Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:wielowympl:wielorpl
Spis treści
Liniowa regresja wieloraka
Okno z ustawieniami opcji Regresji wielorakiej wywołujemy poprzez menu Statystyka zaawansowana→Modele wielowymiarowe→Regresja wieloraka
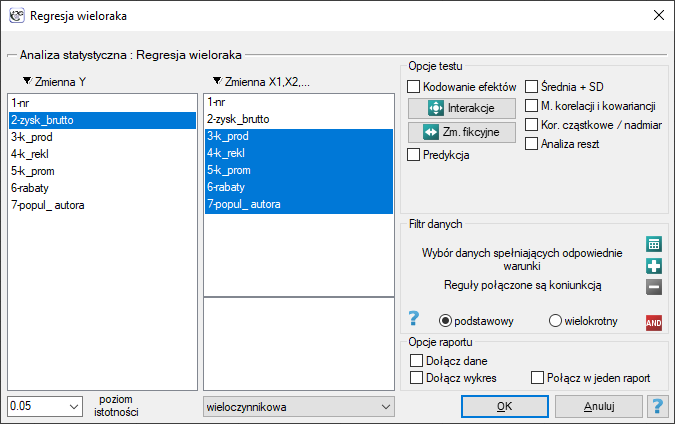
 Budowany model regresji wielorakiej pozwala na zbadanie wpływu wielu zmiennych niezależnych (
Budowany model regresji wielorakiej pozwala na zbadanie wpływu wielu zmiennych niezależnych ( ,
,  ,
,  ,
,  ) na jedną zmienną zależną (
) na jedną zmienną zależną ( ). Najczęściej wykorzystywaną odmianą regresji wielorakiej jest Liniowa Regresja Wieloraka. Jest ona rozszerzeniem modeli regresji liniowej opartej o współczynnik korelacji liniowej Pearsona. Zakłada ona występowanie liniowego związku pomiędzy badanymi zmiennymi. Liniowy model regresji wielorakiej przyjmuje postać:
). Najczęściej wykorzystywaną odmianą regresji wielorakiej jest Liniowa Regresja Wieloraka. Jest ona rozszerzeniem modeli regresji liniowej opartej o współczynnik korelacji liniowej Pearsona. Zakłada ona występowanie liniowego związku pomiędzy badanymi zmiennymi. Liniowy model regresji wielorakiej przyjmuje postać:

gdzie:
- zmienna zależna, objaśniana przez model,
 - zmienne niezależne, objaśniające,
- zmienne niezależne, objaśniające,
 - parametry,
- parametry,
 - składnik losowy (reszta modelu).
- składnik losowy (reszta modelu).
Jeśli model został stworzony w oparciu o próbę o liczności  powyższe równanie można przedstawić w postaci macierzowej:
powyższe równanie można przedstawić w postaci macierzowej:

gdzie:




Rozwiązaniem równania jest wówczas wektor ocen parametrów  nazywanych współczynnikami regresji:
nazywanych współczynnikami regresji:

Współczynniki te szacowane są poprzez klasyczną metodę najmniejszych kwadratów. Na podstawie tych wartości możemy wnioskować o wielkości wpływu zmiennej niezależnej (dla której ten współczynnik został oszacowany) na zmienną zależną. Podają o ile jednostek zmieni się zmienna zależna, gdy zmienną niezależną zmienimy o 1 jednostkę. Każdy współczynnik obarczony jest pewnym błędem szacunku. Wielkość tego błędu wyliczana jest ze wzoru:

gdzie:
 to wektor reszt modelu (różnica pomiędzy rzeczywistymi wartościami zmiennej zależnej Y a wartościami
to wektor reszt modelu (różnica pomiędzy rzeczywistymi wartościami zmiennej zależnej Y a wartościami  przewidywanymi na podstawie modelu).
przewidywanymi na podstawie modelu).
Zmienne fikcyjne i interakcje w modelu
Omówienie przygotowania zmiennych fikcyjnych i interakcji przedstawiono w rozdziale Przygotowanie zmiennych do analizy w modelach wielowymiarowych.
Uwaga!
Budując model należy pamiętać, że liczba obserwacji musi być duża, to znaczy powinna spełniać założenie:  , gdzie k, to liczba zmiennych objaśniających w modelu 1).
, gdzie k, to liczba zmiennych objaśniających w modelu 1).
Weryfikacja modelu
- Istotność statystyczna poszczególnych zmiennych w modelu.
Na podstawie współczynnika oraz jego błędu szacunku możemy wnioskować czy zmienna niezależna, dla której ten współczynnik został oszacowany wywiera istotny wpływ na zmienną zależną. W tym celu posługujemy się testem t-Studenta.
Hipotezy:

Wyliczmy statystykę testową według wzoru:

Statystyka testowa ma rozkład t-Studenta z  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość  porównujemy z poziomem istotności
porównujemy z poziomem istotności  :
:

- Jakość zbudowanego modelu liniowej regresji wielorakiej możemy ocenić kilkoma miarami.
- Błąd standardowy estymacji - jest miarą dopasowania modelu:

Miara ta opiera się na resztach modelu  , czyli rozbieżności pomiędzy rzeczywistymi wartościami zmiennej zależnej
, czyli rozbieżności pomiędzy rzeczywistymi wartościami zmiennej zależnej  w próbie a wartościami zmiennej zależnej
w próbie a wartościami zmiennej zależnej  wyliczonej na podstawie zbudowanego modelu. Najlepiej byłoby, gdyby różnica ta była jak najbliższa zeru dla wszystkich badanych obiektów próby. Zatem, aby model był dobrze dopasowany, błąd standardowy estymacji (
wyliczonej na podstawie zbudowanego modelu. Najlepiej byłoby, gdyby różnica ta była jak najbliższa zeru dla wszystkich badanych obiektów próby. Zatem, aby model był dobrze dopasowany, błąd standardowy estymacji ( ) wyrażony jako wariancja
) wyrażony jako wariancja  , powinien być jak najmniejszy.
, powinien być jak najmniejszy.
- Współczynnik korelacji wielorakiej
 - określa siłę oddziaływania zespołu zmiennych na zmienną zależną .
- określa siłę oddziaływania zespołu zmiennych na zmienną zależną .
- Współczynnik determinacji wielorakiej
 - jest miarą dopasowania modelu.
- jest miarą dopasowania modelu.
Wartość tego współczynnika mieści się w przedziale  , gdzie 1 oznacza doskonałe dopasowanie modelu, 0 - zupełny bark dopasowania. W jego wyznaczeniu posługujemy się następującą równością:
, gdzie 1 oznacza doskonałe dopasowanie modelu, 0 - zupełny bark dopasowania. W jego wyznaczeniu posługujemy się następującą równością:

gdzie:
 - całkowita suma kwadratów,
- całkowita suma kwadratów,
 - suma kwadratów wyjaśniona przez model,
- suma kwadratów wyjaśniona przez model,
 - resztowa suma kwadratów.
- resztowa suma kwadratów.
Współczynnik determinacji wyliczamy z wzoru:

