Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:porown1grpl:nparpl
Spis treści
Testy nieparametryczne
Test Wilcoxona (rangowanych znaków)
Test Wilcoxona rangowanych znaków (ang. Wilcoxon signed-ranks test) znany również pod nazwą testu Wilcoxona dla pojedynczej próby, Wilcoxon (1945, 1949)1). Test ten służy do weryfikacji hipotezy, że badana próba pochodzi z populacji, dla której mediana ( ) to znana wartość.
) to znana wartość.
Podstawowe warunki stosowania:
- pomiar na skali porządkowej lub interwałowej.
Hipotezy dotyczą równości sumy rang dodatnich i ujemnych lub są upraszczane do median:

gdzie:
- mediana badanej cechy w populacji reprezentowanej przez badaną próbę,
 - zadana wartość.
- zadana wartość.
Wyznaczamy wartość statystyki testowej  (
( - dla małej liczności próby), a na jej podstawie wartość
- dla małej liczności próby), a na jej podstawie wartość  .
.
Porównujemy wartość z poziomem istotności  :
:

Uwaga!
W zależności od wielkości próby statystyka testowa przyjmuje inną postać:
- dla małej liczności próby

gdzie:  i
i  to odpowiednio: suma rang dodatnich i suma rang ujemnych.
to odpowiednio: suma rang dodatnich i suma rang ujemnych.
Statystyka ta podlega rozkładowi Wilcoxona
- dla próby o dużej liczności

gdzie:  - liczba rangowanych znaków (liczba rang),
- liczba rangowanych znaków (liczba rang),
 - liczba przypadków wchodzących w skład rangi wiązanej.
- liczba przypadków wchodzących w skład rangi wiązanej.
Wzór na statystykę testową zawiera poprawkę na rangi wiązane. Poprawka ta powinna być stosowana, gdy rangi wiązane występują (gdy nie ma rang wiązanych poprawka ta nie jest wyliczana, gdyż wówczas  .
.
Statystyka ma asymptotycznie (dla dużych liczności) rozkład normalny.
Poprawka na ciągłość testu Wilcoxona (Marascuilo and McSweeney (1977)2))
Poprawkę na ciągłość stosujemy by zapewnić możliwość przyjmowania przez statystykę testową wszystkich wartości liczb rzeczywistych zgodnie z założeniem rozkładu normalnego. Wzór na statystykę testową z poprawką na ciągłość wyraża się wtedy wzorem:

Standaryzowana wielkość efektu
Rozkład statystyki testu Wilcoxona jest aproksymowany przez rozkłady normalny, który można przekształcić na wielkość efektu  3) by następnie uzyskać wartość d-Cohena zgodnie ze standardową konwersją stosowaną przy meta-analizach:
3) by następnie uzyskać wartość d-Cohena zgodnie ze standardową konwersją stosowaną przy meta-analizach:

Przy interpretacji efektu badacze często posługują się ogólnymi, określonymi przez Cohena 4) wskazówkami definiującymi małą (0.2), średnią (0.5) i dużą (0.8) wielkość efektu.
Okno z ustawieniami opcji testu Wilcoxona (rangowanych znaków) wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Wilcoxon (rangowanych znaków) lub poprzez ''Kreator''.
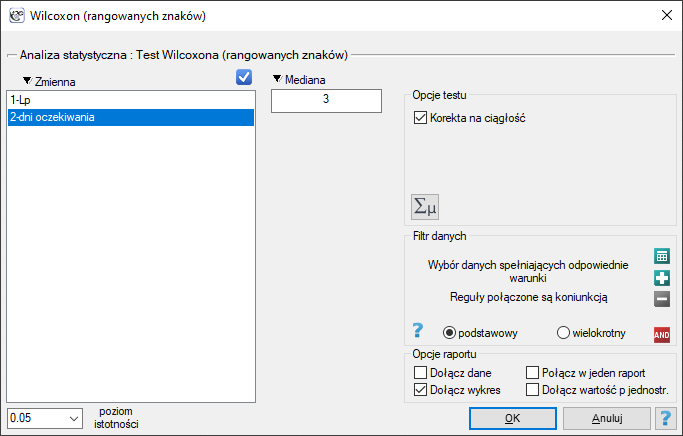
Przykład (plik kurier.pqs) c.d
Hipotezy:

