Narzędzia użytkownika
Narzędzia witryny
Pasek boczny
statpqpl:porown1grpl:nparpl:proppl
Testy dla jednej proporcji

Testy dla jednej proporcji stosujemy, gdy mamy do uzyskania dwa możliwe wyniki (jeden z nich to wynik wyróżniony o liczności  ) i wiemy, jak często te wyniki pojawiają się w próbie (znamy proporcję
) i wiemy, jak często te wyniki pojawiają się w próbie (znamy proporcję  ). W zależności od wielkości próby
). W zależności od wielkości próby  mamy do wyboru test
mamy do wyboru test  dla jednej proporcji
dla jednej proporcji  dla dużych prób oraz test dokładny dwumianowy dla prób o małej liczności. Testy te służą do weryfikacji hipotezy, że proporcja w populacji z której pochodzi próba to zadana wartość.
dla dużych prób oraz test dokładny dwumianowy dla prób o małej liczności. Testy te służą do weryfikacji hipotezy, że proporcja w populacji z której pochodzi próba to zadana wartość.
Podstawowe warunki stosowania:
- pomiar na skali nominalnej - ewentualne uporządkowanie kategorii nie jest brane pod uwagę.
Dodatkowy warunek dla testu dla jednej proporcji:
 i
i  ).
).Hipotezy:

gdzie:
prawdopodobieństwo (wyróżniona proporcja) w populacji,
 prawdopodobieństwo oczekiwane (proporcja oczekiwana).
prawdopodobieństwo oczekiwane (proporcja oczekiwana).
Test dla jednej proporcji
Test dla jednej proporcji (ang. Z test for one proportion).
Statystyka testowa ma postać:
 gdzie:
gdzie:
 proporcja dla próby z tej populacji,
proporcja dla próby z tej populacji,
-liczność wartości wyszczególnionych w próbie,
- liczność próby.
Zmodyfikowana o poprawkę na ciągłość statystyka testowa ma postać:

Statystyka bez korekcji na ciągłość jak i z tą korekcją ma asymptotycznie (dla dużych liczności) rozkład normalny.
Test dwumianowy
Test dwumianowy (ang. Binominal test for one proportion) wykorzystuje w sposób bezpośredni rozkład dwumianowy zwany również rozkładem Bernoulliego, który należy do grupy rozkładów dyskretnych (czyli takich, w których badana zmienna przyjmuje skończoną liczbę wartości). Analizowana zmienna może przyjmować  wartości, pierwszą oznaczaną zwykle mianem sukcesu a drugą porażki. Prawdopodobieństwo wystąpienia sukcesu to , a porażki
wartości, pierwszą oznaczaną zwykle mianem sukcesu a drugą porażki. Prawdopodobieństwo wystąpienia sukcesu to , a porażki  .
.
Prawdopodobieństwo dla konkretnego punktu w tym rozkładzie wyliczane jest ze wzoru:
 gdzie:
gdzie:
 ,
,
- liczność wartości wyszczególnionych w próbie,
- liczność próby.
Na podstawie sumy odpowiednich prawdopodobieństw  wyznacza się wartość jednostronną i dwustronną, przy czym dwustronna wartość jest definiowana jako podwojona wartość mniejszego z jednostronnych prawdopodobieństw. Wartość porównujemy z poziomem istotności
wyznacza się wartość jednostronną i dwustronną, przy czym dwustronna wartość jest definiowana jako podwojona wartość mniejszego z jednostronnych prawdopodobieństw. Wartość porównujemy z poziomem istotności  :
:

Uwaga!
Dla estymatora z próby jakim jest w tym przypadku wartość proporcji wyznacza się przedział ufności. Dla prób o dużej liczności można bazować na przedziałach opartych o rozkład normalny - tzw. przedziały Walda. Bardziej uniwersalne są natomiast przedziały zaproponowane przez Wilsona (1927)2) a także Agresti i Coull (1998)3). Przedziały Cloppera i Pearsona (1934)4) są dokładniejsze dla prób o mniejszej liczności.
Porównanie metod budowania przedziałów dla proporcji można znaleźć w pracy Brown L.D i innych (2001)5).
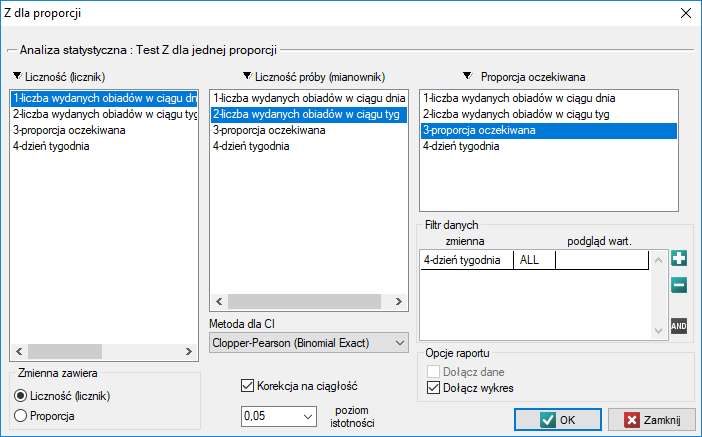
Okno z ustawieniami opcji testu Z dla jednej proporcji wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Z dla proporcji.
Przykład c.d. (plik obiady.pqs)
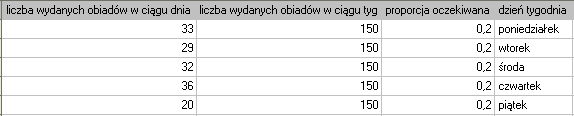
Załóżmy, że chcielibyśmy sprawdzić, czy w piątek wydawana jest  spośród wszystkich obiadów wydawanych w szkolnej stołówce w ciągu tygodnia. Dla pobranej próby
spośród wszystkich obiadów wydawanych w szkolnej stołówce w ciągu tygodnia. Dla pobranej próby  ,
,  .
.
Przy ustawianiu opcji analizy włączamy filtr wybierając odpowiedni dzień tygodnia - czyli piątek. Brak ustawienia filtru nie generuje błędu a jedynie wyliczenie kolejnych statystyk dla kolejnych dni tygodnia.
Hipotezy:

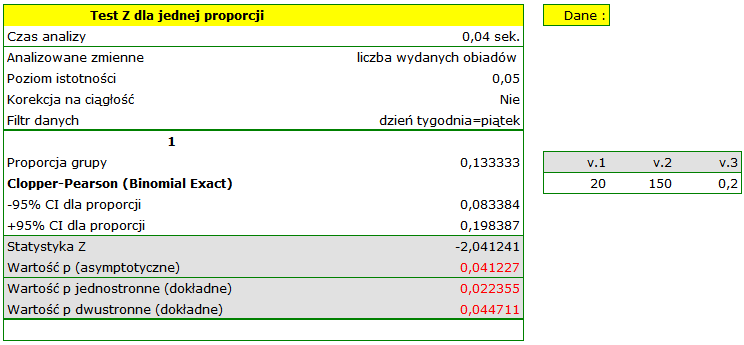
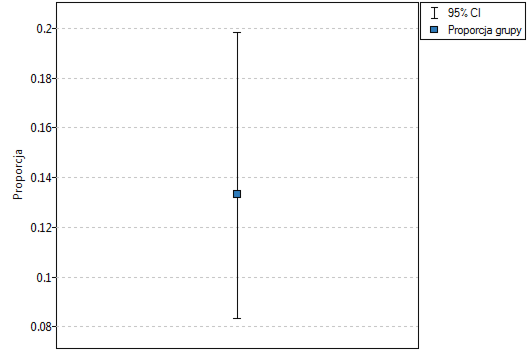
Proporcja wartości wyróżnionych w próbie to  a 95% przedział ufności Cloppera-Pearsona dla tej frakcji
a 95% przedział ufności Cloppera-Pearsona dla tej frakcji  nie zawiera hipotetycznej wartości 0.2.
nie zawiera hipotetycznej wartości 0.2.
Na podstawie testu bez poprawki na ciągłość (=0.041227) jak i na podstawie dokładnej wartości prawdopodobieństwa wyliczonego z rozkładu dwumianowego (=0.044711) moglibyśmy przyjąć (na poziomie istotności  ), że w piątek wydaje się statystycznie mniej niż obiadów wydawanych przez cały tydzień. Po zastosowaniu poprawki na ciągłość jednak nie udaje się odrzucić hipotezy zerowej (=0.052479).
), że w piątek wydaje się statystycznie mniej niż obiadów wydawanych przez cały tydzień. Po zastosowaniu poprawki na ciągłość jednak nie udaje się odrzucić hipotezy zerowej (=0.052479).
1)
Marascuilo L.A. and McSweeney M. (1977), Nonparametric and distribution-free method for the social sciences. Monterey, CA: Brooks Cole Publishing Company
2)
E.B. (1927), Probable Inference, the Law of Succession, and Statistical Inference. Journal of the American Statistical Association: 22(158):209-212
3)
Agresti A., Coull B.A. (1998), Approximate is better than „exact” for interval estimation of binomial proportions. American Statistics 52: 119-126
4)
Clopper C. and Pearson S. (1934), The use of confidence or fiducial limits illustrated in the case of the binomial. Biometrika 26: 404-413
5)
Brown L.D., Cai T.T., DasGupta A. (2001), Interval Estimation for a Binomial Proportion. Statistical Science, Vol. 16, no. 2, 101-133
statpqpl/porown1grpl/nparpl/proppl.txt · ostatnio zmienione: 2022/01/23 21:14 przez admin
Narzędzia strony
Wszystkie treści w tym wiki, którym nie przyporządkowano licencji, podlegają licencji: CC Attribution-Noncommercial-Share Alike 4.0 International