Wyraża on procent zmienności zmiennej zależnej tłumaczony przez model.
Ponieważ wartość współczynnika zależy od dopasowania modelu, ale jest również wrażliwa na ilość zmiennych w modelu i liczność próby, bywają sytuacje, w których może być obarczona pewnym błędem. Dalego też wyznacza się poprawianą wartość tego parametru:

- Kryteria informacyjne opierają się na entropii informacji niesionej przez model (niepewności modelu) tzn. szacują utraconą informację, gdy dany model jest używany do opisu badanego zjawiska. Powinniśmy zatem wybierać model o minimalnej wartości danego kryterium informacyjnego.
 ,
,  i
i  jest rodzajem kompromisu pomiędzy dobrocią dopasowania i złożonością. Drugi element sumy we wzorach na kryteria informacyjne (tzw. funkcja straty lub kary) mierzy prostotę modelu. Zależy on od liczby zmiennych w modelu (
jest rodzajem kompromisu pomiędzy dobrocią dopasowania i złożonością. Drugi element sumy we wzorach na kryteria informacyjne (tzw. funkcja straty lub kary) mierzy prostotę modelu. Zależy on od liczby zmiennych w modelu ( ) i liczności próby (). W obu przypadkach element ten rośnie wraz ze wzrostem liczby zmiennych i wzrost ten jest tym szybszy im mniejsza jest liczba obserwacji.
Kryterium informacyjne nie jest jednak miarą absolutną, tzn. jeśli wszystkie porównywane modele źle opisują rzeczywistość w kryterium informacyjnym nie ma sensu szukać ostrzeżenia.
) i liczności próby (). W obu przypadkach element ten rośnie wraz ze wzrostem liczby zmiennych i wzrost ten jest tym szybszy im mniejsza jest liczba obserwacji.
Kryterium informacyjne nie jest jednak miarą absolutną, tzn. jeśli wszystkie porównywane modele źle opisują rzeczywistość w kryterium informacyjnym nie ma sensu szukać ostrzeżenia.
Kryterium informacyjne Akaikego (ang. Akaike information criterion)

gdzie, stałą można pominąć, ponieważ jest taka sama w każdym z porównywanych modeli.
Jest to kryterium asymptotyczne - odpowiednie dla dużych prób tzn. gdy  . Przy małych próbach ma tendencję do preferowania modeli z dużą liczbą zmiennych.
. Przy małych próbach ma tendencję do preferowania modeli z dużą liczbą zmiennych.
Przykład interpretacji porównania wielkości AIC
Załóżmy, że wyznaczyliśmy AIC dla trzech modeli AIC1=100, AIC2=101.4, AIC3=110. Wówczas można wyznaczyć względną wiarygodność dla modelu. Wiarygodność ta jest względna, gdyż wyznaczana jest względem innego modelu, najczęściej tego o najmniejszej wartości AIC. Wyznaczamy ją wg wzoru: exp((AICmin− AICi)/2). Porównując model 2 do modelu pierwszego powiemy, że prawdopodobieństwo, iż zminimalizuje on utratę informacji stanowi około połowę prawdopodobieństwa, że zrobi to model 1 (a dokładnie exp((100− 101.4)/2) = 0.497). Porównując model 3 do modelu pierwszego powiemy, że prawdopodobieństwo, iż zminimalizuje on utratę informacji stanowi niewielką część prawdopodobieństwa, że zrobi to model 1 (a dokładnie exp((100- 110)/2) = 0.007).
Poprawione kryterium informacyjne Akaikego

Poprawka kryterium Akaikego dotyczy wielkości próby, przez co jest to miara rekomendowana również dla prób o małych licznościach.
Bayesowskie kryterium informacyjne Schwartza (ang. Bayes Information Criterion lub Schwarz criterion)

gdzie, stałą można pominąć, ponieważ jest taka sama w każdym z porównywanych modeli.
Podobnie jak poprawione kryterium Akaikego BIC uwzględnia wielkość próby.
- Analiza błędów dla prognoz ex post:
MAE (średni błąd bezwzględny) ang. mean absolute error – trafność prognozy określona przez MAE informuje o ile średnio uzyskiwane realizacje zmiennej zależnej będę się odchylać (co do wartości bezwzględnej) od prognoz.

MPE (średni błąd procentowy) ang. mean percentage error – informuje, jaki średni procent realizacji zmiennej zależnej stanowią błędy prognozy.

MAPE (średni bezwzględny błąd procentowy) ang. mean absolute percentage error – informuje o średniej wielkości błędów prognoz wyrażonych w procentach rzeczywistych wartości zmiennej zależnej. MAPE pozwala porównać dokładność prognoz uzyskanych na bazie różnych modeli.

- Istotność statystyczna wszystkich zmiennych w modelu
Podstawowym narzędziem szacującym istotność wszystkich zmiennych w modelu jest test analizy wariancji (test F). Test ten weryfikuje jednocześnie 3 równoważne hipotezy:


Statystyka testowa ma postać:

gdzie:
 - średnia kwadratów wyjaśniona przez model,
- średnia kwadratów wyjaśniona przez model,
 - resztowa średnia kwadratów,
- resztowa średnia kwadratów,
 ,
,  - odpowiednie stopnie swobody.
- odpowiednie stopnie swobody.
Statystyka ta podlega rozkładowi F Snedecora z  i
i  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Przykład c.d. (plik wydawca.pqs)
Więcej informacji o zmiennych w modelu
- Standaryzowane
 - w odróżnieniu od parametrów surowych (które w zależności od opisywanej zmiennej są wyrażone w różnych jednostkach miary i nie mogą być bezpośrednio porównywane) standaryzowane oceny parametrów modelu pozwalają porównywać wkład poszczególnych zmiennych w wyjaśnienie zmienności zmiennej zależnej .
- w odróżnieniu od parametrów surowych (które w zależności od opisywanej zmiennej są wyrażone w różnych jednostkach miary i nie mogą być bezpośrednio porównywane) standaryzowane oceny parametrów modelu pozwalają porównywać wkład poszczególnych zmiennych w wyjaśnienie zmienności zmiennej zależnej .
- Macierz korelacji - zawiera informacje o sile związku pomiędzy poszczególnymi zmiennymi, czyli współczynnik korelacji Pearsona
 . Współczynnikiem tym badamy korelację dla każdej pary zmiennych, nie uwzględniając wpływu pozostałych zmiennych w modelu.
. Współczynnikiem tym badamy korelację dla każdej pary zmiennych, nie uwzględniając wpływu pozostałych zmiennych w modelu.
- Macierz kowariancji - podobnie jak macierz korelacji, zawiera informacje o związku liniowym pomiędzy poszczególnymi zmiennymi. Przy czym wartość ta nie jest wystandaryzowana.
- Współczynnik korelacji cząstkowej - należy do przedziału
 i jest miarą korelacji pomiędzy konkretną zmienną niezależną
i jest miarą korelacji pomiędzy konkretną zmienną niezależną  (uwzględniając jej skorelowanie z pozostałymi zmiennymi w modelu) a zmienną zależną (uwzględniając jej skorelowanie z pozostałymi zmiennymi w modelu).
(uwzględniając jej skorelowanie z pozostałymi zmiennymi w modelu) a zmienną zależną (uwzględniając jej skorelowanie z pozostałymi zmiennymi w modelu).
Kwadrat tego współczynnika to współczynnik determinacji cząstkowej - należy do przedziału i oznacza stosunek wyłącznej zmienności danej zmiennej niezależnej do tej zmienności zmiennej zależnej , która nie została wyjaśniona przez pozostałe zmienne w modelu.
Im wartość tych współczynników znajduje się bliżej 0, tym bardziej bezużyteczną informację niesie badana zmienna, czyli jest ona nadmiarowa.
- Współczynnik korelacji semicząstkowej - należy do przedziału i jest miarą korelacji pomiędzy konkretną zmienną niezależną (uwzględniając jej skorelowanie z pozostałymi zmiennymi w modelu) a zmienną zależną (NIE uwzględniając jej skorelowanie z pozostałymi zmiennymi w modelu).
Kwadrat tego współczynnika to współczynnik determinacji semicząstkowej - należy do przedziału i oznacza stosunek wyłącznej zmienności danej zmiennej niezależnej do całkowitej zmienności zmiennej zależnej .
Im wartość tych współczynników znajduje się bliżej zera, tym bardziej bezużyteczną informację niesie badana zmienna, czyli jest ona nadmiarowa.
- R-kwadrat (
 ) - wyraża on procent zmienności danej zmiennej niezależnej tłumaczony przez pozostałe zmienne niezależne. Im bliżej wartości 1 tym silniej badana zmienna związana jest liniowo z pozostałymi zmiennymi niezależnymi, co może oznaczać, że jest ona zmienną nadmiarową.
) - wyraża on procent zmienności danej zmiennej niezależnej tłumaczony przez pozostałe zmienne niezależne. Im bliżej wartości 1 tym silniej badana zmienna związana jest liniowo z pozostałymi zmiennymi niezależnymi, co może oznaczać, że jest ona zmienną nadmiarową.
- współczynnik inflacji wariancji (
 ) - określa jak bardzo wariancja szacowanego współczynnika regresji jest zwiększona z powodu współliniowości. Im bliżej wartości 1, tym mniejsza współliniowość i tym mniejszy jej wpływ na wariancję współczynnika. Przyjmuje się, że silna współliniowość występuje, gdy współczynnik VIF>5 2). Jeśli współczynnik inflacji wariancji wynosi 5 (
) - określa jak bardzo wariancja szacowanego współczynnika regresji jest zwiększona z powodu współliniowości. Im bliżej wartości 1, tym mniejsza współliniowość i tym mniejszy jej wpływ na wariancję współczynnika. Przyjmuje się, że silna współliniowość występuje, gdy współczynnik VIF>5 2). Jeśli współczynnik inflacji wariancji wynosi 5 ( = 2.2), oznacza to, że błąd standardowy dla współczynnika tej zmiennej jest 2.2 razy większy niż w przypadku, gdyby ta zmienna miała zerową korelację z innymi zmiennymi .