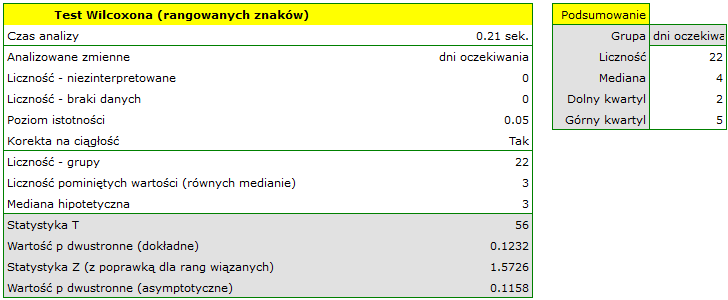
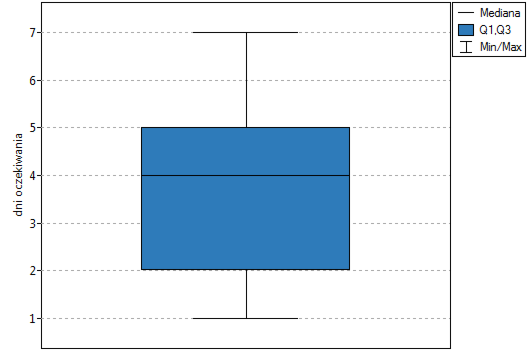
Porównując wartość  testu Wilcoxona opartego o statystykę z poziomem istotności
testu Wilcoxona opartego o statystykę z poziomem istotności  stwierdzamy, że nie mamy podstaw by odrzucić hipotezę zerową mówiącą, że zwykle liczba dni oczekiwania na dostarczenie przesyłki przez analizowaną firmę kurierską wynosi 3. Taką samą decyzję podjęlibyśmy również na podstawie wartości
stwierdzamy, że nie mamy podstaw by odrzucić hipotezę zerową mówiącą, że zwykle liczba dni oczekiwania na dostarczenie przesyłki przez analizowaną firmę kurierską wynosi 3. Taką samą decyzję podjęlibyśmy również na podstawie wartości  lub
lub  testu Wilcoxona opartego o statystykę lub z poprawką na ciągłość.
testu Wilcoxona opartego o statystykę lub z poprawką na ciągłość.
Test chi-kwadrat zgodności
Test  zgodności (dobroci dopasowania) (ang. Chi-square goodnes-of-fit test) nazywany jest również testem dla pojedynczej próby, przeznaczony jest do testowania zgodności wartości obserwowanych dla
zgodności (dobroci dopasowania) (ang. Chi-square goodnes-of-fit test) nazywany jest również testem dla pojedynczej próby, przeznaczony jest do testowania zgodności wartości obserwowanych dla  (
( ) kategorii
) kategorii  jednej cechy
jednej cechy  z hipotetycznymi wartościami oczekiwanymi dla tej cechy. Wartości wszystkich pomiarów należy zebrać w postaci tabeli składającej się z wierszy (kategorii:
z hipotetycznymi wartościami oczekiwanymi dla tej cechy. Wartości wszystkich pomiarów należy zebrać w postaci tabeli składającej się z wierszy (kategorii:  ). Dla każdej kategorii
). Dla każdej kategorii  zapisuje się częstość jej występowania
zapisuje się częstość jej występowania  , oraz częstość dla niej oczekiwaną
, oraz częstość dla niej oczekiwaną  lub prawdopodobieństwo jej wystąpienia
lub prawdopodobieństwo jej wystąpienia  . Częstość oczekiwana jest wyznaczana jako iloczyn
. Częstość oczekiwana jest wyznaczana jako iloczyn  .
.
Utworzona tabela może przyjąć jedną z poniższych postaci:
![\begin{tabular}[t]{c@{\hspace{1cm}}c}
\begin{tabular}{c|c c}
Kategorie $X_i$ & $O_i$ & $E_i$ \\\hline
$X_1$ & $O_1$ & $E_i$ \\
$X_2$ & $O_2$ & $E_2$ \\
... & ... & ...\\
$X_r$ & $O_r$ & $E_r$ \\
\end{tabular}
&
\begin{tabular}{c|c c}
Kategorie $X_i$ & $O_i$ & $p_i$ \\\hline
$X_1$ & $O_1$ & $p_1$ \\
$X_2$ & $O_2$ & $p_2$ \\
... & ... & ...\\
$X_r$ & $O_r$ & $p_r$ \\
\end{tabular}
\end{tabular}](/lib/exe/fetch.php?media=wiki:latex:/img53c42b4f4572477f9cbd987271a3d7c9.png "LaTeX")
Podstawowe warunki stosowania:
- pomiar na skali nominalnej - ewentualne uporządkowanie kategorii nie jest brane pod uwagę,
- suma liczności obserwowanych powinna być taka sama jak suma liczności oczekiwanych, a suma wszystkich prawdopodobieństw powinna wynosić 1.
Hipotezy:
 dla wszystkich kategorii,
dla wszystkich kategorii,
 dla przynajmniej jednej kategorii.
dla przynajmniej jednej kategorii.
Statystyka testowa ma postać:
 Statystyka ta ma asymptotycznie (dla dużych liczności oczekiwanych) rozkład chi-kwadrat z liczbą stopni swobody wyznaczaną według wzoru:
Statystyka ta ma asymptotycznie (dla dużych liczności oczekiwanych) rozkład chi-kwadrat z liczbą stopni swobody wyznaczaną według wzoru:  .
.
Wyznaczoną na podstawie wartości statystyki i rozkładu wartość porównujemy z poziomem istotności :

