Spis treści
Porównanie - 2 grupy
{\ovalnode{A}{\hyperlink{rozklad_normalny}{\begin{tabular}{c}Czy rozkład\\zmiennych jest\\rozkładem\\normalnym?\end{tabular}}}}
\rput[tl](0.15,10){\ovalnode{B}{\hyperlink{zalezne_niezalezne}{\begin{tabular}{c}Czy zmienne\\są powiązane?\end{tabular}}}}
\ncline[angleA=-90, angleB=90, arm=.5, linearc=.2]{->}{A}{B}
\rput[tl](0.1,8){\ovalnode{C}{\hyperlink{wariancja}{\begin{tabular}{c}Czy wariancje\\zmiennych\\w populacjach\\ są równe?\end{tabular}}}}
\ncline[angleA=-90, angleB=90, arm=.5, linearc=.2]{->}{B}{C}
\rput[br](3,3){\rnode{D}{\psframebox{\hyperlink{test_t_student_niezaleny}{\begin{tabular}{c}test\\t-Studenta\\dla grup\\niezależnych\end{tabular}}}}}
\ncline[angleA=-90, angleB=90, arm=.5, linearc=.2]{->}{C}{D}
\rput(6,8.7){\psframebox{\hyperlink{test_t_student_zalezny}{\begin{tabular}{c}test\\t-Studenta\\dla grup\\zależnych\end{tabular}}}}
\rput(6.8,6.7){\psframebox{\hyperlink{test_cochran_cox}{\begin{tabular}{c}test t-Studenta\\z korektą Cochrana-Coxa\end{tabular}}}}
\psline{->}(3.7,12.3)(6,12.3)
\psline{->}(3.7,9.3)(4.9,9.3)
\psline{->}(3.6,6.7)(4.8,6.7)
\rput(2.4,10.4){T}
\rput(2.4,8.3){N}
\rput(2.3,5.2){T}
\rput(4.8,12.5){N}
\rput(6.8,11.5){T}
\rput(8.9,11.4){N}
\rput(12,11.4){T}
\rput(14.0,9.6){N}
\rput(4.5,9.1){T}
\rput(4.2,6.9){N}
\rput(8,14){\hyperlink{porzadkowa}{Skala porządkowa}}
\rput[tl](6,13){\ovalnode{E}{\hyperlink{zalezne_niezalezne}{\begin{tabular}{c}Czy zmienne\\są powiązane?\end{tabular}}}}
\rput[br](7.85,9.8){\rnode{F}{\psframebox{\hyperlink{test_wilcoxon_kolejnosci_par}{\begin{tabular}{c}test\\kolejności\\par Wilcoxona\end{tabular}}}}}
\rput[br](10.3,8.9){\rnode{G}{\psframebox{\hyperlink{test_mann-whitney}{\begin{tabular}{c}test\\Manna\\Whitneya,\\test $\chi^2$\\dla trendu\end{tabular}}}}}
\ncline[angleA=-90, angleB=90, arm=.5, linearc=.2]{->}{E}{F}
\ncline[angleA=-90, angleB=90, arm=.5, linearc=.2]{->}{E}{G}
\rput(13,14){\hyperlink{nominalna}{Skala nominalna}}
\rput[tl](11,13){\ovalnode{H}{\hyperlink{zalezne_niezalezne}{\begin{tabular}{c}Czy zmienne\\są powiązane?\end{tabular}}}}
\rput[br](13.5,9.1){\rnode{I}{\psframebox{\begin{tabular}{c}\hyperlink{test_bowker_mcnemar}{test Bowkera-}\\\hyperlink{test_bowker_mcnemar}{-McNemara,}\\\hyperlink{test_z_dla_dwoch_zal_proporcji}{test $Z$ dla}\\\hyperlink{test_z_dla_dwoch_zal_proporcji}{2 proporcji}\end{tabular}}}}
\rput[br](16.1,5.7){\rnode{J}{\psframebox{\begin{tabular}{c}\hyperlink{test_chi_r_na_c}{test $\chi^2 (R\times C)$,}\\\hyperlink{test_chi_dwa_na_dwa}{test $\chi^2 (2\times2)$,}\\\hyperlink{test_fisher_r_na_c}{test Fishera $(R\times C)$,}\\\hyperlink{test_fisher_dwa_na_dwa}{test Fishera, mid-p $(2 \times2)$,}\\\hyperlink{test_z_dla_dwoch_proporcji}{test $Z$ dla 2 proporcji}\end{tabular}}}}
\ncline[angleA=-90, angleB=90, arm=.5, linearc=.2]{->}{H}{I}
\ncline[angleA=-90, angleB=90, arm=.5, linearc=.2]{->}{H}{J}
\rput(6.2,5.5){(\hyperlink{test_f_snedecora}{test Fishera-Snedecora})}
\psline[linestyle=dotted]{<-}(3.6,5.9)(4.2,5.7)
\rput(9,8.4){\hyperlink{testy_normalnosci}{testy normalności}}
\rput(9.4,8.1){\hyperlink{testy_normalnosci}{rozkładu}}
\psline[linestyle=dotted]{<-}(3.6,11.1)(4.5,9.8)
\psline[linestyle=dotted]{-}(4.5,9.75)(7.6,9.75)
\psline[linestyle=dotted]{-}(7.6,9.75)(7.8,8.6)
\end{pspicture}](/lib/exe/fetch.php?media=wiki:latex:/img542157803d3ce0c109ccd74451391140.png "LaTeX")
Testy parametryczne
Test Fishera-Snedecora

Test Fishera-Snedecora (ang. F-Snedecor test) opiera się na zmiennej  sformułowanej przez Fishera (1924), a jej rozkład opisał Snedecor. Test ten służy do weryfikacji hipotezy o równości wariancji badanej zmiennej w dwóch populacjach.
sformułowanej przez Fishera (1924), a jej rozkład opisał Snedecor. Test ten służy do weryfikacji hipotezy o równości wariancji badanej zmiennej w dwóch populacjach.
Podstawowe warunki stosowania:
- pomiar na skali interwałowej,
- normalność rozkładu badanej zmiennej w obu populacjach,
Hipotezy:

gdzie:
 ,
, 
 wariancje badanej zmiennej w pierwszej i drugiej populacji.
wariancje badanej zmiennej w pierwszej i drugiej populacji.
Statystyka testowa ma postać:

gdzie:
 ,
,  wariancje badanej zmiennej w próbach wybranych losowo z pierwszej i drugiej populacji.
wariancje badanej zmiennej w próbach wybranych losowo z pierwszej i drugiej populacji.
Statystyka ta podlega rozkładowi F Snedecora z  i
i  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość  porównujemy z poziomem istotności poziomem istotności
porównujemy z poziomem istotności poziomem istotności  :
:

Okno z ustawieniami opcji testu F Fishera-Snedecora wywołujemy poprzez menu Statystyka→Testy parametryczne→F Fisher Snedecor.
Uwaga!
Obliczenia mogą bazować na danych w postaci surowych rekordów lub danych uśrednionych tzn. odchyleniach standardowych i liczności prób.
Test t-Studenta dla grup niezależnych
Test  -Studenta dla grup niezależnych (ang. t test for independent groups) służy do weryfikacji hipotezy o równości średnich badanej zmiennej w dwóch populacjach.
-Studenta dla grup niezależnych (ang. t test for independent groups) służy do weryfikacji hipotezy o równości średnich badanej zmiennej w dwóch populacjach.
Podstawowe warunki stosowania:
- pomiar na skali interwałowej,
- normalność rozkładu badanej zmiennej w obu populacjach,
- równość wariancji badanej zmiennej obu populacji.
Hipotezy:

gdzie:
 ,
,  średnie badanej zmiennej w pierwszej i drugiej populacji.
średnie badanej zmiennej w pierwszej i drugiej populacji.
Statystyka testowa ma postać:

gdzie:
 średnie w pierwszej i drugiej próbie,
średnie w pierwszej i drugiej próbie,
 liczności w pierwszej i drugiej próbie,
liczności w pierwszej i drugiej próbie,
 wariancje w pierwszej i drugiej próbie.
wariancje w pierwszej i drugiej próbie.
Statystyka testowa ma rozkład t-Studenta z  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Uwaga!
- wspólne odchylenie standardowe wyraża się wzorem:

- błąd standardowy różnicy średnich wyraża się wzorem:

Standaryzowana wielkość efektu
Współczynnik d-Cohena określa jak dużą częścią występującej zmienności jest różnica między średnimi.

Przy interpretacji efektu badacze często posługują się ogólnymi, określonymi przez Cohena 1) wskazówkami definiującymi małą (0.2), średnią (0.5) i dużą (0.8) wielkość efektu.
Okno z ustawieniami opcji testu t-Studenta dla grup niezależnych wywołujemy poprzez menu Statystyka→Testy parametryczne→t-Student dla grup niezależnych lub poprzez ''Kreator''.
Gdy w oknie testu w opcji dotyczącej wariancji wybierzemy:
równe, wówczas zostanie wyliczony test-Studenta dla grup niezależnych,sprawdź równość, wówczas zostanie wyliczony test Fishera-Snedecora a na podstawie jego wyniku i ustawionego poziomu istotności zostanie wybrany i wyliczony test t-Studenta dla grup niezależnych z bądź bez poprawki Cochrana-Coxa.
Uwaga!
Obliczenia mogą bazować na danych w postaci surowych rekordów lub danych uśrednionych tzn. średnich arytmetycznych, odchyleniach standardowych i liczności prób.
Przykład (plik choloesterol.pqs)
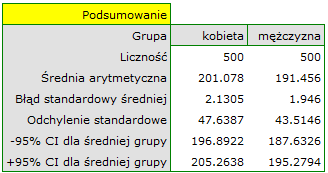
Z populacji kobiet i z populacji mężczyzn w wieku powyżej 40 roku życia wylosowano po 500 osób. Badanie dotyczyło oceny ryzyka chorób sercowo-naczyniowych. Wśród badanych parametrów znajduje się wartość cholesterolu całkowitego. Celem tego badania będzie porównanie mężczyzn i kobiet co do tej wartości. Chcemy bowiem wykazać, że te populacje różnią się już na poziomie cholesterolu całkowitego a nie tylko w obrębie cholesterolu rozbitego na frakcje.
Rozkład poziomu cholesterolu całkowitego w obu populacjach jest rozkładem normalnym (zostało to sprawdzone testem Lillieforsa). Średnia wartość cholesterolu w grupie mężczyzn wyniosła  a odchylenie standardowe
a odchylenie standardowe  , w grupie kobiet odpowiednio
, w grupie kobiet odpowiednio  i
i  . Test Fishera-Snedecora wskazuje na niewielkie lecz istotne statystycznie (
. Test Fishera-Snedecora wskazuje na niewielkie lecz istotne statystycznie ( ) różnice w wariancjach. W analizie zastosowany zostanie test t-Studenta z poprawką Cochrana-Coxa.
) różnice w wariancjach. W analizie zastosowany zostanie test t-Studenta z poprawką Cochrana-Coxa.
Hipotezy:

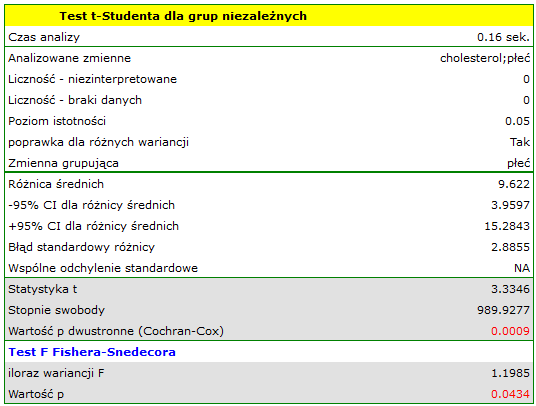
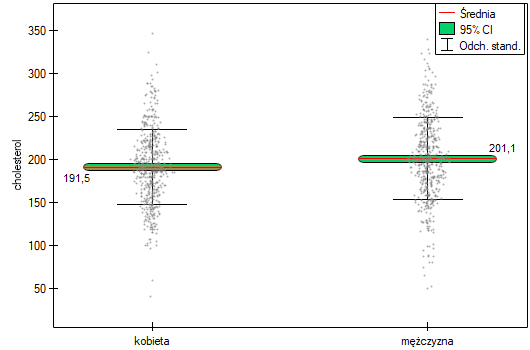
Porównując wartość  z poziomem istotności
z poziomem istotności  stwierdzamy, że kobiety i mężczyźni w Polsce różnią się istotnie statystycznie wartością cholesterolu całkowitego. Przeciętny Polak, który ukończył 40 rok życia ma wyższy cholesterol całkowity od przeciętnej Polki prawie o 10 jednostek.
stwierdzamy, że kobiety i mężczyźni w Polsce różnią się istotnie statystycznie wartością cholesterolu całkowitego. Przeciętny Polak, który ukończył 40 rok życia ma wyższy cholesterol całkowity od przeciętnej Polki prawie o 10 jednostek.
Test t-Studenta z korektą Cochrana-Coxa
Poprawka Cochrana-Coxa dotyczy testu t-Studenta dla grup niezależnych (ang. Cochran-Cox adjustment), (1957)2) i jest wyliczana wówczas, gdy wariancje badanych zmiennych w obu populacjach są różne.
Statystyka testowa ma postać:

Statystyka testowa ma rozkład t-Studenta z liczbą stopni swobody zaproponowaną przez Satterthwaite (1946)3) i wyliczaną z wzoru:

Okno z ustawieniami opcji testu t-Studenta dla grup niezależnych wywołujemy poprzez menu Statystyka→Testy parametryczne→t-Student dla grup niezależnych lub poprzez ''Kreator''.
Gdy w oknie testu w opcji dotyczącej wariancji wybierzemy:
równe, wówczas zostanie wyliczony test-Studenta dla grup niezależnych,różne, wówczas zostanie wyliczony test-Studenta z korektą Cochrana-Coxa,sprawdź równość, wówczas zostanie wyliczony test Fishera-Snedecora a na podstawie jego wyniku i ustawionego poziomu istotności zostanie wybrany i wyliczony test-Studenta dla grup niezależnych z bądź bez poprawki Cochrana-Coxa.
Uwaga!
Obliczenia mogą bazować na danych w postaci surowych rekordów lub danych uśrednionych tzn. średnich arytmetycznych, odchyleniach standardowych i liczności prób.
Test t-Studenta dla grup zależnych
Test t-Studenta dla grup zależnych (ang. t test for dependent groups) stosuje się w sytuacji gdy pomiarów badanej zmiennej dokonujemy dwukrotnie w różnych warunkach (przy czym zakładamy, że wariancje zmiennej w obu pomiarach są sobie bliskie). Interesuje nas różnica pomiędzy parami pomiarów ( ). Różnica ta wykorzystywana jest do weryfikacji hipotezy o tym, że średnia dla niej (dla różnicy) w badanej populacji wynosi 0.
). Różnica ta wykorzystywana jest do weryfikacji hipotezy o tym, że średnia dla niej (dla różnicy) w badanej populacji wynosi 0.
Podstawowe warunki stosowania:
- pomiar na skali interwałowej,
- normalność rozkładu różnicy pomiarów
 ,
,
Hipotezy:

gdzie:
 , średnia różnic w populacji.
, średnia różnic w populacji.
Statystyka testowa ma postać:

gdzie:
 średnia różnic w próbie,
średnia różnic w próbie,
 odchylenie standardowe różnic w próbie,
odchylenie standardowe różnic w próbie,
 liczność różnic w próbie.
liczność różnic w próbie.
Statystyka testowa ma rozkład t-Studenta z  stopniami swobody.
stopniami swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Uwaga!
- odchylenie standardowe różnicy wyraża się wzorem:

- błąd standardowy średniej różnic wyraża się wzorem:

Standaryzowana wielkość efektu.
Współczynnik d-Cohena określa jak dużą częścią występującej zmienności jest różnica między średnimi, biorąc pod uwagę skorelowanie zmiennych.
 .
.
 ,
,
 –
– Przy interpretacji efektu badacze często posługują się ogólnymi, określonymi przez Cohena 4) wskazówkami definiującymi małą (0.2), średnią (0.5) i dużą (0.8) wielkość efektu.
Okno z ustawieniami opcji testu t-Studenta dla grup zależnych wywołujemy poprzez menu Statystyka→Testy parametryczne→t-Student dla grup zależnych lub poprzez ''Kreator''.
Uwaga!
Obliczenia mogą bazować na danych w postaci surowych rekordów lub danych uśrednionych tzn. średniej różnic, odchyleniu standardowym różnic i liczności próby.
W klinice leczącej zaburzenia odżywiana badano wpływ zalecanej „diety A” na zmianę masy ciała. Próbę 120 otyłych chorych poddano diecie. Zbadano dla nich poziom BMI dwukrotnie: przed wprowadzeniem diety i po 180 dniach stosowania diety. By sprawdzić skuteczność diety porównano uzyskane wyniki pomiarów BMI.
Hipotezy:


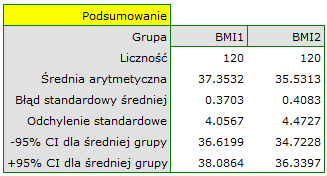
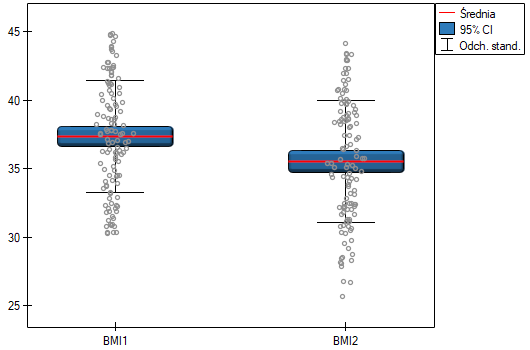
Porównując wartość  z poziomem istotności stwierdzamy, że średni poziom BMI zmienił się istotnie. Przed stosowaniem diety był wyższy średnio o niecałe 2 jednostki.
z poziomem istotności stwierdzamy, że średni poziom BMI zmienił się istotnie. Przed stosowaniem diety był wyższy średnio o niecałe 2 jednostki.
W badaniu możliwe było stosowanie testu t-Studenta dla grup zależnych, ponieważ rozkład różnicy pomiędzy parami pomiarów był rozkładem normalnym (test Lillieforsa, wartość  ).
).
Testy nieparametryczne
Test U Manna-Whitneya
Test U Manna-Whitneya (ang. Mann-Whitney U test) znany jest również jako test Wilcoxona Manna-Whitneya (ang. Wilcoxon Mann-Whitney test), Mann i Whitney (1947)5) oraz Wilcoxon (1949)6). Test ten służy do weryfikacji hipotezy o braku przesunięcia porównywanych rozkładów tzn. najczęsciej nieistotności różnic pomiędzy medianami badanej zmiennej w dwóch populacjach (przy czym zakładamy, że rozkłady zmiennej są sobie bliskie - porównanie wariancji rang można sprawdzić testem dla rang Conovera).
Podstawowe warunki stosowania:
- pomiar na skali porządkowej lub interwałowej,
Hipotezy dotyczą równości średnich rang dla porównywanych populacji lub są upraszczane do median:

gdzie:
 to rozkłady badanej zmiennej w pierwszej i drugiej populacji.
to rozkłady badanej zmiennej w pierwszej i drugiej populacji.
Wyznaczamy wartość statystyki testowej, a na jej podstawie wartość , którą porównujemy z poziomem istotności :
Uwaga!
W zależności od wielkości próby statystyka testowa przyjmuje inną postać:
- Dla małej liczności próby

lub

gdzie  to liczności prób,
to liczności prób,  to sumy rang dla prób.
to sumy rang dla prób.
Standardowo interpretacji podlega mniejsza z wartości  lub
lub  .
.
Statystyka ta podlega rozkładowi Manna-Whitneya i nie zawiera poprawki na rangi wiązane. Wartość dokładnego prawdopodobieństwa z rozkładu Manna-Whitneya wyliczana jest z dokładnością do części setnej ułamka.
- Dla próby o dużej liczności

Wzór na statystykę testową  zawiera poprawkę na rangi wiązane. Poprawka ta jest stosowana, gdy rangi wiązane występują (gdy nie ma rang wiązanych poprawka ta nie jest wyliczana, gdyż wówczas
zawiera poprawkę na rangi wiązane. Poprawka ta jest stosowana, gdy rangi wiązane występują (gdy nie ma rang wiązanych poprawka ta nie jest wyliczana, gdyż wówczas  )
)
Statystyka ma asymptotycznie (dla dużych liczności) rozkład normalny.
Poprawka na ciągłość testu Manna-Whitneya (Marascuilo and McSweeney (1977)7))
Poprawkę na ciągłość stosujemy by zapewnić możliwość przyjmowania przez statystykę testową wszystkich wartości liczb rzeczywistych zgodnie z założeniem rozkładu normalnego. Wzór na statystykę testową z poprawką na ciągłość wyraża się wtedy:

Standaryzowana wielkość efektu
Rozkład statystyki testu Manna-Whitneya jest aproksymowany przez rozkłady normalny, który można przekształcić na wielkość efektu  8) by następnie uzyskać wartość d-Cohena zgodnie ze standardową konwersją stosowaną przy meta-analizach:
8) by następnie uzyskać wartość d-Cohena zgodnie ze standardową konwersją stosowaną przy meta-analizach:

Przy interpretacji efektu badacze często posługują się ogólnymi, określonymi przez Cohena 9) wskazówkami definiującymi małą (0.2), średnią (0.5) i dużą (0.8) wielkość efektu.
Okno z ustawieniami opcji testu U Manna-Whitneya wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Mann-Whitney lub poprzez ''Kreator''.
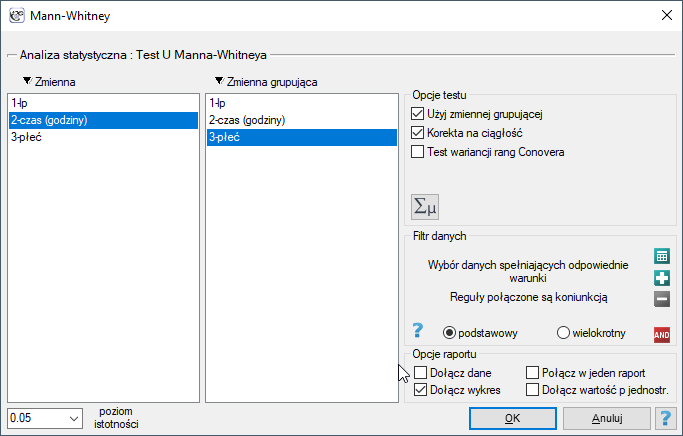
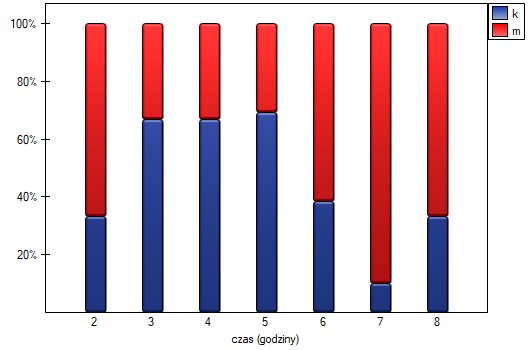
Wysunięto hipotezę, że na pewnej uczelni studenci matematyki spędzają statystycznie więcej czasu przed komputerem niż studentki matematyki. W celu weryfikacji tego przypuszczenia z populacji osób studiujących matematykę na tej uczelni wylosowano próbę liczącą 54 osoby (25 kobiet i 29 mężczyzn). Osoby te zapytano o to jak dużo czasu dziennie spędzają przy komputerze (czas w godzinach) i otrzymano następujące wyniki:
(czas, płeć): (2, k) (2, m) (2, m) (3, k) (3, k) (3, k) (3, k) (3, m) (3, m) (4, k) (4, k) (4, k) (4, k) (4, m) (4, m) (5, k) (5, k) (5, k) (5, k) (5, k) (5, k) (5, k) (5, k) (5, k) (5, m) (5, m) (5, m) (5, m) (6, k) (6, k) (6, k) (6, k) (6, k) (6, m) (6, m) (6, m) (6, m) (6, m) (6, m) (6, m) (6, m) (7, k) (7, m) (7, m) (7, m) (7, m) (7, m) (7, m) (7, m) (7, m) (7, m) (8, k) (8, m) (8, m).}
Hipotezy:


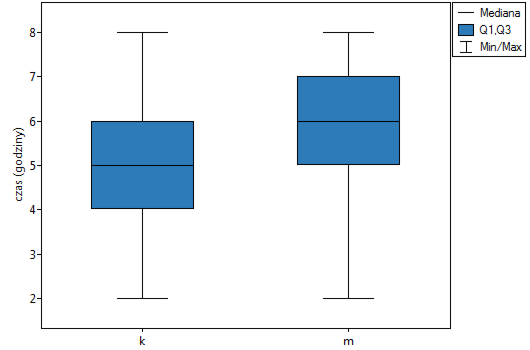
Na podstawie przyjętego poziomu i statystyki testu Manna-Whitneya bez poprawki na ciągłość (=0.015441) jak i z tą poprawką  , jak też na podstawie dokładnej statystyki (=0.014948) możemy przyjąć, że istnieją ważne statystycznie różnice pomiędzy studentkami a studentami matematyki w ilości czasu spędzanego przed komputerem. Różnice te polegają na tym, że studentki spędzają mniej czasu przed komputerem niż studenci. Opisać je można na podstawie mediany, kwartyli oraz wartości największej i najmniejszej, które widzimy również na wykresie typu ramka-wąsy. Innym sposobem opisu różnic jest przedstawienie czasu spędzonego przed komputerem na podstawie tabeli liczności i procentów (które uruchamiamy w oknie analizy ustawiając statystyki opisowe
, jak też na podstawie dokładnej statystyki (=0.014948) możemy przyjąć, że istnieją ważne statystycznie różnice pomiędzy studentkami a studentami matematyki w ilości czasu spędzanego przed komputerem. Różnice te polegają na tym, że studentki spędzają mniej czasu przed komputerem niż studenci. Opisać je można na podstawie mediany, kwartyli oraz wartości największej i najmniejszej, które widzimy również na wykresie typu ramka-wąsy. Innym sposobem opisu różnic jest przedstawienie czasu spędzonego przed komputerem na podstawie tabeli liczności i procentów (które uruchamiamy w oknie analizy ustawiając statystyki opisowe 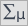 ) lub na podstawie wykresu kolumnowego.
) lub na podstawie wykresu kolumnowego.
Test Wilcoxona (kolejności par)
Test kolejności par Wilcoxona (ang. Wilcoxon matched-pairs test), znany również pod nazwą testu Wilcoxona dla grup zależnych, Wilcoxon (194510),194911)). Stosuje się go w sytuacji gdy pomiarów badanej zmiennej dokonujemy dwukrotnie w różnych warunkach. Jest on rozszerzeniem na dwie zależne próby testu rangowanych znaków Wilcoxona (przeznaczonego dla jednej próby). Interesuje nas różnica pomiędzy parami pomiarów badanej cechy () dla każdego z  badanych obiektów. Różnica ta wykorzystywana jest do weryfikacji hipotezy o tym, że mediana dla niej (dla różnicy) w badanej populacji wynosi 0.
badanych obiektów. Różnica ta wykorzystywana jest do weryfikacji hipotezy o tym, że mediana dla niej (dla różnicy) w badanej populacji wynosi 0.
Podstawowe warunki stosowania:
- pomiar na skali porządkowej lub interwałowej,
Hipotezy dotyczą równości sumy rang dodatnich i ujemnych lub są upraszczane do median:

gdzie:
 to - mediana w populacji.
to - mediana w populacji.
Wyznaczamy wartość statystyki testowej, a na jej podstawie wartość , którą porównujemy z poziomem istotności :
Uwaga!
W zależności od wielkości próby statystyka testowa przyjmuje inną postać:
- Dla małej liczności próby



Statystyka ta podlega rozkładowi Wilcoxona i nie zawiera poprawki na rangi wiązane.
- Dla próby o dużej liczności

Wzór na statystykę testową zawiera poprawkę na rangi wiązane. Poprawka ta jest stosowana, gdy rangi wiązane występują (gdy nie ma rang wiązanych poprawka ta nie jest wyliczana, gdyż wówczas  ).
).
Statystyka ma asymptotycznie (dla dużych liczności) rozkład normalny.
Poprawka na ciągłość testu Wilcoxona (Marascuilo and McSweeney (1977)12))
Poprawkę na ciągłość stosujemy by zapewnić możliwość przyjmowania przez statystykę testową wszystkich wartości liczb rzeczywistych zgodnie z założeniem rozkładu normalnego. Wzór na statystykę testową z poprawką na ciągłość wyraża się wtedy wzorem:

Uwaga! Od wersji 1.8.0 mediana wyliczana w dla kolumny różnica obejmuje wszystkie pary wyników za wyjątkiem tych, których różnica wynosi 0.
Standaryzowana wielkość efektu
Rozkład statystyki testu Wilcoxona jest aproksymowany przez rozkłady normalny, który można przekształcić na wielkość efektu  13) by następnie uzyskać wartość d-Cohena zgodnie ze standardową konwersją stosowaną przy meta-analizach:
13) by następnie uzyskać wartość d-Cohena zgodnie ze standardową konwersją stosowaną przy meta-analizach:
Przy interpretacji efektu badacze często posługują się ogólnymi, określonymi przez Cohena 14) wskazówkami definiującymi małą (0.2), średnią (0.5) i dużą (0.8) wielkość efektu.
Okno z ustawieniami opcji testu Wilcoxona dla grup zależnych wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Wilcoxon (kolejności par) lub poprzez ''Kreator''.
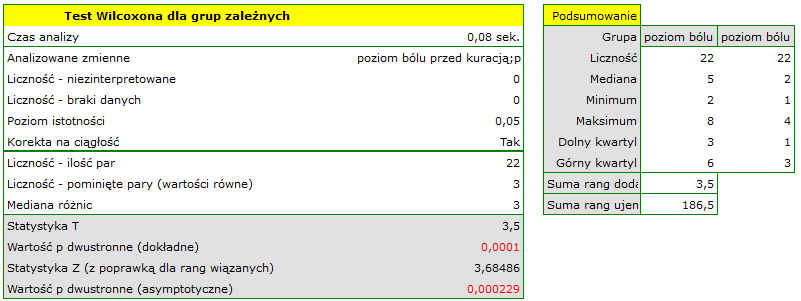
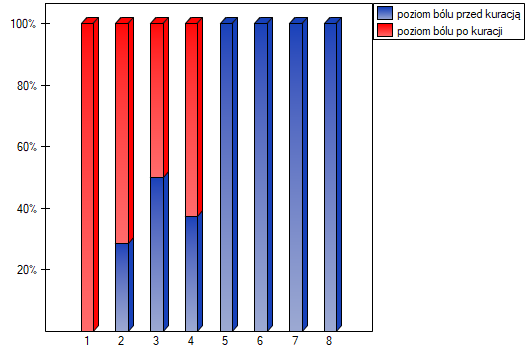
Pobrano próbę 22 pacjentów cierpiących na raka. Badano u nich poziom odczuwanego bólu (na skali od 1 do 10, gdzie 1 to brak bólu a 10 to ból największy). Badanie to powtórzono po miesiącu stosowania kuracji nowym lekiem mającym obniżyć poziom odczuwanego bólu. Otrzymano następujące wyniki:
(przed, po): (2, 2) (2, 3) (3, 1) (3,1) (3, 2) (3, 2) (3, 3) (4, 1) (4, 3) (4, 4) (5, 1) (5, 1) (5, 2) (5, 4) (5, 4) (6, 1) (6, 3) (7, 2) (7, 4) (7, 4) (8, 1) (8, 3). Chcemy sprawdzić, czy zastosowana kuracja ma wpływ na poziom odczuwanego bólu w populacji z której pochodzi próba.
Hipotezy:

Porównując wartość  testu Wilcoxona opartego o statystykę
testu Wilcoxona opartego o statystykę  z poziomem istotności stwierdzamy, że istnieje ważna statystycznie różnica w poziomie odczuwanego bólu pomiędzy dwoma badaniami. Różnica te polega na tym, że poziom bólu spadł (suma rang ujemnych jest znacznie większa niż suma rang dodatnich). Taką samą decyzję podjęlibyśmy również na podstawie wartości
z poziomem istotności stwierdzamy, że istnieje ważna statystycznie różnica w poziomie odczuwanego bólu pomiędzy dwoma badaniami. Różnica te polega na tym, że poziom bólu spadł (suma rang ujemnych jest znacznie większa niż suma rang dodatnich). Taką samą decyzję podjęlibyśmy również na podstawie wartości  lub
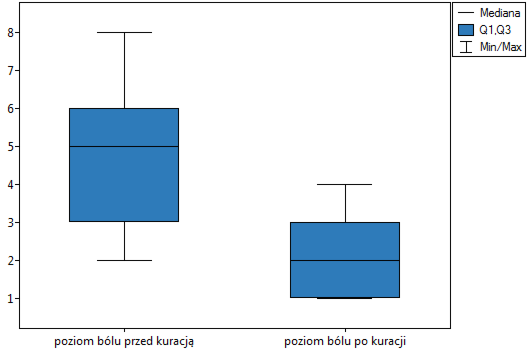
lub  testu Wilcoxona opartego o statystykę lub z poprawką na ciągłość. Różnice możemy zaobserwować na wykresie typu ramka-wąsy lub wykresie kolumnowym.
testu Wilcoxona opartego o statystykę lub z poprawką na ciągłość. Różnice możemy zaobserwować na wykresie typu ramka-wąsy lub wykresie kolumnowym.
Testy chi-kwadrat
Testy te opierają się na danych zebranych w postaci tabeli kontyngencji 2 cech, cechy X i cechy Y, z których pierwsza ma  a druga
a druga  kategorii, a więc powstała tabela ma wierszy i kolumn. Z tego względu możemy mówić o teście chi-kwadrat 2×2 (dla tabel o dwóch wierszach i dwóch kolumnach) lub o teście chi-kwadrat RxC (o wielu wierszach i kolumnach).
kategorii, a więc powstała tabela ma wierszy i kolumn. Z tego względu możemy mówić o teście chi-kwadrat 2×2 (dla tabel o dwóch wierszach i dwóch kolumnach) lub o teście chi-kwadrat RxC (o wielu wierszach i kolumnach).
Szczegółowe informacje na temat testu chi-kwadrat dwóch cech możemy przeczytać tutaj:
Podstawowe warunki stosowania:
- pomiar na skali nominalnej - ewentualne uporządkowanie kategorii nie jest brane pod uwagę,
Dodatkowy warunek dla testu  :
:
Hipotezy w brzmieniu ogólnym:
 dla wszystkich kategorii,
dla wszystkich kategorii,
 dla przynajmniej jednej kategorii.
dla przynajmniej jednej kategorii.
gdzie:
 liczności obserwowane w tabeli kontyngencji,
liczności obserwowane w tabeli kontyngencji,
 liczności oczekiwane w tabeli kontyngencji.
liczności oczekiwane w tabeli kontyngencji.
Hipotezy w brzmieniu testu niezależności:
 nie istnieje zależność pomiędzy badanymi cechami populacji (obie klasyfikacje ze względu na cechę X i na cechę Y są statystycznie niezależne),
nie istnieje zależność pomiędzy badanymi cechami populacji (obie klasyfikacje ze względu na cechę X i na cechę Y są statystycznie niezależne),
 istnieje zależność pomiędzy badanymi cechami populacji.
istnieje zależność pomiędzy badanymi cechami populacji.
Wyznaczoną wartość porównujemy z poziomem istotności :
Dodatkowo
Oprócz testu chi-kwadrat może zajść konieczność wyznaczenia innego, pokrewnego testu. W przypadku gdy warunek Cochrana nie jest spełniony można wyznaczyć:
W przypadku gdy uzyskamy tabelę Rx2, i kategorie R można uporządkować, możliwe jest wyznaczanie trendu:
W przypadku, gdy na podstawie testu wykonanego dla tabeli większej niż 2×2 stwierdzimy występowanie istotnych zależności lub różnic, wówczas można wykonać wielokrotne porównania wraz z odpowiednią korektą porównań wielokrotnych po to, by zlokalizować umiejscowienie tych zależności/różnic. Korekta taka może być dokonana automatycznie, gdy tabela ma wiele kolumn. Wówczas w oknie opcji testu należy zaznaczyć
Wielokrotne porównania kolumn (RxC).W przypadku, gdy chcemy opisać siłę związku między cechą X i cechą Y możemy wyznaczyć:
W przypadku, gdy chcemy opisać dla tabel 2×2 wielkość wpływu czynnika ryzyka możemy wyznaczyć:
Test chi-kwadrat dla dużych tabel
Test ten opierają się na danych zebranych w postaci tabeli kontyngencji 2 cech ( ,
,  ), z których pierwsza ma możliwe kategorii
), z których pierwsza ma możliwe kategorii  a druga kategorii
a druga kategorii  .
.
Test dla tabel  znany jest również pod nazwą testu Pearsona (ang. Pearson's Chi-square test), Karl Pearson 1900. Test ten jest rozszerzeniem na 2 cechy testu chi-kwadrat (dobroci dopasowania).
Statystyka testowa ma postać:
znany jest również pod nazwą testu Pearsona (ang. Pearson's Chi-square test), Karl Pearson 1900. Test ten jest rozszerzeniem na 2 cechy testu chi-kwadrat (dobroci dopasowania).
Statystyka testowa ma postać:

Statystyka ta ma asymptotycznie (dla dużych liczności oczekiwanych) rozkład chi-kwadrat z liczbą stopni swobody wyznaczaną według wzoru:  .
.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności poziomem istotności .
Okno z ustawieniami opcji testu Chi-kwadrat (RxC) wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Chi-kwadrat, Fisher, OR/RR lub poprzez ''Kreator''.
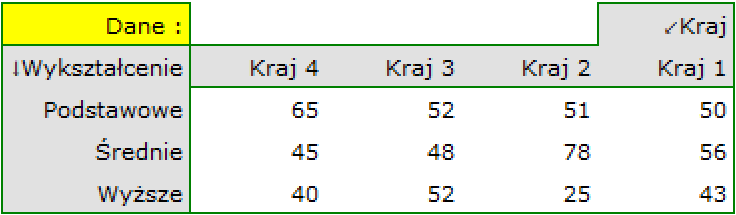
Przykład (plik kraj-wykształcenie.pqs)
Rozpatrujemy próbę 605 osób ( ), dla których badamy 2 cechy (=kraj zamieszkania, =wykształcenie). Pierwsza cecha występuje w 4, a druga w 3 kategoriach (
), dla których badamy 2 cechy (=kraj zamieszkania, =wykształcenie). Pierwsza cecha występuje w 4, a druga w 3 kategoriach ( =Kraj 1,
=Kraj 1,  =Kraj 2,
=Kraj 2,  =Kraj 3,
=Kraj 3,  =Kraj 4,
=Kraj 4,  =podstawowe,
=podstawowe,  =średnie,
=średnie,  =wyższe). Rozkład danych przedstawia tabela kontyngencji:
=wyższe). Rozkład danych przedstawia tabela kontyngencji:
Na podstawie tej próby chcielibyśmy się dowiedzieć, czy w badanej populacji istnieje zależność pomiędzy wykształceniem a krajem zamieszkania.
Hipotezy:

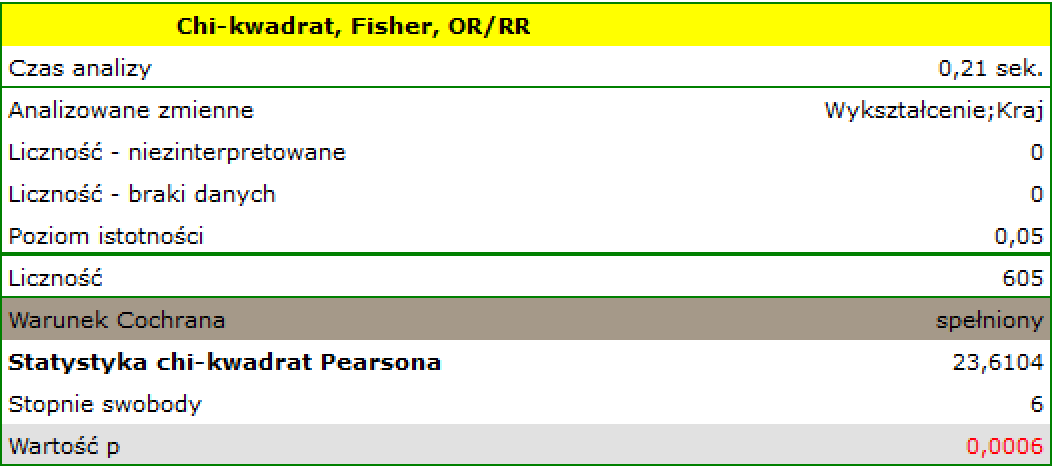
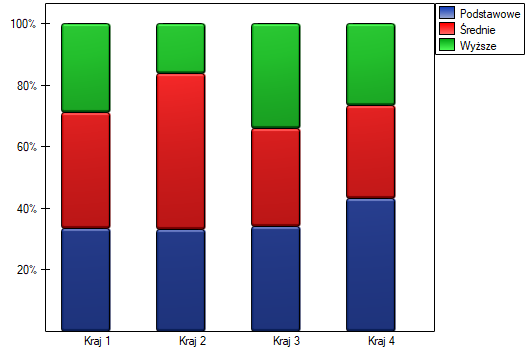
Warunek Cochrana jest spełniony.
Wartość  . Zatem na poziomie istotności możemy powiedzieć, że istniej zależność pomiędzy krajem zamieszkania a wykształceniem w badanej populacji.
. Zatem na poziomie istotności możemy powiedzieć, że istniej zależność pomiędzy krajem zamieszkania a wykształceniem w badanej populacji.
Jeśli interesują nas dokładniejsze informacje na temat wykrytych zależności, uzyskamy je wyznaczając porównania wielokrotne poprzez opcje Fisher, Yates i inne… a następnie Wielokrotne porównania kolumn (RxC) i jedną z poprawek np. Benjamini-Hochberg
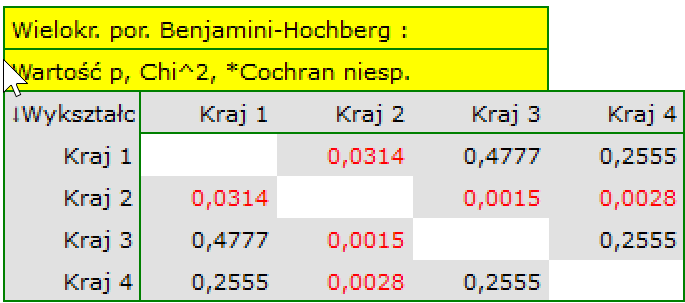
Dokładniejsza analiza pozwala stwierdzić, że jedynie drugi kraj różni się poziomem wykształcenia od pozostałych krajów w sposób istotny statystycznie.
Test chi-kwadrat dla małych tabel
Test ten opiera się na danych zebranych w postaci tabeli kontyngencji 2 cech (, ), z których każda ma możliwe 2 kategorie  oraz
oraz  .
.
Okno z ustawieniami opcji testu Chi-kwadrat oraz jego poprawek wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Chi-kwadrat, Fisher, OR/RR lub poprzez ''Kreator''.
Test dla tabel  (ang. Pearson's Chi-square test), Karl Pearson 1900. Test ten jest zawężeniem testu chi-kwadrat dla tabel (r x c).
(ang. Pearson's Chi-square test), Karl Pearson 1900. Test ten jest zawężeniem testu chi-kwadrat dla tabel (r x c).
Statystyka testowa ma postać:

Statystyka ta ma asymptotycznie (dla dużych liczności oczekiwanych) rozkład chi-kwadrat z jednym stopniem swobody.
Przykład (plik płeć-egzamin.pqs)
Rozpatrzmy próbę składającą się z 170 osób ( ), dla których badamy 2 cechy (=płeć, =zdawalność egzaminu). Każda z tych cech występuje w dwóch kategoriach (=k, =m, =tak, =nie). Na podstawie tej próby chcielibyśmy się dowiedzieć, czy w badanej populacji istnieje zależność pomiędzy płcią a zdawalnością egzaminu. Rozkład danych przedstawia tabeli kontyngencji:
), dla których badamy 2 cechy (=płeć, =zdawalność egzaminu). Każda z tych cech występuje w dwóch kategoriach (=k, =m, =tak, =nie). Na podstawie tej próby chcielibyśmy się dowiedzieć, czy w badanej populacji istnieje zależność pomiędzy płcią a zdawalnością egzaminu. Rozkład danych przedstawia tabeli kontyngencji:

Hipotezy:

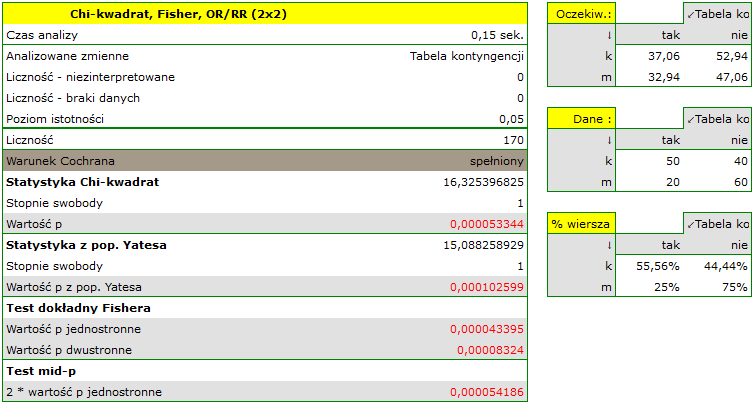
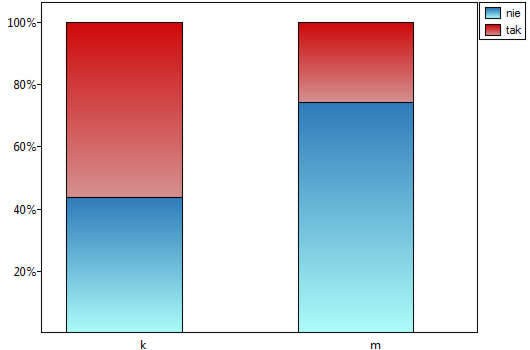
Tabela liczności oczekiwanych nie zawiera wartości mniejszych niż 5. Warunek Cochrana jest spełniony.
Przy przyjętym poziomie istotności wszystkie wykonane testy potwierdziły prawdziwość hipotezy alternatywnej:
- test chi-kwadrat, wartość
 ,
, - test chi-kwadrat z poprawką Yeatesa, wartość
 ,
, - test dokładny Fishera, wartość
 ,
, - test mid-p, wartość