= 2.2), oznacza to, że błąd standardowy dla współczynnika tej zmiennej jest 2.2 razy większy niż w przypadku, gdyby ta zmienna miała zerową korelację z innymi zmiennymi .
- Tolerancja =
 - wyraża on procent zmienności danej zmiennej niezależnej NIE tłumaczony przez pozostałe zmienne niezależne. Im wartość tolerancji jest bliższa 0 tym silniej badana zmienna związana jest liniowo z pozostałymi zmiennymi niezależnymi, co może oznaczać, że jest ona zmienną nadmiarową.
- wyraża on procent zmienności danej zmiennej niezależnej NIE tłumaczony przez pozostałe zmienne niezależne. Im wartość tolerancji jest bliższa 0 tym silniej badana zmienna związana jest liniowo z pozostałymi zmiennymi niezależnymi, co może oznaczać, że jest ona zmienną nadmiarową.
- Porównanie modelu pełnego z modelem po usunięciu danej zmiennej
Porównanie tych dwóch modeli dokonujemy:
- testem F, w sytuacji gdy z modelu usuwamy jedną zmienną lub wiecej niż jedną zmienną (patrz porównywanie modeli),
- testem t-Studenta, gdy z modelu usuwamy tylko jedną zmienną. Jest to ten sam test, którym badamy istotność poszczególnych zmiennych w modelu.
W przypadku usunięcia tylko jednej zmiennej wyniki obu tych testów są tożsame.
Jeśli różnica pomiędzy porównywanymi modelami jest istotna statystycznie (wartość  ), wówczas model pełny jest istotnie lepszy niż model zredukowany. To oznacza, że badana zmienna nie jest nadmiarowa, wywiera ona istotny wpływ na dany model i nie powinna być z niego usuwana.
), wówczas model pełny jest istotnie lepszy niż model zredukowany. To oznacza, że badana zmienna nie jest nadmiarowa, wywiera ona istotny wpływ na dany model i nie powinna być z niego usuwana.
- Wykresy rozrzutu
Wykresy te pozwalają dokonać subiektywnej oceny liniowości związku pomiędzy zmiennymi i zidentyfikować punkty odstające. Dodatkowo wykresami rozrzutu możemy posłużyć się w analizie reszt modelu.
Analiza reszt modelu
By otrzymać poprawny model regresji, powinniśmy sprawdzić podstawowe założenia dotyczące reszt modelu.
- Obserwacje odstające
Badając reszty modelu szybko można uzyskać wiedzę na temat wartości odstających. Obserwacje takie mogą bardzo zaburzyć równanie regresji, ponieważ mają duży wpływ na wartości współczynników tego równania. Jeśli dana reszta jest oddalona o więcej niż 3 odchylenia standardowe od wartości średniej, wówczas obserwacje taką można uznać za obserwacje odstającą. Usunięcie obserwacji odstającej może w znaczącym stopniu przyczynić się do poprawy modelu.
Odległość Cooka - opisuje wielkość zmian współczynników regresji powstałą na skutek pominięcia danego przypadku. W programie zaznaczone pogrubioną czcionką są odległości Cooka dla przypadków, które przekraczają 50 percentyl statystyki rozkładu Fishera-Snedecora F(0.5, k+1, n−k−1).
Odległość Mahalanobisa - dedykowana jest do wykrywania obserwacji odstających - wysokie wartości świadczą o znacznym oddaleniu danego przypadku od centrum zmiennych niezależnych. Jeśli wśród przypadków oddalonych o więcej niż 3 odchylenia znajdzie się przypadek o największej wartości Mahalanobisa, wówczas jako najbardziej odstający zostanie on zaznaczony pogrubioną czcionką.
- Normalność rozkładu reszt modelu
Założenie to sprawdzamy wizualnie przy pomocy wykresu Q-Q rozkładu nromalnego. Duża różnica między rozkładem reszt a rozkładem normalnym może zaburzać ocenę istotności współczynników poszczególnych zmiennych modelu..
- Homoskedastyczność (stałość wariancji)
By sprawdzić czy istnieją obszary, gdzie wariancja reszt modelu jest zwiększona lub zmniejszona posługujemy się wykresami:
- reszty względem wartości przewidywanych
- kwadrat reszty względem wartości przewidywanych
- reszty względem wartości obserwowanych
- kwadrat reszty względem wartości obserwowanych
- Autokorelacja reszt modelu
Aby zbudowany model można było uznać za poprawny, wartości reszt nie powinny być ze sobą skorelowane (dla wszystkich par  ). Założenie to możemy sprawdzić wyliczając statystykę testu Durbina-Watsona
). Założenie to możemy sprawdzić wyliczając statystykę testu Durbina-Watsona

