The t-test for a single sample
The single-sample  test is used to verify the hypothesis, that an analysed sample with the mean (
test is used to verify the hypothesis, that an analysed sample with the mean ( ) comes from a population, where mean (
) comes from a population, where mean ( ) is a given value.
) is a given value.
Basic assumptions:
- measurement on an interval scale,
- normality of distribution of an analysed feature.
Hypotheses:

where:
– mean of an analysed feature of the population represented by the sample,
 – a given value.
– a given value.
The test statistic is defined by:

where:
 – standard deviation from the sample,
– standard deviation from the sample,
 – sample size.
– sample size.
The test statistic has the t-Student distribution with  degrees of freedom.
degrees of freedom.
The p-value, designated on the basis of the test statistic, is compared with the significance level  :
:

Note
Note, that: If the sample is large and you know a standard deviation of the population, then you can calculate a test statistic using the formula:
 The statistic calculated this way has the normal distribution. If
The statistic calculated this way has the normal distribution. If  -Student distribution converges to the normal distribution
-Student distribution converges to the normal distribution  . In practice, it is assumed, that with
. In practice, it is assumed, that with  the -Student distribution may be approximated with the normal distribution.
the -Student distribution may be approximated with the normal distribution.
Standardized effect size.
The Cohen's d determines how much of the variation occurring is the difference between the averages.
 .
.
When interpreting an effect, researchers often use general guidelines proposed by Cohen 1) defining small (0.2), medium (0.5) and large (0.8) effect sizes.
The settings window with the Single-sample <latex>$t$</latex>-test can be opened in Statistics menu→Parametric tests→t-test or in ''Wizard''.
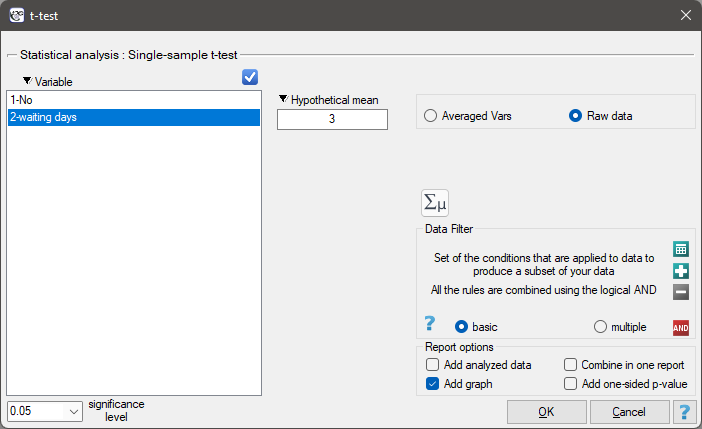
Note
Calculations can be based on raw data or data that are averaged like: arithmetic mean, standard deviation and sample size.
You want to check if the time of awaiting for a delivery by some courier company is 3 days on the average  . In order to calculate it, there are 22 persons chosen by chance from all clients of the company as a sample. After that, there are written information about the number of days passed since the delivery was sent till it is delivered. There are following values: (1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 4, 4, 5, 5, 6, 6, 6, 7, 7).
. In order to calculate it, there are 22 persons chosen by chance from all clients of the company as a sample. After that, there are written information about the number of days passed since the delivery was sent till it is delivered. There are following values: (1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 4, 4, 5, 5, 6, 6, 6, 7, 7).
The number of awaiting days for the delivery in the analysed population fulfills the assumption of normality of distribution.
Hypotheses:

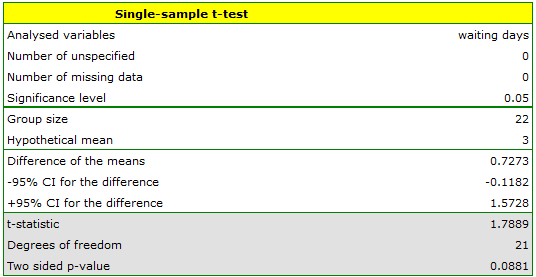

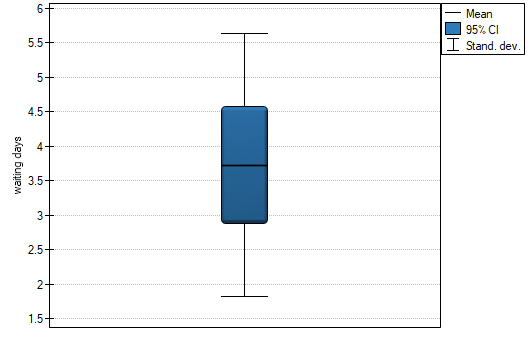
Comparing the  value = 0.0881 of the -test with the significance level
value = 0.0881 of the -test with the significance level  we draw the conclusion, that there is no reason to reject the null hypothesis which informs that the average time of awaiting for the delivery, which is supposed to be delivered by the analysed courier company is 3. For the tested sample, the mean is
we draw the conclusion, that there is no reason to reject the null hypothesis which informs that the average time of awaiting for the delivery, which is supposed to be delivered by the analysed courier company is 3. For the tested sample, the mean is  and the standard deviation is
and the standard deviation is  .
.