Okno z ustawieniami opcji testu Chi-kwadrat zgodności wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Chi-kwadrat lub poprzez ''Kreator''.
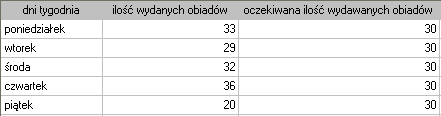
Chcielibyśmy się dowiedzieć, czy liczba wydawanych obiadów w kolejnych dniach tygodnia (od poniedziałku do piątku) w pewnej szkolnej stołówce jest statystycznie taka sama. W tym celu pobrano tygodniową próbę i zapisano dla niej liczbę wydanych obiadów w poszczególnych dniach: poniedziałek - 33, wtorek - 29, środa - 32, czwartek - 36, piątek - 20.}
Łącznie przez cały tydzień (5 dni) wydano 150 obiadów.
Zakładamy, że w każdy dzień prawdopodobieństwo wydania obiadu jest takie samo, czyli wynosi  . Oczekiwana liczba wydanych obiadów dla każdego z pięciu dni tygodnia wynosi więc
. Oczekiwana liczba wydanych obiadów dla każdego z pięciu dni tygodnia wynosi więc  .
.
Postawiono hipotezy:

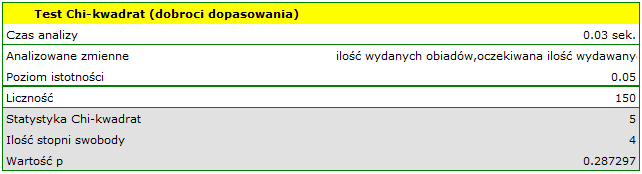
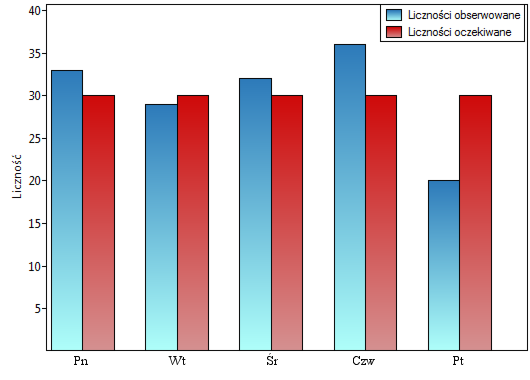
Wartość z rozkładu dla 4 stopni swobody wynosi 0.287297. Zatem na poziomie istotności możemy powiedzieć, że nie mamy podstaw, aby odrzucić hipotezę zerową mówiącą o zgodności liczby wydawanych obiadów z oczekiwaną liczbą wydawanych obiadów w poszczególnych dniach.
Uwaga!
Gdybyśmy chcieli w ramach jednego badania dokonać większej liczby porównań, moglibyśmy zastosować poprawkę Bonferroniego 6) lub inną z poprawek opisanych w dziale Wielokrotne porównania. Ta poprawka jest używana by ograniczyć wielkość popełnionego błędu pierwszego rodzaju, gdy porównujemy wartości obserwowane i oczekiwane pomiędzy wybranymi dniami np:
Pt  Pn,
Pn,
Pt Wt,
Pt Śr,
Pt Czw,
przy założeniu, że porównania wykonujemy niezależnie. Poziom istotności dla każdego porównania wyznaczamy zgodnie z tą poprawką według wzoru:  , gdzie to liczba wykonywanych porównań. Poziom istotności dla pojedynczego porównania zgodnie z poprawką Bonferroniego wynosi dla naszego przykładu
, gdzie to liczba wykonywanych porównań. Poziom istotności dla pojedynczego porównania zgodnie z poprawką Bonferroniego wynosi dla naszego przykładu  .
.
Należy jednak pamiętać, że redukując dla każdego porównania zmniejszamy również moc testu.
Testy dla jednej proporcji