Aby sprawdzić dodatnią autokorelację na poziomie istotności , sprawdzamy położenie statystyki  w stosunku do górnej (
w stosunku do górnej ( ) i dolnej (
) i dolnej ( ) wartości krytycznej:
) wartości krytycznej:
- Jeżeli
 - błędy są dodatnio skorelowane;
- błędy są dodatnio skorelowane; - Jeśli
 - błędy nie są dodatnio skorelowane;
- błędy nie są dodatnio skorelowane; - Jeśli
 - wynik testu jest niejednoznaczny.
- wynik testu jest niejednoznaczny.
Aby sprawdzić ujemną autokorelację na poziomie istotności , sprawdzamy położenie wartości  w stosunku do górnej () i dolnej () wartości krytycznej:
w stosunku do górnej () i dolnej () wartości krytycznej:
- Jeżeli
 - błędy są ujemnie skorelowane;
- błędy są ujemnie skorelowane; - Jeśli
 - błędy nie są ujemnie skorelowane;
- błędy nie są ujemnie skorelowane; - Jeśli
 - wynik testu jest niejednoznaczny.
- wynik testu jest niejednoznaczny.
Wartości krytyczne testu Durbina-Watsona dla poziomu istotności  znajdują się na stronie internetowej (pqstat) - źródło tablic: Savina i White (1977)3)
znajdują się na stronie internetowej (pqstat) - źródło tablic: Savina i White (1977)3)
Przykład c.d. (plik wydawca.pqs)
Przykład dla regresji wielorakiej
Pewien wydawca książek chciał się dowiedzieć, jaki wpływ na zysk brutto ze sprzedaży mają takie zmienne jak: koszty produkcji, koszty reklamy, koszty promocji bezpośredniej, suma udzielonych rabatów, popularność autora. W tym celu przeanalizował 40 pozycji wydanych w ciągu ostatniego roku (zbiór uczący). Fragment danych przedstawia poniższy rysunek:
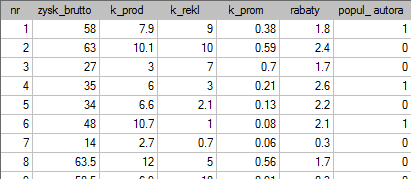
Pięć pierwszych zmiennych wyrażonych jest w tysiącach dolarów - są to więc zmienne zebrane na skali interwałowej. Natomiast ostatnia zmienna: popularność autora  to zmienna dychotomiczna, gdzie 1 oznacza autora znanego, 0 oznacza autora nieznanego.
to zmienna dychotomiczna, gdzie 1 oznacza autora znanego, 0 oznacza autora nieznanego.
Na podstawie uzyskanej wiedzy wydawca planuje przewidzieć zysk brutto z kolejnej wydawanej książki znanego autora. Koszty, jakie zamierza ponieść to: koszty produkcji  , koszty reklamy
, koszty reklamy  , koszty promocji bezpośredniej
, koszty promocji bezpośredniej  , suma udzielonych rabatów .
, suma udzielonych rabatów .
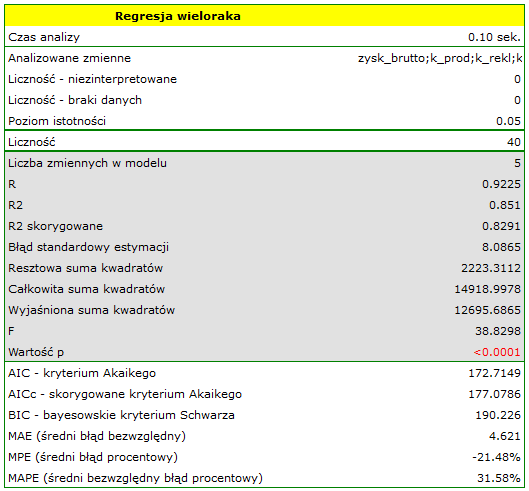
Budujemy model liniowej regresji wielorakiej dla zbioru uczącego wybierając: zysk brutto jako zmienną zależną , koszty produkcji, koszty reklamy, koszty promocji bezpośredniej, suma udzielonych rabatów, popularność autora jako zmienne niezależne  . W rezultacie wyliczone zostaną współczynniki równania regresji oraz miary pozwalające ocenić jakość modelu.
. W rezultacie wyliczone zostaną współczynniki równania regresji oraz miary pozwalające ocenić jakość modelu.
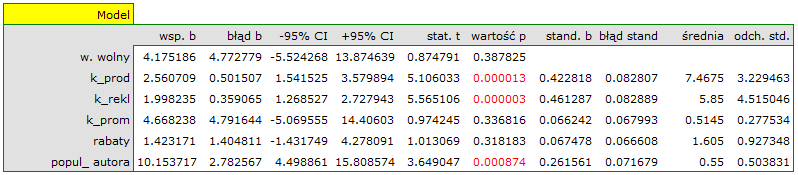
Na podstawie oszacowanej wartości współczynnika  , związek pomiędzy zyskiem brutto a wszystkimi zmiennymi niezależnymi możemy opisać równaniem:
, związek pomiędzy zyskiem brutto a wszystkimi zmiennymi niezależnymi możemy opisać równaniem:
![\begin{displaymath}
zysk_{brutto}=4.18+2.56(k_{prod})+2(k_{rekl})+4.67(k_{prom})+1.42(rabaty)+10.15(popul_{autora})+[8.09]
\end{displaymath}](/lib/exe/fetch.php?media=wiki:latex:/imgf922fff467cfbd2ba68883ee92814649.png "LaTeX") Uzyskane współczynniki interpretujemy następująco:
Uzyskane współczynniki interpretujemy następująco:
- Jeśli koszt produkcji wzrośnie o 1 tysiąc dolarów, to zysk brutto wzrośnie o około 2.56 tysiące dolarów, przy złożeniu, że pozostałe zmienne się nie zmienią;
- Jeśli koszt reklamy wzrośnie o 1 tysiąc dolarów, to zysk brutto wzrośnie o około 2 tysiące dolarów, przy złożeniu, że pozostałe zmienne się nie zmienią;
- Jeśli koszt promocji bezpośredniej wzrośnie o 1 tysiąc dolarów, to zysk brutto wzrośnie o około 4.67 tysiące dolarów, przy złożeniu, że pozostałe zmienne się nie zmienią;
