One-dimensional normality tests
A variety of tests may be applicable in testing the normality of a distribution, each of which pays attention to slightly different aspects of the Gaussian distribution. It is impossible to identify a test that is good for every possible data set.
The basic condition for using tests of normality of distribution:
- measurement on the interval scale.
Test hypotheses for normality of distribution:

The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

Note
Testing for normality of distribution can be done for variables or for differences determined from two variables.
- Kolmogorov-Smirnov test for normality
The test proposed by Kolmogorov (1933)1) is a relatively conservative test (it is more difficult to prove the non-normality of the distribution using it). It is based on the determination of the distance between the empirical and theoretical normal distribution. It is recommended to use it for large samples, but it should be used when the mean ( ) and standard deviation (
) and standard deviation ( ) for the population from which the sample is drawn are known. We can then check that the distribution conforms to the distribution defined by the given mean and standard deviation.
) for the population from which the sample is drawn are known. We can then check that the distribution conforms to the distribution defined by the given mean and standard deviation.
Based on the sample data collected in the cumulative frequency distribution and the corresponding values of the area under the theoretical normal distribution curve, we determine the value of the test statistic  :
:

where:
 – empirical cumulative distribution of the normal curve computed at individual points of the distribution, for
– empirical cumulative distribution of the normal curve computed at individual points of the distribution, for  -element sample ,
-element sample ,
 – theoretical cumulative distribution of the normal curve.
– theoretical cumulative distribution of the normal curve.
Statystyka testu podlega rozkładowi Kołmogorova-Smirnova.
- Lilliefors test for normality
A test proposed by Lilliefors (1967, 1969, 1973)2), 3), 4). It is a correction of the Kolmogorov-Smirnov test when the mean () and standard deviation () are unknown for the population from which the sample is drawn. It is considered slightly less conservative than the Kolmogorov-Smirnov test.
The test statistic is determined by the same formula used by the Kolmogorov-Smirnov test, but follows a Lilliefors distribution.
- Shapiro-Wilk test for normality
Proposed by Shapiro and Wilk (1965)5) for sparse groups, and adapted for more numerous groups (up to 5000 objects) by Royston (1992)6)7). This test has a relatively high power, which makes it easier to prove the non-normality of the distribution.
The idea of how the test works is shown in the Q-Q plot.
The Shapiro-Wilk test statistic has the form:

where:
 – coefficients determined based on expected values for ordered statistics, assigned weights, and covariance matrix,
– coefficients determined based on expected values for ordered statistics, assigned weights, and covariance matrix,
 – average value of sample data.
– average value of sample data.
This statistic is transformed to a statistic with a normal distribution:

where:
 , i – depend on the sample size:
, i – depend on the sample size:
– for small sample sizes  :
:
 ,
,
 ,
,
 ,
,
 ;
;
– for large sample sizes  :
:
 ,
,
 ,
,
 ,
,
 .
.
- D'Agostino-Pearson test for normality
Different types of statistical analyses that assume normality are sensitive to different degrees to different types of departure from this assumption. Tests that refer to means in their hypotheses are assumed to be more sensitive to skewness, and tests that compare variances are assumed to depend more on kurtosis.
A normal distribution should be characterized by zero skewness and zero kurtosis g2 (or b2 close to the value three). If the distribution is not normal, as found by the D'Agostino (1973)8) test, one can check whether this is the result of high skewness or kurtosis by the skewness test and the kurtosis test.
Like the Shapiro-Wilk test, the D'Agostino test has higher power than the Kolmogorov-Smirnov test and the Lilliefors test (D'Agostino 19909)).
The test statistic is of the form:

where:
 – test statistic for the skewness,
– test statistic for the skewness,
 – test statistic for kurtosis.
– test statistic for kurtosis.
This statistic has an asymptotically Chi-square distribution with two degrees of freedom.
- D'Agostino skewness test
Hypotheses:

The test statistic has the form:

where:
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 .
.
The statistic  has asymptotically (for large suple size) a normal distribution.
has asymptotically (for large suple size) a normal distribution.
- D'Agostino kurtosis test
Hypotheses:

The test statistic has the form:

where:
 ,
,
 ,
,
 ,
,
 ,
,
 ,
,
 .
.
The statistic has asymptotically (for large suple size) a normal distribution.
A quantile-quantile type plot is used to show the correspondence of two distributions. When testing the fit of a normal distribution, it checks the fit of the data distribution (empirical distribution) to a Gaussian theoretical distribution. From it, you can visually see how well the normal distribution curve fits the data. If the quantiles of the theoretical distribution and the empirical distribution match, then the points are distributed along the line  . The horizontal axis represents the quantiles of the normal distribution, the vertical axis the quantiles of the data distribution
. The horizontal axis represents the quantiles of the normal distribution, the vertical axis the quantiles of the data distribution
Various deviations from the normal distribution are possible – the interpretation of some of the most common ones is described in the diagram:
- data spread out on the line, but a few points deviate strongly from the line
– there are outliers in the data
- points on the left side of the graph are above the line and on the right side are below the line
– the distribution is characterized by a greater presence of outliers from the mean than is the case in a normal distribution (negative kurtosis)
- points on the left side of the graph are below the line and the points on the right side are above the line
– the distribution is characterized by a smaller presence of values away from the mean than is the case in a normal distribution (positive kurtosis)
- points on the left and right sides of the graph are above the line
– right-skewed distribution (positive skewness);
- points on the left and right sides of the graph are below the line
– left-skewed distribution (negative skewness).
The window with the settings for the normality tests options is invoked via the Statistics→Normality tests→One-dimensional normality menu or via ''Wizard''.
EXAMPLE (Gauss.pqs file)
- Women's growth
Let us assume that the height of women is such a characteristic, for which the average value is 168cm. Most of the women we meet every day are of a height not significantly different from this average. Of course there are women who are completely short and also very tall, but relatively rarely. Since very low and very high values occur rarely, and average values often, we can expect that the distribution of height is normal. To find out, 300 randomly selected women were measured.
Hypotheses:

Since we do not know the mean or standard deviation for female height, but only have an assumption about these quantities, they will be determined from the sample.
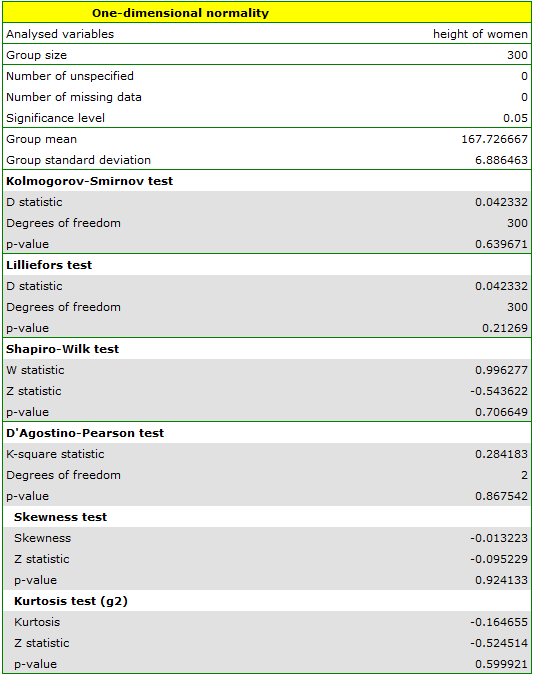
All of the designated tests indicate that there is no deviation from the normal distribution, as their  values are above the standard significance level of
values are above the standard significance level of  . Also, the test that examines skewness and kurtosis shows no deviation.
. Also, the test that examines skewness and kurtosis shows no deviation.
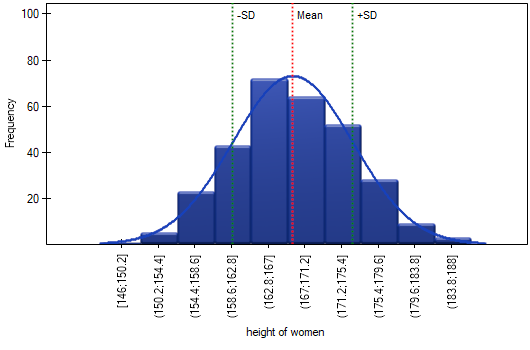
In the column chart, we presented the height distribution as 10 columns. Women between 167 cm and 171 cm are the most numerous group, while women shorter than 150 cm or taller than 184 cm are the least numerous. The bell curve of the normal distribution seems to describe this distribution well.
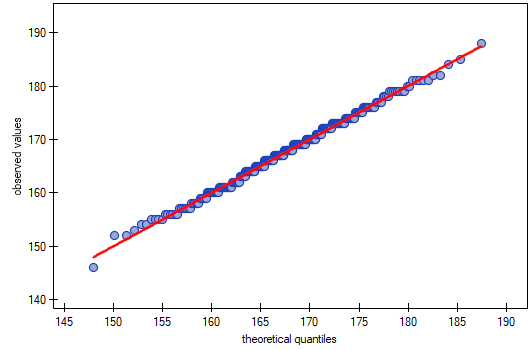
In the quantile-quantile plot, the points lie almost perfectly on the line, which also indicates a very good fit of the normal distribution.
The normal distribution can therefore be regarded as the distribution that characterizes the growth of women in the population studied.
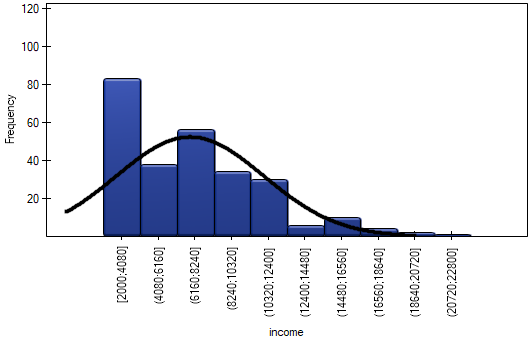
- Income
Suppose we study the income of people in a certain country. We expect that the income of most people will be average, however, there will be no people earning very little (below the minimum salary imposed by the authorities), but there will be people earning very much (company presidents), who are relatively few in number. In order to check whether the income of people in the examined country has a normal distribution, information about the income of 264 randomly selected people was collected.
Hipotezy:


The distribution is not a normal distribution, as evidenced by all test results testing the normality of the distribution ( ). A positive and statistically significant () skewness value indicates that the right tail of the function is too long. The function distribution is also more slender than the normal distribution, but this is not a statistically significant difference (kurtosis test).
). A positive and statistically significant () skewness value indicates that the right tail of the function is too long. The function distribution is also more slender than the normal distribution, but this is not a statistically significant difference (kurtosis test).
In a quartile-quartile plot, the deviation from the normal distribution is illustrated by right-hand skewness, i.e., the location of the initial and final points of the plot significantly above the line.
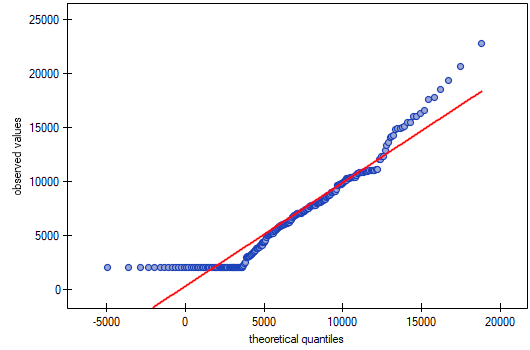
As a result, the data collected do not show that the income distribution is consistent with a normal distribution.