Testy dla jednej proporcji stosujemy, gdy mamy do uzyskania dwa możliwe wyniki (jeden z nich to wynik wyróżniony o liczności  ) i wiemy, jak często te wyniki pojawiają się w próbie (znamy proporcję ). W zależności od wielkości próby mamy do wyboru test dla jednej proporcji
) i wiemy, jak często te wyniki pojawiają się w próbie (znamy proporcję ). W zależności od wielkości próby mamy do wyboru test dla jednej proporcji  dla dużych prób oraz test dokładny dwumianowy dla prób o małej liczności. Testy te służą do weryfikacji hipotezy, że proporcja w populacji z której pochodzi próba to zadana wartość.
dla dużych prób oraz test dokładny dwumianowy dla prób o małej liczności. Testy te służą do weryfikacji hipotezy, że proporcja w populacji z której pochodzi próba to zadana wartość.
Podstawowe warunki stosowania:
- pomiar na skali nominalnej - ewentualne uporządkowanie kategorii nie jest brane pod uwagę.
Dodatkowy warunek dla testu dla jednej proporcji:
 i
i  ).
).Hipotezy:

gdzie:
prawdopodobieństwo (wyróżniona proporcja) w populacji,
 prawdopodobieństwo oczekiwane (proporcja oczekiwana).
prawdopodobieństwo oczekiwane (proporcja oczekiwana).
Test dla jednej proporcji
Test dla jednej proporcji (ang. Z test for one proportion).
Statystyka testowa ma postać:
 gdzie:
gdzie:
 proporcja dla próby z tej populacji,
proporcja dla próby z tej populacji,
-liczność wartości wyszczególnionych w próbie,
- liczność próby.
Zmodyfikowana o poprawkę na ciągłość statystyka testowa ma postać:

Statystyka bez korekcji na ciągłość jak i z tą korekcją ma asymptotycznie (dla dużych liczności) rozkład normalny.
Test dwumianowy
Test dwumianowy (ang. Binominal test for one proportion) wykorzystuje w sposób bezpośredni rozkład dwumianowy zwany również rozkładem Bernoulliego, który należy do grupy rozkładów dyskretnych (czyli takich, w których badana zmienna przyjmuje skończoną liczbę wartości). Analizowana zmienna może przyjmować  wartości, pierwszą oznaczaną zwykle mianem sukcesu a drugą porażki. Prawdopodobieństwo wystąpienia sukcesu to , a porażki
wartości, pierwszą oznaczaną zwykle mianem sukcesu a drugą porażki. Prawdopodobieństwo wystąpienia sukcesu to , a porażki  .
.
Prawdopodobieństwo dla konkretnego punktu w tym rozkładzie wyliczane jest ze wzoru:
 gdzie:
gdzie:
 ,
,
- liczność wartości wyszczególnionych w próbie,
- liczność próby.
Na podstawie sumy odpowiednich prawdopodobieństw  wyznacza się wartość jednostronną i dwustronną, przy czym dwustronna wartość jest definiowana jako podwojona wartość mniejszego z jednostronnych prawdopodobieństw. Wartość porównujemy z poziomem istotności :
wyznacza się wartość jednostronną i dwustronną, przy czym dwustronna wartość jest definiowana jako podwojona wartość mniejszego z jednostronnych prawdopodobieństw. Wartość porównujemy z poziomem istotności :

Uwaga!
Dla estymatora z próby jakim jest w tym przypadku wartość proporcji wyznacza się przedział ufności. Dla prób o dużej liczności można bazować na przedziałach opartych o rozkład normalny - tzw. przedziały Walda. Bardziej uniwersalne są natomiast przedziały zaproponowane przez Wilsona (1927)8) a także Agresti i Coull (1998)9). Przedziały Cloppera i Pearsona (1934)10) są dokładniejsze dla prób o mniejszej liczności.
Porównanie metod budowania przedziałów dla proporcji można znaleźć w pracy Brown L.D i innych (2001)11).
Okno z ustawieniami opcji testu Z dla jednej proporcji wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Z dla proporcji.
Przykład c.d. (plik obiady.pqs)
Załóżmy, że chcielibyśmy sprawdzić, czy w piątek wydawana jest spośród wszystkich obiadów wydawanych w szkolnej stołówce w ciągu tygodnia. Dla pobranej próby  ,
,  .
.
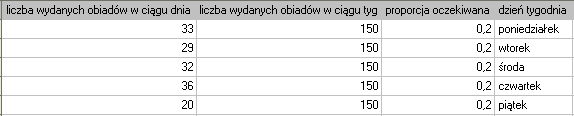
Przy ustawianiu opcji analizy włączamy filtr wybierając odpowiedni dzień tygodnia - czyli piątek. Brak ustawienia filtru nie generuje błędu a jedynie wyliczenie kolejnych statystyk dla kolejnych dni tygodnia.
Hipotezy:

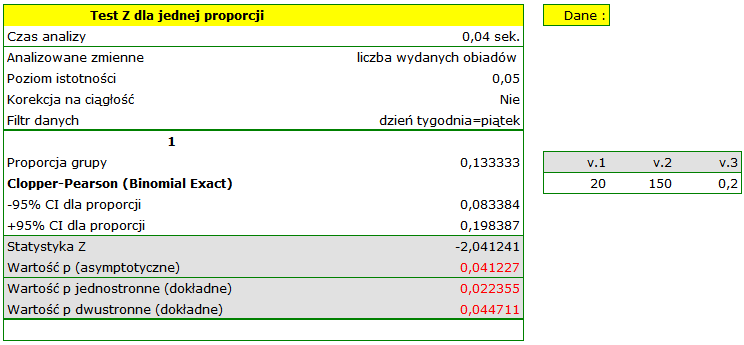
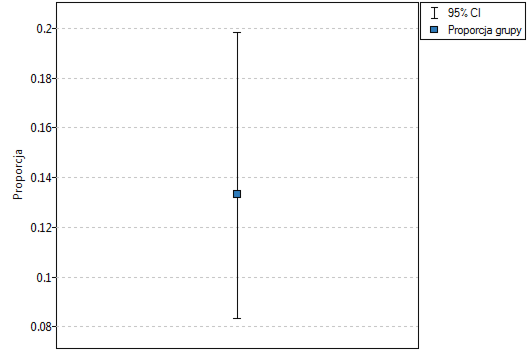
Proporcja wartości wyróżnionych w próbie to  a 95% przedział ufności Cloppera-Pearsona dla tej frakcji
a 95% przedział ufności Cloppera-Pearsona dla tej frakcji  nie zawiera hipotetycznej wartości 0.2.
nie zawiera hipotetycznej wartości 0.2.
Na podstawie testu bez poprawki na ciągłość (=0.041227) jak i na podstawie dokładnej wartości prawdopodobieństwa wyliczonego z rozkładu dwumianowego (=0.044711) moglibyśmy przyjąć (na poziomie istotności ), że w piątek wydaje się statystycznie mniej niż obiadów wydawanych przez cały tydzień. Po zastosowaniu poprawki na ciągłość jednak nie udaje się odrzucić hipotezy zerowej (=0.052479).
1)
Wilcoxon F. (1945), Individual comparisons by ranking methods. Biometries 1, 80-83
2)
, 7)
Marascuilo L.A. and McSweeney M. (1977), Nonparametric and distribution-free method for the social sciences. Monterey, CA: Brooks Cole Publishing Company
3)
Fritz C.O., Morris P.E., Richler J.J.(2012), Effect size estimates: Current use, calculations, and interpretation. Journal of Experimental Psychology: General., 141(1):2–18.
4)
Cohen J. (1988), Statistical Power Analysis for the Behavioral Sciences, Lawrence Erlbaum Associates, Hillsdale, New Jersey
5)
Cochran W.G. (1952), The chi-square goodness-of-fit test. Annals of Mathematical Statistics, 23, 315-345
6)
Abdi H. (2007), Bonferroni and Sidak corrections for multiple comparisons, in N.J. Salkind (ed.): Encyclopedia of Measurement and Statistics. Thousand Oaks, CA: Sage
8)
E.B. (1927), Probable Inference, the Law of Succession, and Statistical Inference. Journal of the American Statistical Association: 22(158):209-212
9)
Agresti A., Coull B.A. (1998), Approximate is better than „exact” for interval estimation of binomial proportions. American Statistics 52: 119-126
10)
Clopper C. and Pearson S. (1934), The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika 26: 404-413
11)
Brown L.D., Cai T.T., DasGupta A. (2001), Interval Estimation for a Binomial Proportion. Statistical Science, Vol. 16, no. 2, 101-133
statpqpl/porown1grpl/nparpl.txt · ostatnio zmienione: 2019/08/24 13:27 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