- Jeśli suma udzielonych rabatów wzrośnie o 1 tysiąc dolarów, to zysk brutto wzrośnie o około 1.42 tysiące dolarów, przy złożeniu, że pozostałe zmienne się nie zmienią;
- Jeśli książka została napisana przez autora znanego (oznaczonego przez 1), to w modelu popularność autora przyjmujemy jako wartość 1 i otrzymujemy równanie:
 Jeśli natomiast książka została napisana przez autora nieznanego (oznaczonego przez 0), to w modelu popularność autora przyjmujemy jako wartość 0 i otrzymujemy równanie:
Jeśli natomiast książka została napisana przez autora nieznanego (oznaczonego przez 0), to w modelu popularność autora przyjmujemy jako wartość 0 i otrzymujemy równanie:
 Wynik testu t-Studenta uzyskany dla każdej zmiennej wskazuje, że tylko koszt produkcji, koszt reklamy oraz popularność autora wywiera istotny wpływ na otrzymany zysk. Jednocześnie, dla tych zmiennych standaryzowane współczynniki są największe.
Wynik testu t-Studenta uzyskany dla każdej zmiennej wskazuje, że tylko koszt produkcji, koszt reklamy oraz popularność autora wywiera istotny wpływ na otrzymany zysk. Jednocześnie, dla tych zmiennych standaryzowane współczynniki są największe.
Dodatkowo, model jest dobrze dopasowany o czym świadczy: mały błąd standardowy estymacji  , wysoka wartość współczynnika determinacji wielorakiej
, wysoka wartość współczynnika determinacji wielorakiej  i poprawionego współczynnika determinacji wielorakiej
i poprawionego współczynnika determinacji wielorakiej  oraz wynik testu F analizy wariancji:
oraz wynik testu F analizy wariancji:  .
.
Na podstawie interpretacji dotychczasowych wyników możemy przypuszczać, że część zmiennych nie wywiera istotnego wpływu na zysk i może być zbyteczna. Aby model był dobrze sformułowany interwałowe zmienne niezależne powinny być silnie skorelowane ze zmienną zależną i stosunkowo słabo pomiędzy sobą. Możemy to sprawdzić wyliczając macierz korelacji i macierz kowariancji:
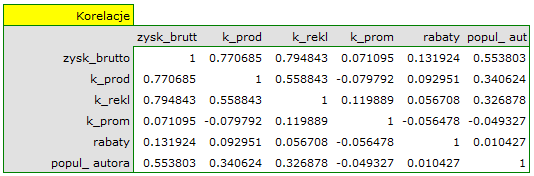
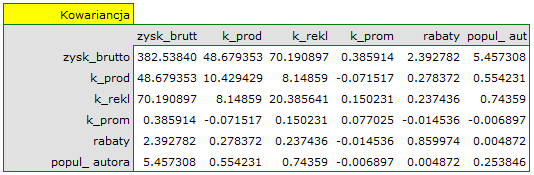
Najbardziej spójną informację, pozwalającą znaleźć te zmienne w modelu, które są zbędne (nadmiarowe) niesie analiza korelacji cząstkowej i semicząstkowej i nadmiarowości:
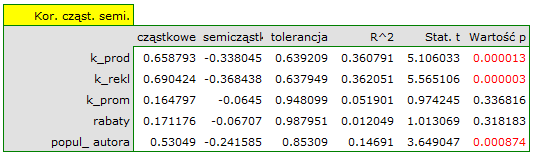
Wartości współczynników korelacji cząstkowej i semicząstkowej wskazują, że najmniejszy wkład w budowany model mają: koszt promocji bezpośredniej i suma udzielonych rabatów. Jednak, są to zmienne najmniej skorelowane z pozostałymi w modelu, o czym świadczy niska wartość i wysoka wartość tolerancji. Ostatecznie, ze statystycznego punktu widzenia, modele bez tych zmiennych nie były by modelami gorszymi niż model obecny (patrz wynik testu t-Studenta dla porównywania modeli). To od decyzji badacza zależy, czy pozostawi ten model, czy zbuduje nowy model pozbawiony kosztów promocji bezpośredniej i sumy udzielonych rabatów. My pozostawiamy model obecny.
Na koniec przeprowadzimy analizę reszt. Fragment tej analizy znajduje się poniżej:
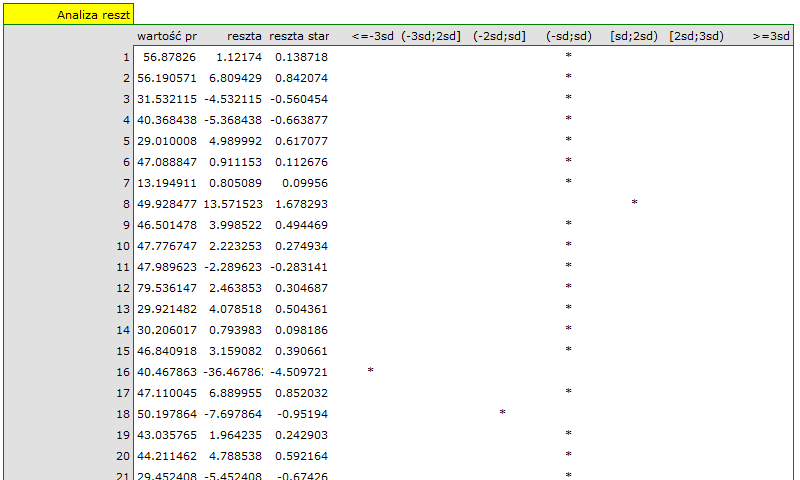
Możemy zauważyć, że jedna z reszt modelu jest obserwacją odstającą jest oddalona o więcej niż 3 odchylenia standardowe od wartości średniej. Jest to obserwacja o numerze 16. Obserwację te możemy łatwo znaleźć kreśląc wykres resz względem obserwowanych lub przewidywanych wartości zmiennej .
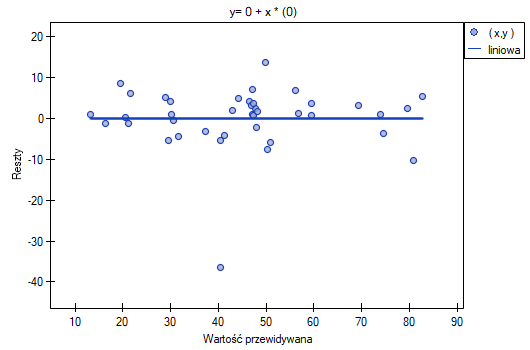
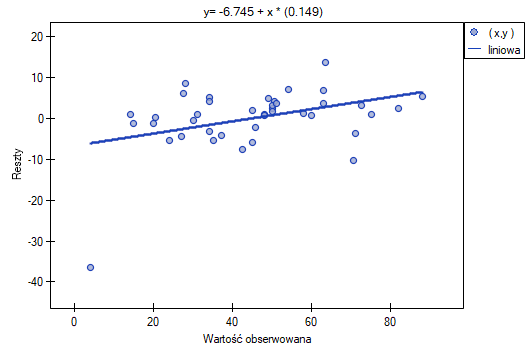
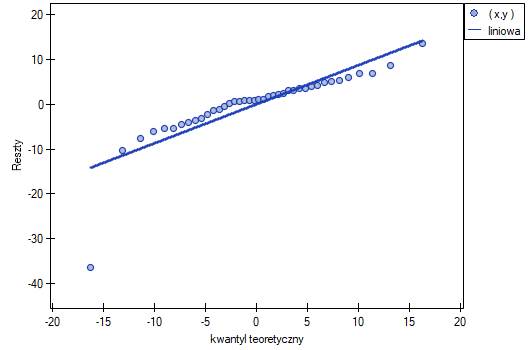
Ten odstający punkt zaburza założenie dotyczące homoskedastyczności. Założenie homoskedastyczności było by spełnione (tzn. wariancja reszt opisana na osi byłaby podobna, gdy przechodzimy wzdłuż osi  ), gdybyśmy ten punkt odrzucili. Dodatkowo, rozkład reszt nieco odbiega od rozkładu normalnego (wartość testu Lilieforsa wynosi
), gdybyśmy ten punkt odrzucili. Dodatkowo, rozkład reszt nieco odbiega od rozkładu normalnego (wartość testu Lilieforsa wynosi  ):
):

