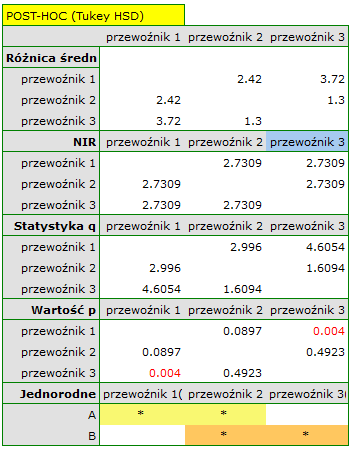
Najmniejsza istotna różnica (NIR) wyznaczona dla każdej pary porównań jest taka sama (ponieważ liczności grup są sobie równe) i wynosi 2.7309. Porównanie wartości NIR z wartością różnicy średnich wskazuje, że istotne różnice występują tylko pomiędzy wartością średnią dla wieku pracowników pierwszej i trzeciej firmy przewozowej (tylko w przypadku porównania tych dwóch grup wartość NIR jest mniejsza od różnicy średnich). Ten sam wniosek wyciągniemy porównując wartości testu POST-HOC z poziomem istotności . Pracownicy pierwszej firmy są młodsi średnio o nieco ponad 3 lata od pracowników trzeciej firmy. Uzyskano dwie, zazębiające się grupy jednorodne, które zaznaczono również na wykresie.
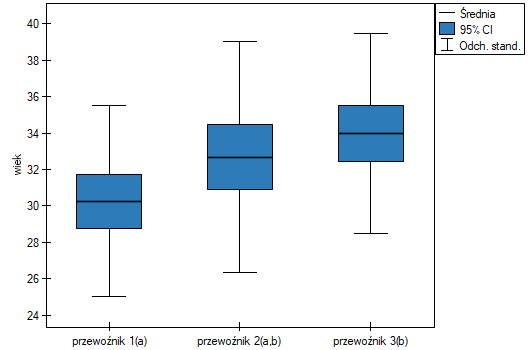
Dokładny opis danych możemy przedstawić wybierając w oknie analizy statystyki opisowe 
statpqpl/porown3grpl/parpl/anova_one_waypl.txt · ostatnio zmienione: 2022/01/31 12:18 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