Zatem istnieje zależność pomiędzy płcią a zdawalnością egzaminu w badanej populacji. Istotnie częściej ten egzamin zdają kobiety ( z wszystkich kobiet w próbie zdało egzamin) niż mężczyźni (
z wszystkich kobiet w próbie zdało egzamin) niż mężczyźni ( z wszystkich mężczyzn w próbie zdało egzamin)
z wszystkich mężczyzn w próbie zdało egzamin)
Test Fishera dla tabel dużych tabel
Test Fishera dla tabel zwany jest również testem Fishera-Freemana-Haltona (ang. Fisher-Freeman-Halton test), Freeman G.H., Halton J.H. (1951)16). Test ten jest rozszerzeniem na tabele testu dokładnego Fishera. Określa dokładne prawdopodobieństwo wystąpienia konkretnego rozkładu liczb w tabeli przy znanym i ustalonych sumach brzegowych.
Jeśli sumy brzegowe wierszy zdefiniujemy jako:

gdzie:
 liczności obserwowane w tabeli kontyngencji,
liczności obserwowane w tabeli kontyngencji,
a sumy brzegowe kolumn jako:

To przy ustalonych sumach brzegowych, dla różnych układów wartości obserwowanych oznaczonych jako  wyznaczamy prawdopodobieństwa
wyznaczamy prawdopodobieństwa  :
:

gdzie

Dokładny poziom istotności jest sumą tych prawdopodobieństw (wyznaczonych dla nowych wartości ), które są mniejsze lub równe prawdopodobieństwu tabeli z wartościami początkowymi
Porównujemy dokładną wartość z poziomem istotności :.
Okno z ustawieniami opcji testu dokładny Fishera (RxC) wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Chi-kwadrat, Fisher OR/RR lub poprzez ''Kreator''.
Info.
Procedura obliczania wartości dla tego testu bazuje na algorytmie opublikowanym w pracy Mehta (1986)17).
Przykład (plik praca-profilaktyka.pqs)
W populacji osób zamieszkujących na obszarach wiejskich gminy Komorniki badano czy wykonywanie badań profilaktyki zdrowia jest uzależnione od rodzaju aktywność zawodowej mieszkańców. Zebrano losową próbę 120 osób i zapytano o wykształcenie oraz o to czy osoby te wykonują badania profilaktyczne. Pełną odpowiedź uzyskano od 113 osób.
dane_praca_profilaktyka
Hipotezy:

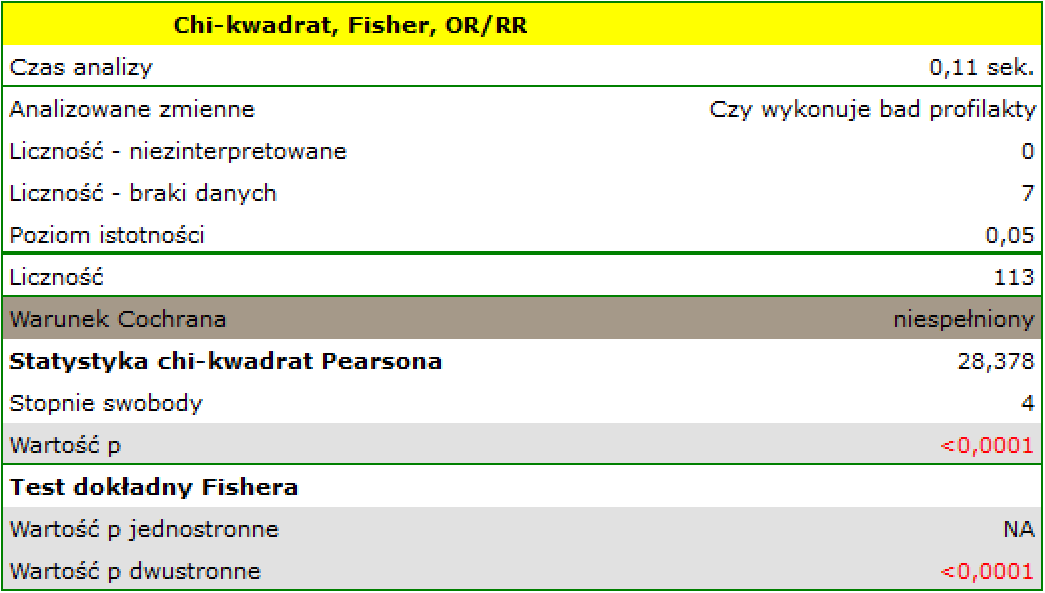
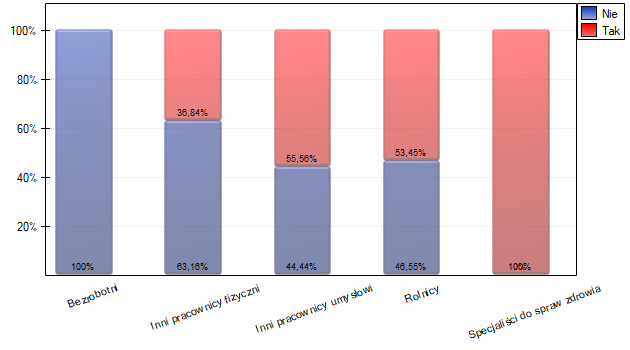
Warunek Cochrana nie jest spełniony, przez co nie powinniśmy stosować testu chi-kwadrat.
Wartość . Zatem na poziomie istotności możemy powiedzieć, że istniej zależność pomiędzy wykonywaniem badań profilaktycznych a rodzajem wykonywanej pracy przez mieszkańców obszarów wiejskich gminy Komorniki.
Jeśli interesują nas dokładniejsze informacje na temat wykrytych zależności, uzyskamy je wyznaczając porównania wielokrotne poprzez opcje Fisher, Yates i inne… a następnie Wielokrotne porównania kolumn (RxC) i jedną z poprawek np. Benjamini-Hochberg
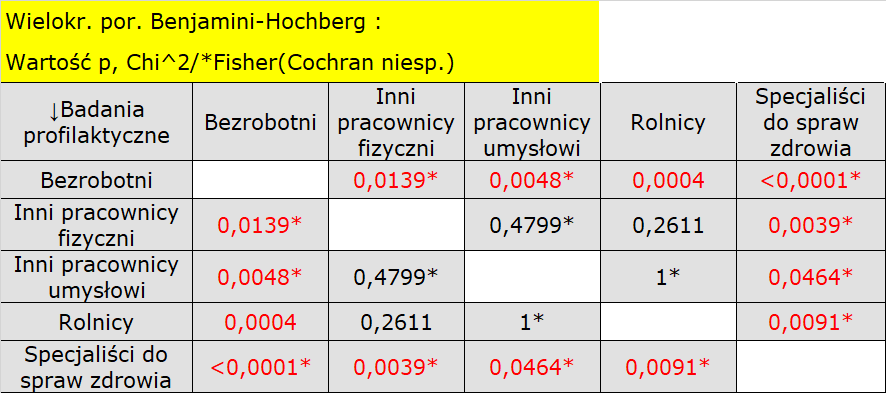
Dokładniejsza analiza pozwala stwierdzić, że specjaliści do spraw zdrowia istotnie częściej niż pozostałe grupy wykonują badania profilaktyczne (100% osób w tej grupie wykonało badania), a bezrobotni istotnie rzadziej (nikt w tej grupie nie wykonał badania). Rolnicy, inni pracownicy fizyczni i inni pracownicy umysłowi w około 50% wykonują badania profilaktyczne co powoduje, że te trzy grupy nie różnią się od siebie istotnie statystycznie. Część wartości p uzyskanych w tabeli oznaczona jest gwiazdką, oznacza ona te wyniki które powstały poprzez użycie testu dokładnego Fishera wraz z poprawką Benjaminiego-Hochberga, wartości nie oznaczone są wynikiem testu chi-kwadrat wraz z poprawką Benjaminiego-Hochberga, przy którym założenia Cochrana były spełnione
Poprawki testu chi-kwadrat dla małych tabel
Testy te opierają się na danych zebranych w postaci tabeli kontyngencji 2 cech (, ), z których każda ma możliwe 2 kategorie oraz .
Test chi-kwadrat z poprawką Yatesa na ciągłość
Test z poprawką Yatesa (ang. Chi-square test with Yates correction), Frank Yates (1934)18) jest testem bardziej konserwatywny od testu chi-kwadrat (trudniej niż test chi-kwadrat odrzuca hipotezę zerową). Poprawka na ciągłość ma zapewnić możliwość przyjmowania przez statystykę testową wszystkich wartości liczb rzeczywistych zgodnie z założeniem rozkładu chi-kwadrat.
Statystyka testowa ma postać:

Test Fishera dla tabel nazywany jest również testem dokładnym Fishera (ang. Fisher exact test), R. A. Fisher (193419), 193520)). Test ten określa dokładne prawdopodobieństwo wystąpienia konkretnego rozkładu liczb w tabeli przy znanym i ustalonych sumach brzegowych.
 Przy znanych sumach brzegowych, dla różnych układów wartości obserwowanych wyznaczamy prawdopodobieństwa . Dokładny poziom istotności jest sumą tych prawdopodobieństw, które są mniejsze lub równe badanemu prawdopodobieństwu.
Przy znanych sumach brzegowych, dla różnych układów wartości obserwowanych wyznaczamy prawdopodobieństwa . Dokładny poziom istotności jest sumą tych prawdopodobieństw, które są mniejsze lub równe badanemu prawdopodobieństwu.
mid-p jest korektą testu dokładnego Fishera. Ta zmodyfikowana wartość jest rekomendowana przez wielu statystyków (Lancaster 196121), Anscombe 198122), Pratt i Gibbons 198123), Plackett 198424), Miettinen 198525) i Barnard 198926), Rothman 200827)) jako metoda zmniejszenia konserwatyzm testu dokładnego Fishera. W rezultacie testem mid-p szybciej odrzucimy hipotezę zerowa niż dokładnym testem Fishera. Dla dużych prób wartość otrzymana przy pomocy testu z poprawką Yatesa i test Fishera dają zbliżone wyniki, natomiast wartość testu bez korekcji koresponduje z wartością mid-p.
Wartość mid-p wyznaczana jest przez przekształcenie wartości prawdopodobieństwa dla testu dokładnego Fishera. Jednostronna wartość wyznaczana jest ze wzoru:

gdzie:
 wartość jednostronna testu mid-p
wartość jednostronna testu mid-p
 wartość jednostronna testu dokładnego Fishera
wartość jednostronna testu dokładnego Fishera
a dwustronna wartość jest definiowana jako podwojona wartość mniejszego z jednostronnych prawdopodobieństw:

gdzie:
 wartość dwustronna testu mid-p.
wartość dwustronna testu mid-p.
Test chi-kwadrat dla trendu
Test dla trendu nazywany również testem dla trendu Cochrana-Armitage (ang. Cochran-Armitage test for trend)28)29) służy do weryfikacji hipotezy o istnieniu trendu w proporcjach dla poszczególnych kategorii badanej zmiennej (cechy). Opiera się na danych zebranych w postaci tabeli kontyngencji 2 cech, z których pierwsza ma możliwe uporządkowanych kategorii: a druga 2 kategorie  ,
,  .
.