Przyglądając się dokładniej punktowi odstającemu (pozycja 16 w danych do zadania) widzimy, że książka ta jako jedyna wykazuje wyższe koszty niż zysk brutto (zysk brutto = 4 tysiące dolarów, suma kosztów = (8+6+0.33+1.6) = 15.93 tysiące dolarów).
Uzyskany model możemy poprawić usuwając z niego punkt odstający. Wymaga to ponownego przeprowadzenia analizy z włączonym filtrem wykluczającym punkt odstający.
W rezultacie uzyskaliśmy bardzo podobny model, ale obarczony mniejszym błędem i lepiej dopasowany:
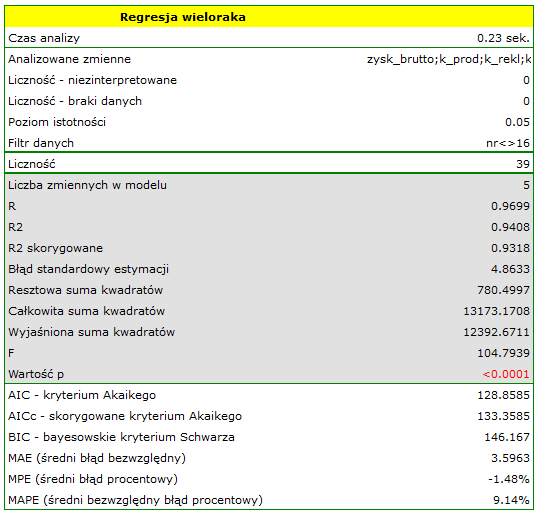
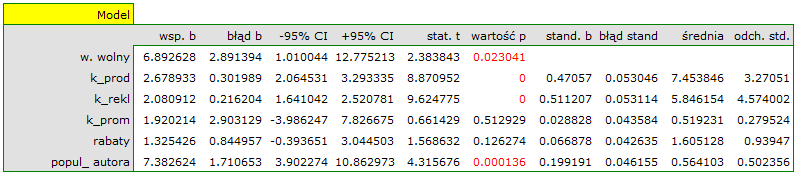
![\begin{displaymath}
zysk_{brutto}=6.89+2.68(k_{prod})+2.08(k_{rekl})+1.92(k_{prom})+1.33(rabaty)+7.38(popul_{autora})+[4.86]
\end{displaymath}](/lib/exe/fetch.php?media=wiki:latex:/img56f860f403564778be635c59de60dd63.png "LaTeX") Ostatecznie zbudowany model wykorzystamy do predykcji. Na podstawie przewidywanych nakładów w wysokości:
koszty produkcji tysięcy dolarów,
koszty reklamy tysięcy dolarów,
koszty promocji bezpośredniej tysiąca dolarów,
suma udzielonych rabatów tysiąca dolarów,\\oraz faktu, że jest to autor znany (popularność autora
Ostatecznie zbudowany model wykorzystamy do predykcji. Na podstawie przewidywanych nakładów w wysokości:
koszty produkcji tysięcy dolarów,
koszty reklamy tysięcy dolarów,
koszty promocji bezpośredniej tysiąca dolarów,
suma udzielonych rabatów tysiąca dolarów,\\oraz faktu, że jest to autor znany (popularność autora  ) wyliczamy przewidywany zysk brutto wraz z przedziałem ufności:
) wyliczamy przewidywany zysk brutto wraz z przedziałem ufności:
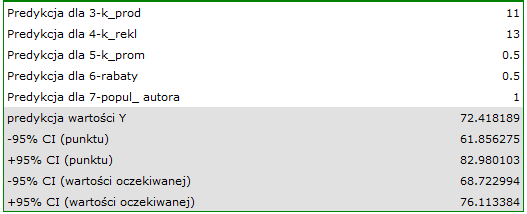
Przewidziany zysk wynosi 72 tysiące dolarów.
Na koniec należy jeszcze zauważyć, że jest to tylko model wstępny. W badaniu właściwym należałoby zebrać więcej danych. Liczba zmiennych w modelu jest bowiem zbyt mała w stosunku do liczby ocenianych książek tzn. n<50+8k
Predykcja na podstawie modelu i walidacja zbioru testowego
Walidacja
Walidacja modelu to sprawdzenie jego jakości. W pierwszej kolejności wykonywana jest na danych, na których model był zbudowany (tzw. zbiór uczący), czyli zwracana jest w raporcie opisującym uzyskany model. By można było z większą pewnością osądzić na ile model nadaje się do prognozy nowych danych, ważnym elementem walidacji jest zostanie modelu do danych, które nie były wykorzystywane w estymacji modelu. Jeśli podsumowanie w oparciu o dane uczące będzie satysfakcjonujące tzn. wyznaczane błędy, współczynniki i kryteria informacyjne będą na zadowalającym nas poziomie, a podsumowanie w oparciu o nowe dane (tzw. zbiór testowy) będzie równie korzystne, wówczas z dużym prawdopodobieństwem można uznać, że taki model nadaje się do predykcji. Dane testujące powinny pochodzić z tej samej populacji, z której były wybrane dane uczące. Często jest tak, że przed przystąpieniem do budowy modelu zbieramy dane, a następnie w sposób losowy dzielimy je na zbiór uczący, czyli dane które posłużą do budowy modelu i zbiór testowy, czyli dane które posłużą do dodatkowej walidacji modelu.
Okno z ustawieniami opcji walidacji wywołujemy poprzez menu Statystyki zaawansowane→Modele wielowymiarowe→Regresja wieloraka - predykcja/walidacja.
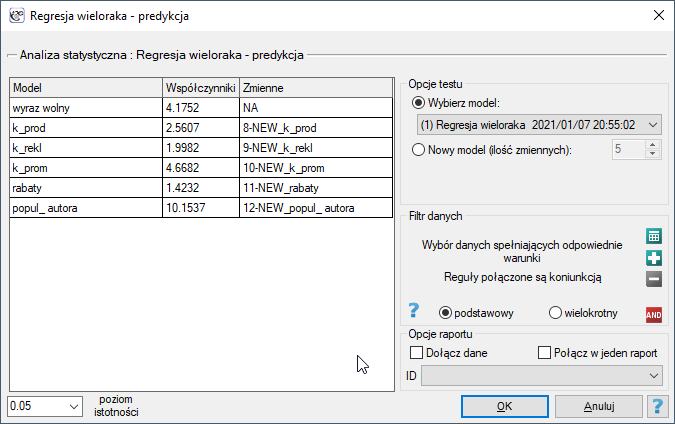
By dokonać walidacji należy wskazać model, na podstawie którego chcemy jej dokonać. Walidacji możemy dokonać na bazie:
- zbudowanego w PQStat modelu regresji wielorakiej - wystarczy wybrać model spośród modeli przypisanych do danego arkusza, a liczba zmiennych i współczynniki modelu zostaną ustawione automatycznie; zbiór testowy powinien się znaleźć w tym samym arkuszu co zbiór uczący;
- modelu niezbudowanego w programie PQStat ale uzyskanego z innego źródła (np. opisanego w przeczytanej przez nas pracy naukowej) - w oknie analizy należy podać liczbę zmiennych oraz wpisać współczynniki dotyczące każdej z nich.
