Symulacja próbkowania
 Okno próbkowania wywołujemy poprzez
Okno próbkowania wywołujemy poprzez Dane→Symulacja próbkowania …
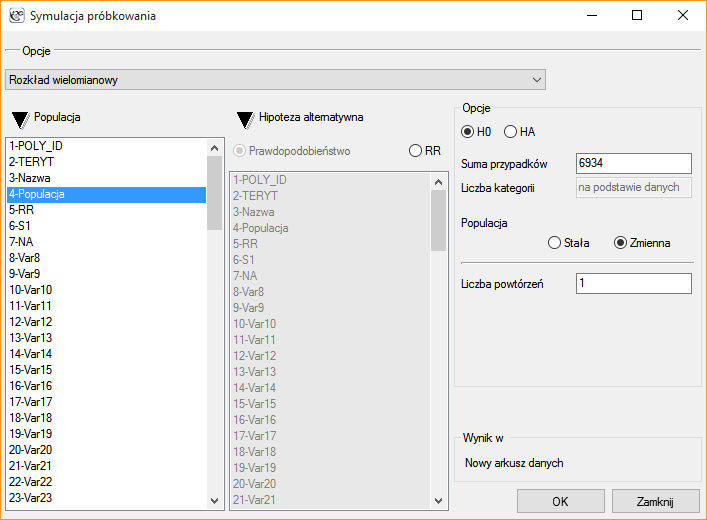
Symulacja próbkowania jest jednym ze sposobów generowania danych rozkładu wielomianowego. Polega na przydzieleniu podanej liczby przypadków do poszczególnych kategorii, w sposób zadany przez użytkownika. Wygenerowane dane zwracane są w nowym arkuszu. Generowanie może zostać powtórzone, tak by w arkuszu uzyskać wiele wygenerowanych kolumn w zależności od ustawionej w oknie próbkowania liczby powtórzeń tej operacji.
Opcje:
- H0 - hipoteza zerowa zakłada równomierne rozmieszczenie wszystkich przypadków w poszczególnych kategoriach.
- HA - hipoteza alternatywna zakłada nierównomierne rozmieszczenie przypadków. Wybranie tej opcji wymaga wskazania kategorii o większym prawdopodobieństwie lub relatywnym ryzyku. Informacja o zdefiniowanym prawdopodobieństwie lub relatywnym ryzyku dla każdej kategorii powinna zostać wprowadzona do wybranej kolumny arkusza przed przeprowadzeniem analizy.
Prawdopodobieństwo należy zdefiniować jako wartość od 0 do 1, przy czym suma prawdopodobieństw podanych dla wszystkich kategorii powinna wynosić 1.
Relatywne ryzyko definiuje ryzyko względem innych kategorii i dla kategorii o zwiększonym ryzyku jest wartością większą niż 1, a ułamkiem mniejszym niż 1 dla kategorii o zmniejszonym ryzyku.
Ustawienie wartości prawdopodobieństwa lub relatywnego ryzyka na tym samym poziomie dla wszystkich kategorii, tożsame jest z rozkładem dla H0.
- Populacja stała - zakłada, że użytkownik zainteresowany jest rozmieszczeniem przypadków zgodnie z zaproponowanym rozkładem.
- Populacja zmienna - zakłada, że użytkownik zainteresowany jest takim rozmieszczeniem przypadków, aby proporcja przypadków do populacji rozmieszczona została zgodnie z zaproponowanym rozkładem.
Jako podstawę symulacji użyto populację Wielkopolski w roku 2013, która wynosiła wg GUS  = 3467016 osób. Województwo podzielone jest na 315 gmin. Gminy różnią się znacznie liczbą mieszkańców. Najliczniejsza gmina (stolica województwa) 548028 mieszkańców, najmniej liczna 1454 mieszkańców, mediana i kwartyle to odpowiednio: 6298 (4462; 9621) mieszkańców. Przy założeniu, że w 2013 roku mieszkańców województwa z chorobą X było 6934, należy zasymulować rozlokowanie osób chorych w taki sposób, by uzyskać:
= 3467016 osób. Województwo podzielone jest na 315 gmin. Gminy różnią się znacznie liczbą mieszkańców. Najliczniejsza gmina (stolica województwa) 548028 mieszkańców, najmniej liczna 1454 mieszkańców, mediana i kwartyle to odpowiednio: 6298 (4462; 9621) mieszkańców. Przy założeniu, że w 2013 roku mieszkańców województwa z chorobą X było 6934, należy zasymulować rozlokowanie osób chorych w taki sposób, by uzyskać:
- Rozkład losowy (na podstawie danych z arkusza „Losowy”)
- Czterokrotnie większe częstości występowania choroby we wskazanych gminach niż w pozostałej części województwa (na podstawie danych z arkusza „Klastery”)
[Ad 1.]