Podstawowe warunki stosowania:
- pomiar na skali porządkowej lub interwałowej,
- model niezależny (druga cecha, to 2 niezależne grupy).
Niech  oznaczają proporcje
oznaczają proporcje  ,
,  ,…,
,…,  .
.
Hipotezy:

Statystyka testowa ma postać:
![\begin{displaymath}
\chi^2=\frac{\left[\left(\sum_{i=1}^r i\cdot O_{i1}\right) -C_1\left(\sum_{i=1}^r\frac{i\cdot W_i}{n}\right)\right]^2}{\frac{C_1}{n}\left(1-\frac{C_1}{n}\right)\left[\left(\sum_{i=1}^n i^2 W_i\right)-n\left(\sum_{i=1}^n\frac{i \cdot W_i}{n}\right)^2\right]}.
\end{displaymath}](/lib/exe/fetch.php?media=wiki:latex:/imgd32bd126527cf05771f082e9a0735129.png "LaTeX")
Statystyk ta ma rozkład chi-kwadrat z 1 stopniem swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności poziomem istotności :
Okno z ustawieniami opcji testu Chi-kwadrat dla trendu wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Chi-kwadrat, Fisher, OR/RR, opcja Fisher, Yates i inne…→Chi-kwadrat dla trendu.
Przykład (palenie-wykształcenie.pqs)
Sprawdzamy czy palenie papierosów związane jest z wykształceniem mieszkańców pewnej wsi. Wylosowano próbę 122 osób. Dane zapisano w pliku.
Zakładamy, że zależność może być dwojakiego typu tzn. czym bardziej wykształceni ludzie, tym częściej palą lub czym bardziej wykształceni ludzie, tym rzadziej palą. Poszukujemy zatem rosnącego lub malejącego trendu.
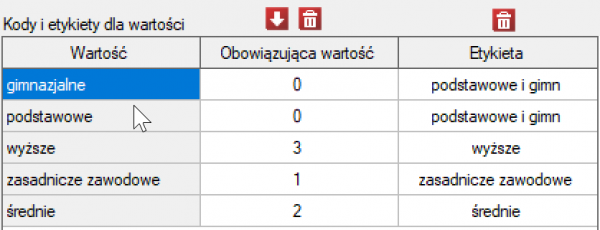
Przed przystąpieniem do analizy musimy przygotować dane, tzn. musimy wskazać kolejność w jakiej mają się pojawiać kategorie wykształcenia. W tym celu z właściwości zmiennej Wykształcenie wybieramy Kody/Etykiety/Format… i nadajemy kolejność podając kolejne liczby naturalne. Przypisujemy również etykiety.
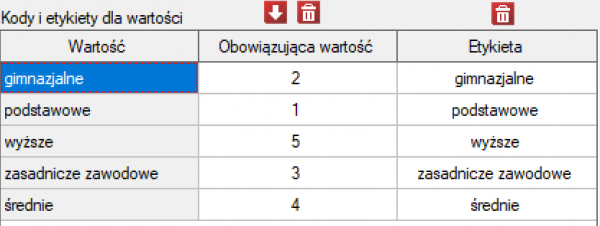
Hipotezy:


Wartość  , co w porównaniu z poziomem istotności =0.05 świadczy o prawdziwości hipotezy alternatywnej mówiącej o występowaniu trendu.
, co w porównaniu z poziomem istotności =0.05 świadczy o prawdziwości hipotezy alternatywnej mówiącej o występowaniu trendu.
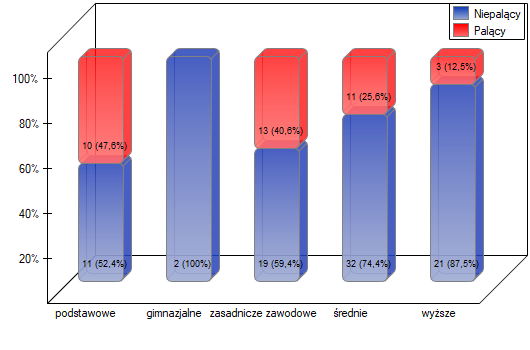
Jak wynika z wykresu czym osoby są bardziej wykształcone, tym rzadziej palą. Jednak wynik uzyskany przez osoby o wykształceniu gimnazjalnym odbiega od tego trendu. Ponieważ wykształcenie gimnazjalne dotyczy tylko dwóch osób, nie miało to dużego wpływu na rysujący się trend. Ze względu na bardzo małą liczność tej grupy postanowiono analizę powtórzyć dla połączonych kategorii wykształcenia podstawowego i gimnazjalnego.
Uzyskano ponownie niewielką wartość  i potwierdzenie istotnego statystycznie trendu.
i potwierdzenie istotnego statystycznie trendu.
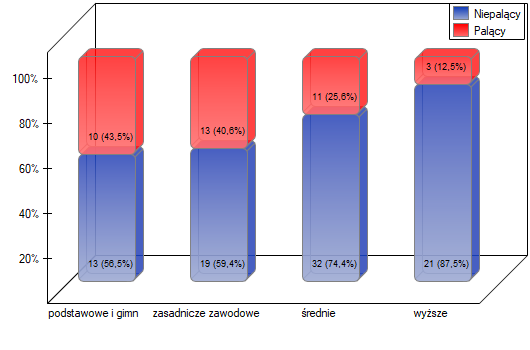
Z powodu spadku oglądalności pewnego serialu telewizyjnego przeprowadzono badanie opinii widzów tego serialu. W tym celu przepytano 100 osób, które rozpoczęły oglądanie serialu w ostatnim czasie i 300, które oglądają systematycznie serial od początku. Zapytano ich między innymi o ocenę stopnia zaabsorbowania widza losami bohaterów. Wyniki zapisano w tabeli poniżej:

Nowi widzowie stanowią 25% badanych. Taka proporcja nie utrzymuje się jednak dla każdej kategorii „stopnia zaciekawienia” ale przedstawia się następująco:

Hipotezy:

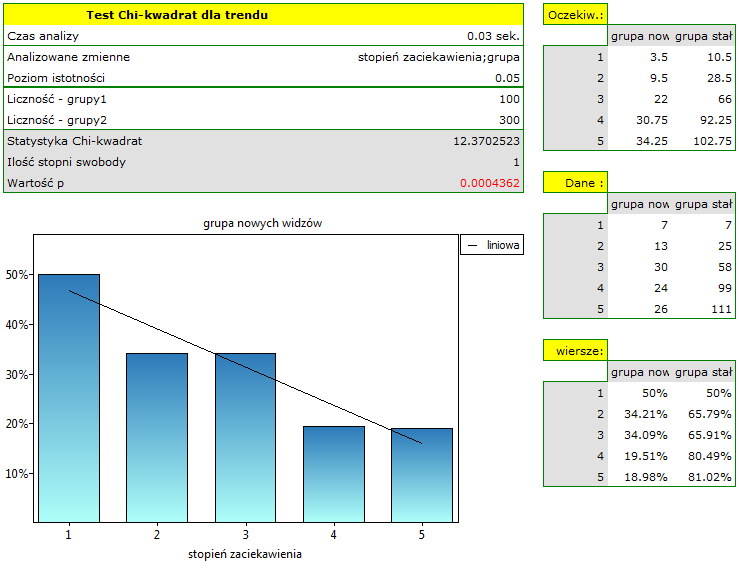
Wartość  , co w porównaniu z poziomem istotności =0.05 świadczy o prawdziwości hipotezy alternatywnej mówiącej o występowaniu trendu w proporcjach
, co w porównaniu z poziomem istotności =0.05 świadczy o prawdziwości hipotezy alternatywnej mówiącej o występowaniu trendu w proporcjach  . Jak wynika z tabeli kontyngencji wartości procentowych wyliczanych z sumy kolumn, jest to trend malejący (im grupa widzów jest bardziej zainteresowana losami bohaterów serialu, tym mniejszą jej część stanowią nowi widzowie).
. Jak wynika z tabeli kontyngencji wartości procentowych wyliczanych z sumy kolumn, jest to trend malejący (im grupa widzów jest bardziej zainteresowana losami bohaterów serialu, tym mniejszą jej część stanowią nowi widzowie).
Test Z dla dwóch niezależnych proporcji
Test dla dwóch niezależnych proporcji stosujemy w podobnych sytuacjach jak test chi-kwadrat (2x2), tzn. gdy mamy 2 niezależne próby o liczności  i
i  , w których możemy uzyskać 2 możliwe wyniki badanej cechy (jeden z nich to wynik wyróżniony o liczności
, w których możemy uzyskać 2 możliwe wyniki badanej cechy (jeden z nich to wynik wyróżniony o liczności  - w pierwszej próbie i
- w pierwszej próbie i  - w drugiej próbie). Dla prób tych możemy również wyznaczyć wyróżnione proporcje
- w drugiej próbie). Dla prób tych możemy również wyznaczyć wyróżnione proporcje  i
i  . Test ten służy do weryfikacji hipotezy, że wyróżnione proporcje
. Test ten służy do weryfikacji hipotezy, że wyróżnione proporcje  i
i  w populacjach, z których pochodzą próby są sobie równe.
w populacjach, z których pochodzą próby są sobie równe.
Podstawowe warunki stosowania:
- pomiar na skali nominalnej - ewentualne uporządkowanie kategorii nie jest brane pod uwagę,
- duża liczność.
Hipotezy:

gdzie:
, frakcja dla pierwszej i drugiej populacji.
Statystyka testowa ma postać:

gdzie:
 .
.
Zmodyfikowana o poprawkę na ciągłość statystyka testowa ma postać:

Statystyka bez korekcji na ciągłość jak i z tą korekcją ma asymptotycznie (dla dużych liczności) rozkład normalny.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
W programie oprócz różnicy proporcji wyliczana jest wartość wskaźnika NNT i/lub NNH.