W oknie analizy należy wskazać te nowe zmienne, które powinny zostać wykorzystane do walidacji.
Predykcja
Najczęściej ostatnim etapem analizy regresji jest wykorzystanie zbudowanego i uprzednio zweryfikowanego modelu do predykcji.
- Predykcja dla jednego obiektu może być wykonywana wraz z budową modelu, czyli w oknie analizy
Statystyki zaawansowane→Modele wielowymiarowe→Regresja wieloraka, - Predykcja dla większej grupy nowych danych jest wykonywana poprzez menu
Statystyki zaawansowane→Modele wielowymiarowe→Regresja wieloraka - predykcja/walidacja.
By dokonać predykcji należy wskazać model, na podstawie którego chcemy jej dokonać. Predykcji możemy dokonać na bazie:
- zbudowanego w PQStat modelu regresji wielorakiej - wystarczy wybrać model spośród modeli przypisanych do danego arkusza, a liczba zmiennych i współczynniki modelu zostaną ustawione automatycznie; zbiór testowy powinien się znaleźć w tym samym arkuszu co zbiór uczący;
- modelu niezbudowanego w programie PQStat ale uzyskanego z innego źródła (np. opisanego w przeczytanej przez nas pracy naukowej) - w oknie analizy należy podać liczbę zmiennych oraz wpisać współczynniki dotyczące każdej z nich.
W oknie analizy należy wskazać te nowe zmienne, które powinny zostać wykorzystane do predykcji. Oszacowana wartość wyliczana jest z pewnym błędem. Dlatego też dodatkowo dla przewidzianej przez model wartości wyznaczane są granice wynikające z błędu:
- dla wartości oczekiwanej wyznaczane są granice ufności,
- dla pojedynczego punktu wyznaczane są granice predykcji.
Przykład c.d. (plik wydawca.pqs)
Do przewidywania zysku brutto ze sprzedaży książek wydawca zbudował model regresji w oparciu o zbiór uczący pozbawiony pozycji 16 (czyli 39 książek). W modelu znalazły się: koszty produkcji, koszty reklamy i popularność autora (1=autor popularny, 0=nie). Zbudujemy raz jeszcze ten model w oparciu zbiór uczący a następnie, by się upewnić, że model będzie działał poprawnie, zwalidujemy go na testowym zbierze danych. Jeśli model przejdzie tę próbę, to będziemy go stosować do predykcji dla pozycji książkowych. By korzystać z odpowiednich zbiorów ustawiamy każdorazowo filtr danych.
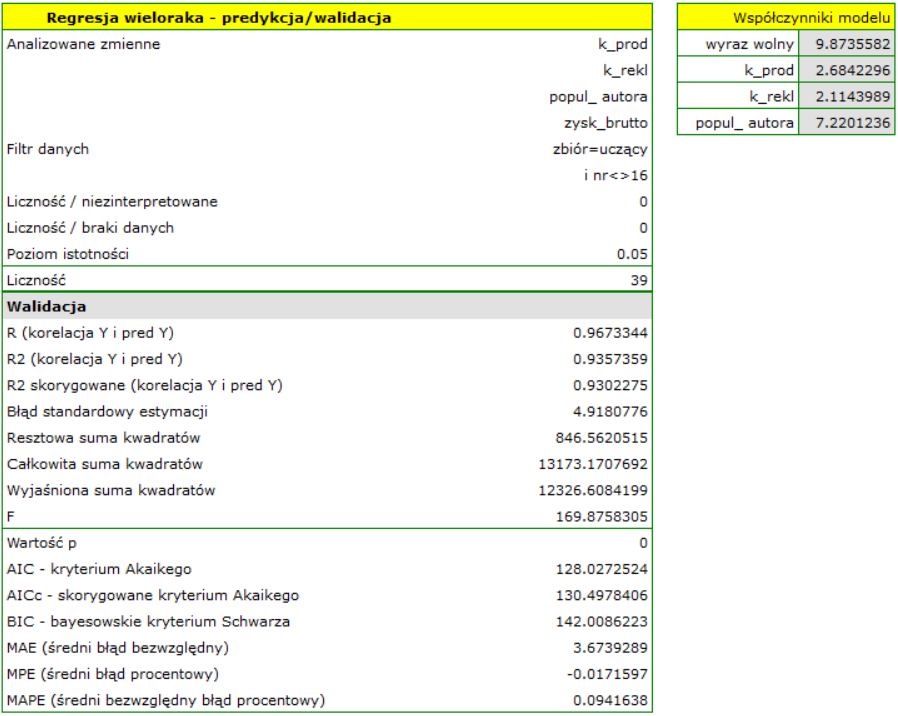
Dla zbioru uczącego wartości opisujące jakość dopasowania modelu są bardzo wysokie: skorygowane = 0.93 a średni błąd prognozy (MAE) wynosi 3.8 tys. dolarów.
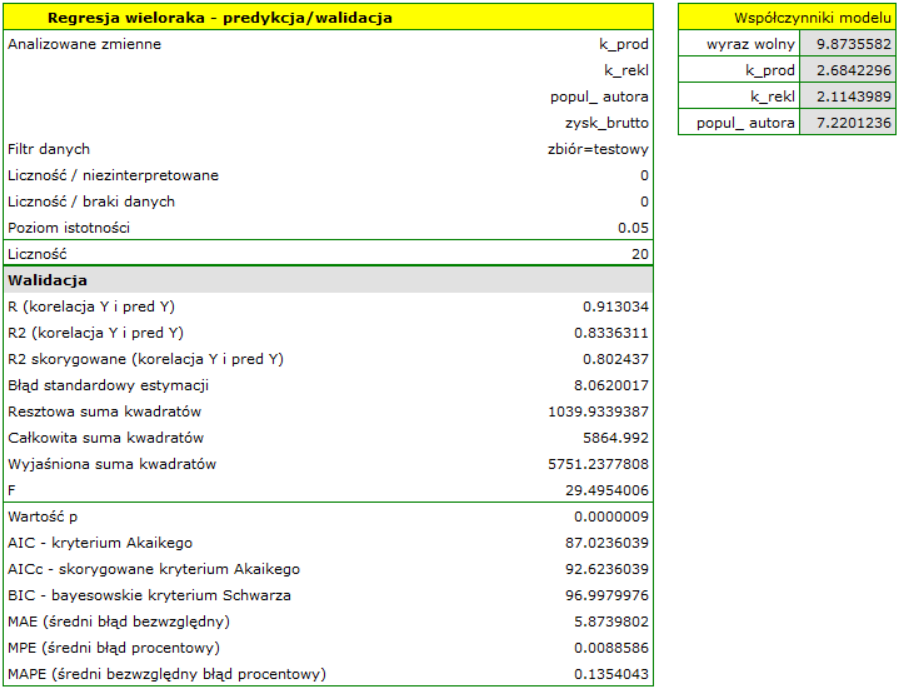
Dla zbioru testowego wartości opisujące jakość dopasowania modelu są nieco niższe niż dla zbioru uczącego: Skorygowane = 0.80 a średni błąd prognozy (MAE) wynosi 5.9 tys. dolarów. Ponieważ wynik walidacji na zbiorze testowym jest prawie tak dobry jak na zbiorze uczącym, użyjemy modelu do predykcji. W tym celu skorzystamy z danych trzech nowych pozycji książkowych dopisanych na końcu zbioru. Wybierzemy opcję Predykcja, ustawiany filtr na nowy zbiór danych i użyjemy naszego modelu do tego by przewidzieć zysk brutto dla tych książek.
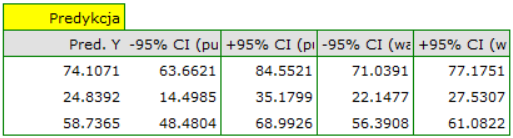
Okazuje się, że najwyższy zysk brutto (pomiędzy 64 a 85 tys. dolarów) jest prognozowany dla pierwszej, najbardziej reklamowanej i najdrożej wydanej książki popularnego autora.
1)
Green, S.B. (1991), How many subjects does it take to do a regression analysis? Multivariate Behavioral Research, 26, 499-510
2)
Sheather S. J. (2009), A modern approach to regression with R. New York, NY: Springer
3)
Savin N.E. and White K.J. (1977), The Durbin-Watson Test for Serial Correlation with Extreme Sample Sizes or Many Regressors. Econometrica 45, 1989-1996
statpqpl/wielowympl/wielorpl.txt · ostatnio zmienione: 2023/03/31 18:34 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
