Spis treści
Parametric tests
The Fisher-Snedecor test
The F-Snedecor test is based on a variable  which was formulated by Fisher (1924), and its distribution was described by Snedecor. This test is used to verify the hypothesis about equality of variances of an analysed variable for 2 populations.
which was formulated by Fisher (1924), and its distribution was described by Snedecor. This test is used to verify the hypothesis about equality of variances of an analysed variable for 2 populations.
Basic assumptions:
- measurement on an interval scale,
- normality of distribution of an analysed feature in both populations,
Hypotheses:

where:
 ,
,  – variances of an analysed variable of the 1st and the 2nd population.
– variances of an analysed variable of the 1st and the 2nd population.
The test statistic is defined by:

where:
 ,
,  – variances of an analysed variable of the samples chosen randomly from the 1st and the 2nd population.
– variances of an analysed variable of the samples chosen randomly from the 1st and the 2nd population.
The test statistic has the F Snedecor distribution with  and
and  degrees of freedom.
degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

The settings window with the Fisher-Snedecor test can be opened in Statistics menu→Parametric tests→F Fisher Snedecor.
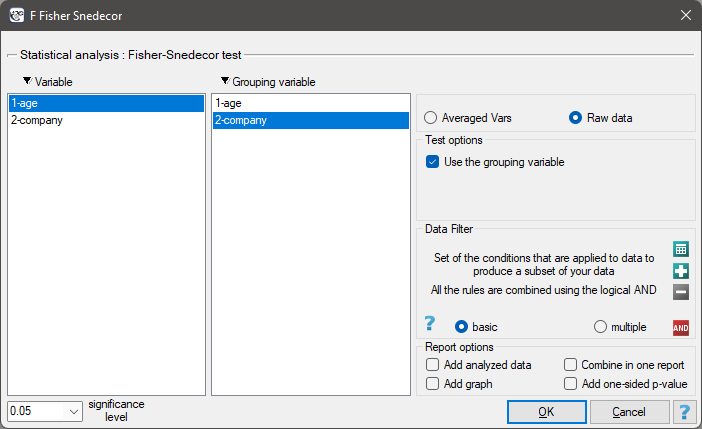
Note
Calculations can be based on raw data or data that are averaged like: arithmetic means, standard deviations and sample sizes.
The t-test for independent groups
The  -test for independent groups is used to verify the hypothesis about the equality of means of an analysed variable in 2 populations.
-test for independent groups is used to verify the hypothesis about the equality of means of an analysed variable in 2 populations.
Basic assumptions:
- measurement on an interval scale,
- normality of distribution of an analysed feature in both populations,
- equality of variances of an analysed variable in 2 populations.
Hypotheses:

where:
 ,
,  – means of an analysed variable of the 1st and the 2nd population.
– means of an analysed variable of the 1st and the 2nd population.
The test statistic is defined by:

where:
 – means of an analysed variable of the 1st and the 2nd sample,
– means of an analysed variable of the 1st and the 2nd sample,
 – the 1st and the 2nd sample size,
– the 1st and the 2nd sample size,
 – variances of an analysed variable of the 1st and the 2nd sample.
– variances of an analysed variable of the 1st and the 2nd sample.
The test statistic has the t-Student distribution with  degrees of freedom.
degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
Note:
- pooled standard deviation is defined by:

- standard error of difference of means is defined by:

Standardized effect size.
The Cohen's d determines how much of the variation occurring is the difference between the averages.
 .
.
When interpreting an effect, researchers often use general guidelines proposed by Cohen 1) defining small (0.2), medium (0.5) and large (0.8) effect sizes.
The settings window with the t- test for independent groups can be opened in Statistics menu→Parametric tests→t-test for independent groups or in ''Wizard''.
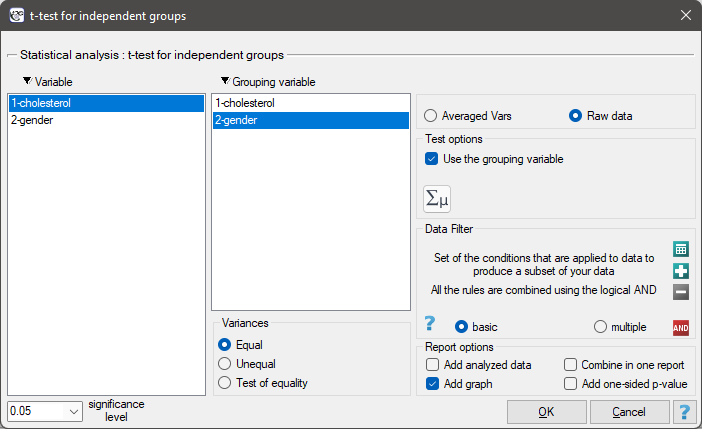
If, in the window which contains the options related to the variances, you have choosen:
equal, the t-test for independent groups will be calculated ,different, the t-test with the Cochran-Cox adjustment will be calculated,check equality, to calculate the Fisher-Snedecor test, basing on its result and set the level of significance, the t-test for independent groups with or without the Cochran-Cox adjustment will be calculated.
Note
Calculations can be based on raw data or data that are averaged like: arithmetic means, standard deviations and sample sizes.
EXAMPLE (cholesterol.pqs file)
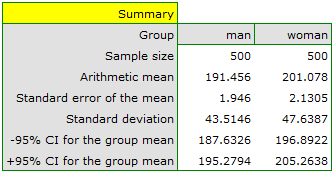
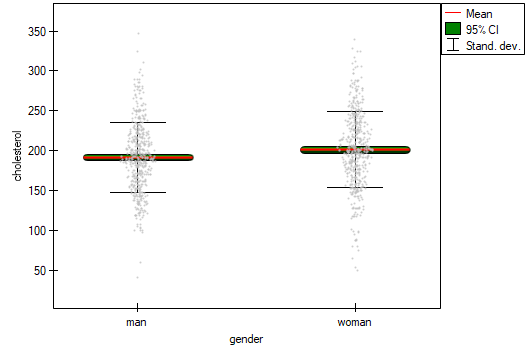
Five hundred subjects each were drawn from a population of women and a population of men over 40 years of age. The study concerned the assessment of cardiovascular disease risk. Among the parameters studied is the value of total cholesterol. The purpose of this study will be to compare men and women as to this value. We want to show that these populations differ on the level of total cholesterol and not only on the level of cholesterol broken down into its fractions.
The distribution of age in both groups is a normal distribution (this was checked with the Lilliefors test). The mean cholesterol value in the male group was  and the standard deviation
and the standard deviation  , in the female group
, in the female group  and
and  respectively. The Fisher-Snedecor test indicates small but statistically significant (
respectively. The Fisher-Snedecor test indicates small but statistically significant ( ) differences in variances. The analysis will use the Student's t-test with Cochran-Cox correction
) differences in variances. The analysis will use the Student's t-test with Cochran-Cox correction
Hypotheses:

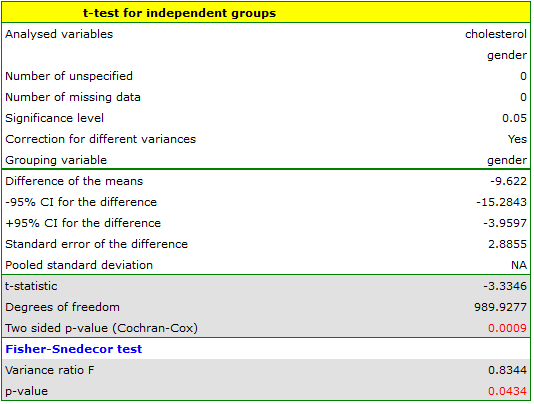
Comparing  with a significance level
with a significance level  we find that women and men in Poland have statistically significant differences in total cholesterol values. The average Polish man over the age of 40 has higher total cholesterol than the average Polish woman by almost 10 units.
we find that women and men in Poland have statistically significant differences in total cholesterol values. The average Polish man over the age of 40 has higher total cholesterol than the average Polish woman by almost 10 units.
The t-test with the Cochran-Cox adjustment
The Cochran-Cox adjustment relates to the t-test for independent groups (1957)2) and is calculated when variances of analysed variables in both populations are different.
The test statistic is defined by:

The test statistic has the t-Student distribution with degrees of freedom proposed by Satterthwaite (1946)3) and calculated using the formula:

The settings window with the t- test for independent groups can be opened in Statistics menu→Parametric tests→t-test for independent groups or in ''Wizard''.
If, in the window which contains the options related to the variances, you have choosen:
equal, the t-test for independent groups will be calculated ,different, the t-test with the Cochran-Cox adjustment will be calculated,check equality, to calculate the Fisher-Snedecor test, basing on its result and set the level of significance, the t-test for independent groups with or without the Cochran-Cox adjustment will be calculated.
Note Calculations can be based on raw data or data that are averaged like: arithmetic means, standard deviations and sample sizes.
The t-test for dependent groups
The -test for dependent groups is used when the measurement of an analysed variable you do twice, each time in different conditions (but you should assume, that variances of the variable in both measurements are pretty close to each other). We want to check how big is the difference between the pairs of measurements ( ). This difference is used to verify the hypothesis informing us that the mean of the difference in the analysed population is 0.
). This difference is used to verify the hypothesis informing us that the mean of the difference in the analysed population is 0.
Basic assumptions:
- measurement on an interval scale,
- normality of distribution of measurements
 (or the normal distribution for an analysed variable in each measurement),
(or the normal distribution for an analysed variable in each measurement),
Hypotheses:

where:
 , – mean of the differences in a population.
, – mean of the differences in a population.
The test statistic is defined by:

where:
 – mean of differences in a sample,
– mean of differences in a sample,
 – standard deviation of differences in a sample,
– standard deviation of differences in a sample,
 – number of differences in a sample.
– number of differences in a sample.
Test statistic has the t-Student distribution with  degrees of freedom.
degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level :
Note
- standard deviation of the difference is defined by:

- standard error of the mean of differences is defined by:

Standardized effect size.
The Cohen's d determines how much of the variation occurring is the difference between the averages, while taking into account the correlation of the variables.
 .
.
 ,
,
 –
– When interpreting an effect, researchers often use general guidelines proposed by Cohen 4) defining small (0.2), medium (0.5) and large (0.8) effect sizes.
The settings window with the t-test for dependent groups can be opened in Statistics menu→Parametric tests→t-test for dependent groups or in ''Wizard''.
Note
Calculations can be based on raw data or data that are averaged like: arithmetic mean of difference, standard deviation of difference and sample size.
A clinic treating eating disorders studied the effect of a recommended „diet A” on weight change. A sample of 120 obese patients were put on the diet. Their BMI levels were measured twice: before the diet and after 180 days of the diet. To test the effectiveness of the diet, the obtained BMI measurements were compared.
Hypotheses:

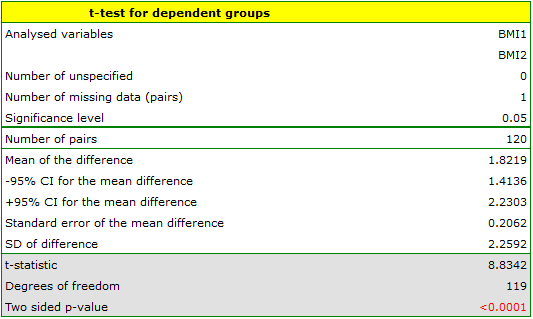
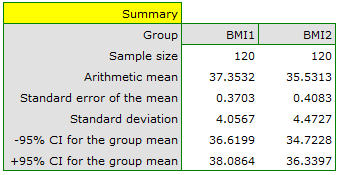
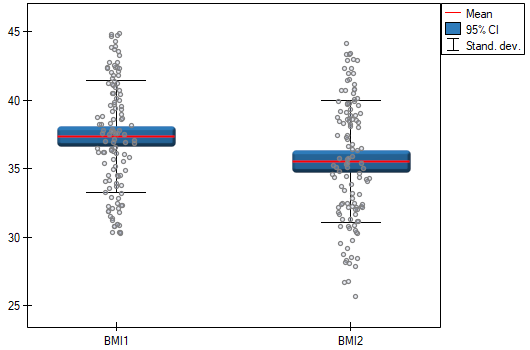
Comparing  with a significance level we find that the mean BMI level changed significantly. Before the diet, it was higher by less than 2 units on average.
with a significance level we find that the mean BMI level changed significantly. Before the diet, it was higher by less than 2 units on average.
The study was able to use the Student's t-test for dependent groups because the distribution of the difference between pairs of measurements was a normal distribution (Lilliefors test,  ).
).