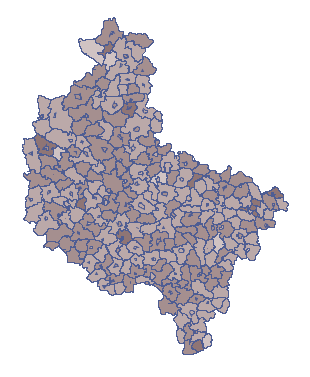
Należy zaznaczyć, że równomierne rozłożenie 6934 chorych w sposób losowy nie oznacza podobnej liczby chorych w każdej gminie. Wiadomo, że gminy o większej liczbie narażonych powinny mieć odpowiednią większą liczbę chorych niż te o mniejszej liczbie mieszkańców. Interesujące jest więc takie rozłożenie chorych, by współczynnik liczby chorych do liczby mieszkańców był względnie stały. Oznacza to przyjęcie hipotezy zerowej H0 i zmiennej populacji. Liczność poszczególnych gmin zapisano w kolumnie o nazwie: populacja.
Wylosowane na podstawie tych założeń dane przedstawiono w pierwszej kolumnie nowego arkusza danych. By móc obserwować losowy rozkład współczynnika chorych w poszczególnych gminach, należy przekopiować uzyskany wynik do arkusza „Losowo” kolumny „S1”. Formuła znajdująca się w kolumnie 7 zostanie wówczas ponownie przeliczona (podejrzeć i zmienić formułę można ustawiając Kody/Etykiety/Format we właściwościach kolumny). Na mapie przedstawiamy uzyskany wynik przy pomocy menagera Map  z menu Analiza przestrzenna. Wyrysowana zostaje wówczas proporcja chorych do liczby mieszkańców w poszczególnych gminach. Przykładowy wynik przedstawia poniższa mapa.
z menu Analiza przestrzenna. Wyrysowana zostaje wówczas proporcja chorych do liczby mieszkańców w poszczególnych gminach. Przykładowy wynik przedstawia poniższa mapa.
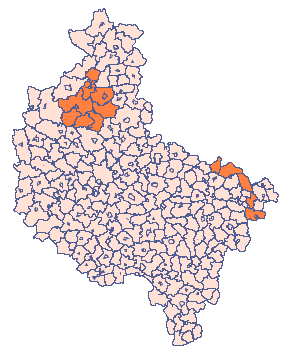
[Ad 2.]
W arkuszu „Klastery” podano, podobnie jak w poprzednim zadaniu, liczność dla populacji badanej. Tym razem oczekujemy wyższej częstości w niektórych gminach (wskazanych na mapie) więc dodatkowo w kolejnej kolumnie arkusza przedstawiono wartość relatywnego ryzyka dla poszczególnych gmin ustawiając ją na 4, dla gmin zwiększonego ryzyka i 1 dla pozostałych gmin.
Odpowiednie próbkowanie wymaga od nas wybrania hipotezy alternatywnej HA (poprzez wybranie kolumny z relatywnym ryzykiem) i zmiennej populacji (poprzez wskazanie kolumny z licznością populacji gmin). Wylosowane na podstawie tych założeń dane przedstawiono w pierwszej kolumnie nowego arkusza danych.
By móc obserwować rozkład współczynnika, przy założeniu większego ryzyka we wskazanych gminach, należy przekopiować uzyskany wynik do arkusza „Klastery” kolumny „S1”. Formuła znajdująca się w kolumnie 7 zostanie wówczas ponownie przeliczona. Na mapie przedstawiamy uzyskany wynik przy pomocy menagera Map z menu Analiza przestrzenna. Wyrysowana zostaje wówczas proporcja chorych do liczby mieszkańców w poszczególnych gminach. Przykładowy wynik przedstawia poniższa mapa.