NNT (ang. number needed to treat) wskaźnik stosowany w medycynie, oznacza liczbę pacjentów, których trzeba poddać leczeniu przez określony czas, aby wyleczyć jedną osobę, która w innych okolicznościach nie wyzdrowiałaby. NNT wyliczane jest z wzoru:

i jest cytowane wtedy, gdy różnica  jest dodatnia.
jest dodatnia.
NNH (ang. number needed to harm) wskaźnik stosowany w medycynie, oznacza liczbę pacjentów, których narażenie na ryzyko przez określony czas, powoduje uszczerbek na zdrowiu u jednej osoby, która w innych okolicznościach nie doznałaby uszczerbku. NNH wyliczane jest w ten sam sposób co NNT, ale jest cytowane wtedy, gdy różnica jest ujemna.
Przedział ufności im węższy przedział ufności, tym bardziej precyzyjne oszacowanie. Jeśli w przedziale ufności zawarte jest 0 dla różnicy ryzyka, a  dla NNT i/lub NNH, to jest wskazanie do tego, by dany wynik traktować jako nieistotny statystycznie.
dla NNT i/lub NNH, to jest wskazanie do tego, by dany wynik traktować jako nieistotny statystycznie.
Uwaga!
Przedziały ufności dla różnicy dwóch niezależnych proporcji od wersji PQStat 1.3.0 estymowane są w oparciu o metodę Newcomba-Wilsona (Bender (2001)30), Newcombe (1998)31), Wilson (1927)32)). W poprzednich wersjach były estymowane w oparciu o metodę Walda.
Uzasadnienie zmiany:
Przedziały ufności oparte o klasyczną metodę Walda są odpowiednie dla dużych rozmiarów próbek i różnicy proporcji dalekiej od 0 lub 1. Dla małych prób i różnicy proporcji bliskiej tym skrajnym wartościom, w wielu sytuacjach praktycznych, metoda Walda może prowadzić do wyników niewiarygodnych (Newcombe 199833), Miettinen 198534), Beal 198735), Wallenstein 199736)). Porównanie i przeanalizowanie wielu metod, które mogą być używane zamiast prostej metody Walda, można znaleźć w pracy Newcombe (1998)37). Sugerowaną, odpowiednią również dla skrajnych wartości proporcji, jest roszerzona na przedziały dla różnicy dwóch niezależnych proporcji, metoda opublikowana po raz pierwszy przez Wilsona (1927)38).
Uwaga!
Przedział ufności dla NNT i/lub NNH wyliczany jest jako odwrotność przedziału dla proporcji, zgodnie ze sposobem zaproponowanym przez Altmana (Altman (1998)39)).
Okno z ustawieniami opcji testu Z dla dwóch niezależnych proporcji wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Z dla dwóch niezależnych proporcji.
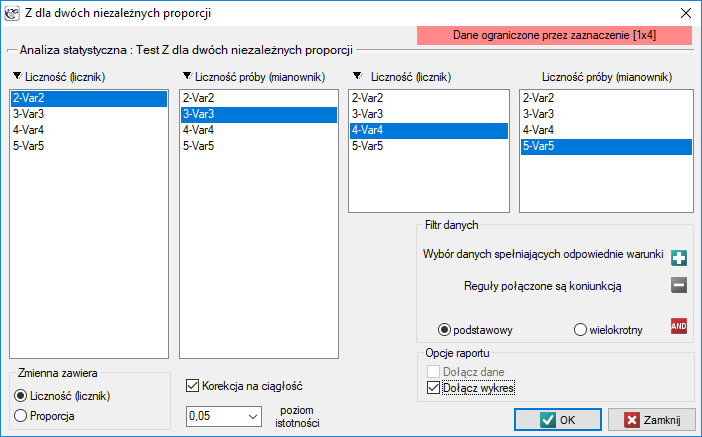
Przykład c.d. (plik płeć-egzamin.pqs)
Wiemy, że z wszystkich kobiet w próbie zdaje pozytywnie egzamin i z wszystkich mężczyzn w próbie zdaje egzamin pozytywnie.
Dane możemy zapisać na dwa sposoby jako licznik i mianownik dla każdej próby, lub jako proporcja i mianownik dla każdej próby:
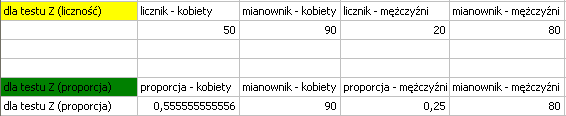
Hipotezy:

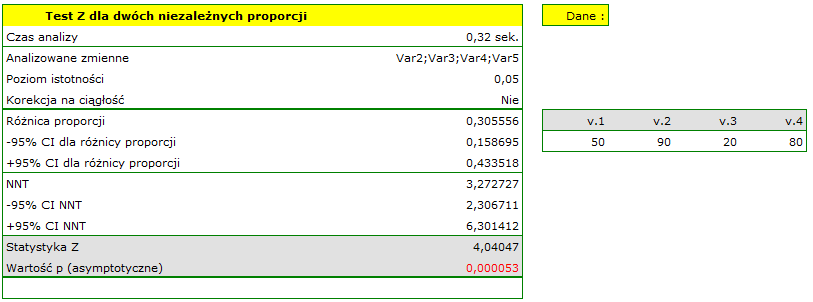
Uwaga!
Ponieważ w arkuszu danych znajduje się więcej informacji, przed rozpoczęciem analizy należy zaznaczyć odpowiedni obszar (dane bez nagłówków). W oknie testu natomiast wybrać opcję mówiącą o zawartości zmiennej (liczność (licznik) lub proporcja).
Różnica proporcji wyróżnionych w próbie to 30.56%, a 95% przedział ufności dla niej (15.90%, 43.35%) nie zawiera 0.
Na podstawie testu bez poprawki na ciągłość (=0.000053) jak też z poprawką na ciągłość (=0.0001), na poziomie istotności =0.05 (podobnie jak w przypadku testu dokładnego Fishera, jego poprawki mid-p, testu i testu z poprawką Yatesa) przyjmujemy hipotezę alternatywną. Zatem proporcja mężczyzn, uzyskujących pozytywny wynik egzaminu jest inna niż proporcja kobiet uzyskujących pozytywny wynik egzaminu w badanej populacji. Istotnie częściej ten egzamin zdają kobiety ( z wszystkich kobiet w próbie zdało egzamin) niż mężczyźni ( z wszystkich mężczyzn w próbie zdało egzamin).
Przykład
Załóżmy, że choroba ma śmiertelność 100% bez leczenia, a terapia zmniejsza śmiertelność do 50% - jest to wynik 20 letnich badań. Chcemy wiedzieć jak wiele osób będzie trzeba leczyć, aby zapobiec w ciągu 20 lat 1 śmierci. By odpowiedzieć na to pytanie pobrano dwie 100 osobowe próby z populacji osób chorych. W próbie nieleczonych mamy 100 chorych pacjentów, wiemy, że bez leczenia wszyscy oni umrą. W próbie leczonych mamy również 100 pacjentów, z których 50 przeżyje.

Wyliczymy wskaźnik NNT.
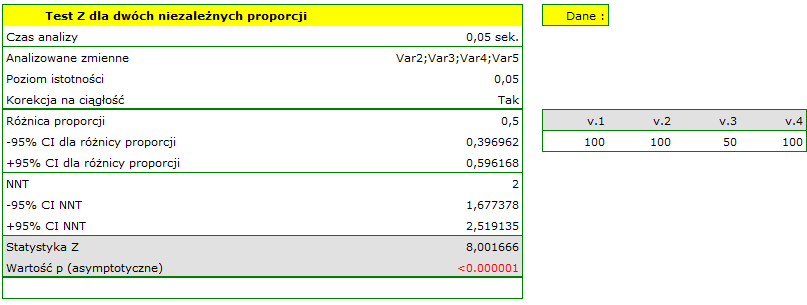
Różnica pomiędzy proporcjami jest istotna statystycznie ( ), ale nas interesuje wskaźnik NNT - wynosi on 2, czyli stosowanie leczenia u 2 chorych przez 20 lat zapobiegnie 1 śmierci. Wyliczony 95% przedział ufności należy zaokrąglić do wartości całkowitych, co daje NNT od 2 do 3 chorych.
), ale nas interesuje wskaźnik NNT - wynosi on 2, czyli stosowanie leczenia u 2 chorych przez 20 lat zapobiegnie 1 śmierci. Wyliczony 95% przedział ufności należy zaokrąglić do wartości całkowitych, co daje NNT od 2 do 3 chorych.
Przykład
Wartość pewnej różnicy proporcji w badaniu porównującym skuteczność leku 1 vs lek 2 wynosiła różnica(95%CI)=-0.08 (-0.27 do 0.11). Ta ujemna różnica proporcji sugeruje, że lek 1 był mniej skuteczny niż lek 2, jego zastosowanie naraziło więc chorych na ryzyko. Ponieważ różnica proporcji jest ujemna, to wyznaczoną odwrotność nazywamy NNH, a ponieważ przedział ufności zawiera nieskończoność NNH(95%CI)= 2.5 (NNH 3.7 to ∞ to NNT 9.1) i przechodzi z NNH do NNT, należy uznać że uzyskany wynik nie jest istotny statystycznie (Altman (1998)40)).
Test Z dla dwóch zależnych proporcji
Test dla dwóch zależnych proporcji stosujemy w podobnych sytuacjach jak test Test McNemara, tzn. gdy mamy 2 zależne grupy pomiarów ( i
i  ), w których możemy uzyskać 2 możliwe wyniki badanej cechy (
), w których możemy uzyskać 2 możliwe wyniki badanej cechy (  i
i  ).
).

Dla grup tych możemy również wyliczyć wyróżnione proporcje  i
i  . Test ten służy do weryfikacji hipotezy, że wyróżnione proporcje i w populacji, z której pochodzi próba są sobie równe.
. Test ten służy do weryfikacji hipotezy, że wyróżnione proporcje i w populacji, z której pochodzi próba są sobie równe.
Podstawowe warunki stosowania:
- pomiar na skali nominalnej - ewentualne uporządkowanie kategorii nie jest brane pod uwagę,
- duża liczność.
Hipotezy:

gdzie:
, frakcja dla pierwszego i drugiego pomiaru.
Statystyka testowa ma postać:

Statystyka Z ma asymptotycznie (dla dużych liczności) rozkład normalny.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Uwaga!
Przedział ufności dla różnicy dwóch zależnych proporcji estymowany jest w oparciu o metodę Newcomba-Wilsona.
Okno z ustawieniami opcji testu Z dla dwóch zależnych proporcji wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Z dla dwóch zależnych proporcji.
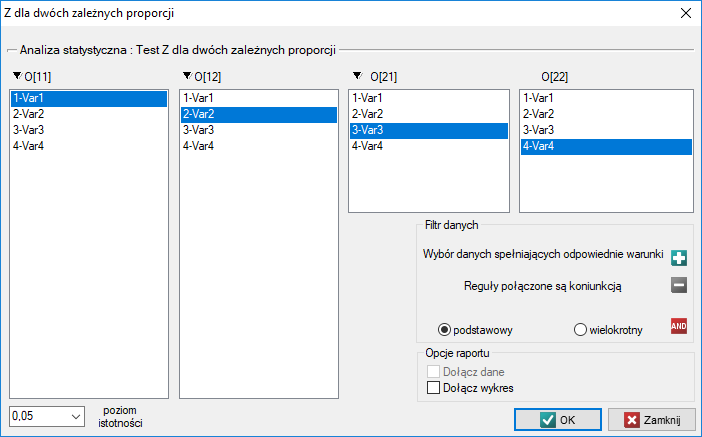
Przykład c.d. (plik opinia.pqs)
Gdy ograniczymy nasze badanie do osób mających zdefiniowany pogląd na temat wykładowcy (tzn. oceniają tylko pozytywnie lub negatywnie), to takich studentów uzyskamy 152. Dane do obliczeń to:  ,
,  ,
,  ,
,  . Wiemy, że
. Wiemy, że  studentów przed egzaminem wyrażało negatywną opinię. Po egzaminie odpowiedni procent wynosił
studentów przed egzaminem wyrażało negatywną opinię. Po egzaminie odpowiedni procent wynosił  .
.
Hipotezy:

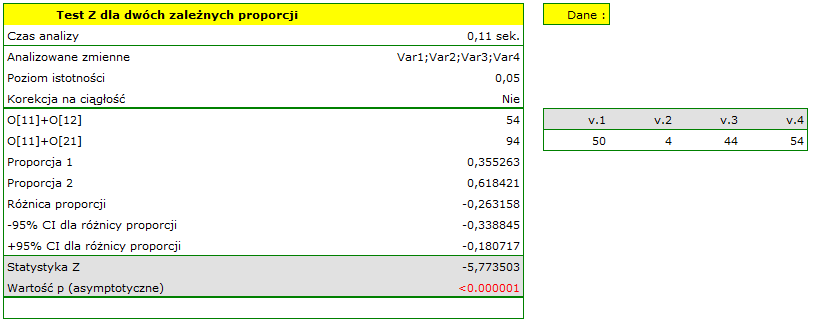
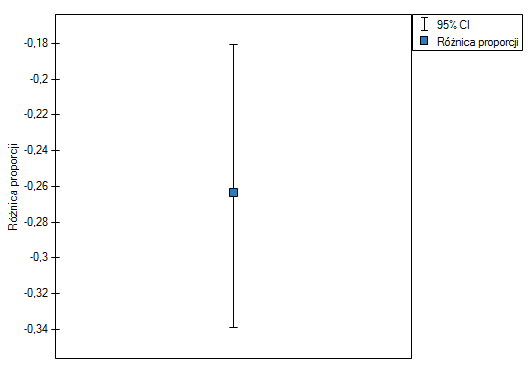
Różnica proporcji wyróżnionych w próbie to 26.32%, a 95% przedział ufności dla niej (18.07%, 33.88%) nie zawiera 0.
Na podstawie testu (=0.0001), na poziomie istotności =0.05 (podobnie jak w przypadku testu McNemara) przyjmujemy hipotezę alternatywną. Zatem proporcja negatywnych ocen przed egzaminem jest inna niż proporcja negatywnych ocen po egzaminie. Po egzaminie istotnie częściej wykładowca jest oceniany negatywnie.
Test McNemara, test wewnętrznej symetrii Bowkera
Podstawowe warunki stosowania:
- pomiar na skali nominalnej - ewentualne uporządkowanie kategorii nie jest brane pod uwagę,
Test McNemara (ang. McNemar test), NcNemar (1947)41). Test ten służy do weryfikacji hipotezy o zgodności pomiędzy wynikami dwukrotnych pomiarów i cechy (pomiędzy dwiema zmiennymi zależnymi i ). Badana cecha może mieć tylko 2 kategorie (oznaczone przez nas i ). Test McNemara można wyliczać na podstawie danych surowych albo z wykonanej na podstawie danych surowych tabeli kontyngencji o wymiarach .
Hipotezy:

Statystyka testowa ma postać:

Statystyka ta ma asymptotycznie (dla dużych liczności) rozkład chi-kwadrat z jednym stopniem swobody.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Poprawka na ciągłość testu McNemara
Poprawka ta jest testem bardziej konserwatywny od testu McNemara (trudniej niż test McNemara odrzuca hipotezę zerową). Ma ona zapewnić możliwość przyjmowania przez statystykę testową wszystkich wartości liczb rzeczywistych zgodnie z założeniem rozkładu . Część źródeł podaje, że poprawkę na ciągłość powinno się wykonywać zawsze, natomiast część uznaje, że tylko wtedy, gdy liczności w tabeli są małe.
Statystyka testowa testu McNemara z poprawką na ciągłość ma postać:

Dokładny test McNemara
Powszechną, ogólną zasadą ważności asymptotycznego testu McNemara chi-kwadrat jest warunek Rufibach, czyli to, że liczba niezgodnych par jest większa niż 10:  42), gdy warunek ten nie jest spełniony, wówczas powinniśmy bazować na dokładnych wartościach prawdopodobieństwa tego testu 43). Dokładna wartość prawdopodobieństwa testu oparta jest o rozkład dwumianowy i jest testem konserwatywnym, dlatego obok dokładnej wartości testu MnNemara podano również polecaną wartość dokładną mid-p testu McNemara.
42), gdy warunek ten nie jest spełniony, wówczas powinniśmy bazować na dokładnych wartościach prawdopodobieństwa tego testu 43). Dokładna wartość prawdopodobieństwa testu oparta jest o rozkład dwumianowy i jest testem konserwatywnym, dlatego obok dokładnej wartości testu MnNemara podano również polecaną wartość dokładną mid-p testu McNemara.
Jeśli przeprowadzone zostało 2 krotnie badanie tej samej cechy na tych samych obiektach - wówczas dla takiej tabeli wylicza się iloraz szans na zmianę wyniku (z na i odwrotnie).
Szansa zmiany wyniku z na wynosi  , a szansa zmiany wyniku z na wynosi
, a szansa zmiany wyniku z na wynosi  .
.
Iloraz szans (ang. odds ratio - OR) to:

Przedział ufności dla ilorazu szans buduje się w oparciu o błąd standardowy:

Uwaga!
Dodatkowo, dla prób o niewielkich licznościach, można wyznaczyć dokładny zakres przedziału ufności dla Ilorazu Szans 44).
Okno z ustawieniami opcji testu Bowkera-McNemara wywołujemy poprzez menu Statystyka→Testy nieparametryczne→Bowker-McNemar lub poprzez ''Kreator''.
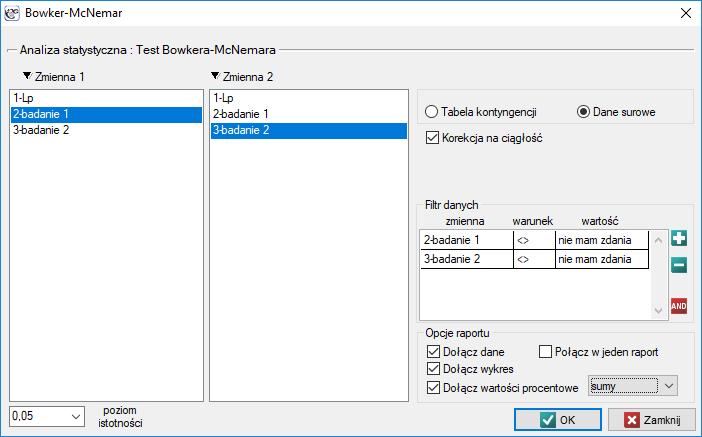
Test wewnętrznej symetrii Bowkera
Test wewnętrznej symetrii Bowkera (ang. Bowker test of internal symmetry), Bowker (1948)45). Test ten jest rozszerzeniem testu McNemara na 2 zmienne o więcej niż dwóch kategoriach ( ). Służy do weryfikacji hipotezy o symetryczności wyników dwukrotnych pomiarów i cechy (symetryczności 2 zmiennych zależnych i ). Badana cecha może mieć więcej niż 2 kategorie. Test wewnętrznej symetrii Bowker można wyliczać na podstawie danych surowych albo z wykonanej na podstawie danych surowych tabeli kontyngencji o wymiarach
). Służy do weryfikacji hipotezy o symetryczności wyników dwukrotnych pomiarów i cechy (symetryczności 2 zmiennych zależnych i ). Badana cecha może mieć więcej niż 2 kategorie. Test wewnętrznej symetrii Bowker można wyliczać na podstawie danych surowych albo z wykonanej na podstawie danych surowych tabeli kontyngencji o wymiarach  .
.

Hipotezy:

gdzie  ,
,  ,
,  , zatem i
, zatem i  to liczności symetrycznych par w tabeli
to liczności symetrycznych par w tabeli
Statystyka testowa ma postać:

Statystyka ta ma asymptotycznie (dla dużych liczności) rozkład chi-kwadrat z liczbą stopni swobody wyliczaną według wzoru  .
.
Wyznaczoną na podstawie statystyki testowej wartość porównujemy z poziomem istotności :
Przeprowadzono 2 badania opinii studentów na temat określonego wykładowcy akademickiego. Oba badania pozwalały ocenić wykładowcę negatywnie, pozytywnie, lub wybrać odpowiedź neutralną - nie mam zdania. Oba badania przeprowadzono na tej samej próbie 250 studentów z tym, że pierwsze badanie dokonano dzień przed egzaminem z przedmiotu prowadzonego przez ocenianego wykładowcę a drugie dzień po egzaminie. Poniżej przedstawiono fragment danych w postaci surowej oraz całość danych w postaci tabeli kontyngencji. Chcemy zbadać, czy obydwa badania dają podobne wyniki.

Hipotezy:

gdzie np. zmiana opinii z pozytywnej na negatywną jest symetryczna względem zmiany opinii z negatywnej na pozytywną.
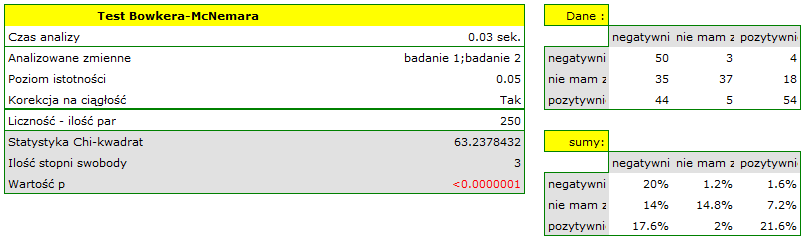
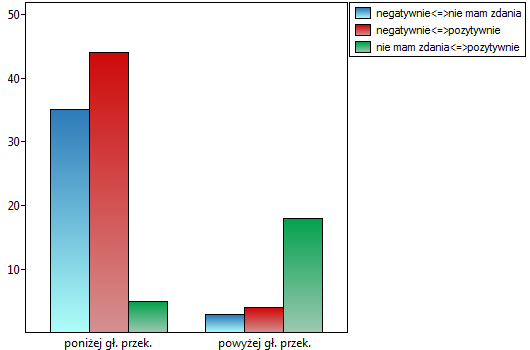
Porównując wartość dla testu Bowkera z poziomem istotności stwierdzamy, że opinie studentów zmieniły się. Z tabeli wynika, że istotnie więcej było tych studentów, którzy zmienili swoją opinię na negatywną po egzaminie niż tych którzy zmienili ją na pozytywną, oraz wielu studentów oceniających przed egzaminem wykładowcę pozytywnie po egzaminie nie wyrażało już takiego zdania.
Gdybyśmy ograniczyli nasze badanie do osób mających zdefiniowany pogląd na temat wykładowcy (tzn. oceniają tylko pozytywnie lub negatywnie), to moglibyśmy wykorzystać test McNemara:
Hipotezy:

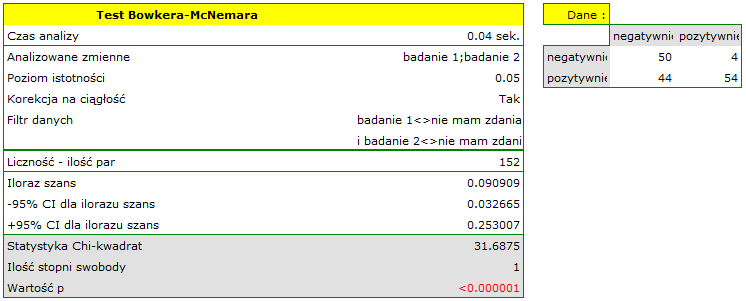
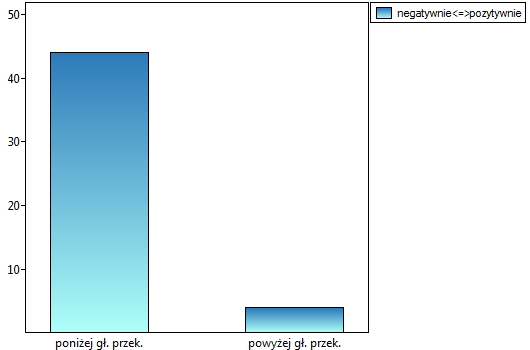
Porównując wartość dla testu McNemara z poziomem istotności stwierdzamy, że opinie studentów zmieniły się. Istotnie więcej było tych studentów, którzy zmienili swoją opinie na negatywną po egzaminie niż tych którzy zmienili ją na pozytywną. Szansa zmiany opinii z pozytywnej (przed egzaminem) na negatywną (po egzaminie) jest jedenaście  razy większa niż z negatywnej na pozytywną (szansa zmiany opinii w przeciwną stronę to:
razy większa niż z negatywnej na pozytywną (szansa zmiany opinii w przeciwną stronę to:  czyli 0.090909).
czyli 0.090909).